Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
Opus 4.8 Max와 Kimi-K2.7-Code Thinking 모델의 코딩 성능을 '이상한 끌개' 시각화 과제를 통해 비교 분석한 벤치마크 결과입니다. Opus 4.8 Max는 수치적 안정성, 메모리 관리, 성능 및 코드 아키텍처 측면에서 Kimi 모델보다 우수한 성능을 보였습니다.
AI 추론 성능을 결정하는 핵심 요소로 코어 수보다 메모리 대역폭과 통합 RAM의 중요성을 분석합니다. 특히 단일 스트림 디코딩 시 메모리 바운드 특성과 MoE 모델에서의 연산 바운드 변화를 비교 설명합니다.
Nvidia DGX Spark, Strix Halo, M5 Max 환경에서 다양한 GPU 라이브러리와 양자화 포맷을 활용한 LLM 추론 성능을 비교 분석합니다. 각 하드웨어별 지원 포맷과 토큰 생성 속도(tok/s) 데이터를 제공합니다.

GPU 라이브러리 지원과 VRAM 사용량에 따른 파인튜닝의 기술적 한계를 분석합니다. 특히 AMD 및 MLX 환경에서의 VRAM 부족 문제와 대역폭 병목 현상을 다루며, Nvidia의 고대역폭 솔루션이 가진 강점을 설명합니다.

저장소 인식(Repo-aware) 기능을 갖춘 상세 계획 플러그인인 CursorQB가 출시되었습니다. Markdown 기반의 계획 수립과 검증 과정을 통해 긴 작업 시 문맥 이탈을 방지하고 안정적인 개발 워크플로우를 제공합니다.

본 글은 TTS 모델, 금융/법률 및 사이버 보안 특화 LLM 등 다양한 AI 결과물들을 소개합니다. 터키어에 특화된 TTS 모델과 전문 분야별 LLM 개발을 통해 시스템 구성의 성과를 보여줍니다.

Hugging Face 모델 ID를 받아 자동으로 다운로드하고, 이를 4대의 DGX Spark 클러스터에 분산하여 서비스하는 관리 도구를 설계했습니다. 이 도구는 vLLM/Ray 기반의 분산 추론을 통해 대규모 MoE 모델(예: Qwen3.5-397B)을 효율적으로 실행하며, 통합된 상태 모니터링 및 성능 테스트 기능을 제공합니다.

NVIDIA의 Nemotron-3-Ultra 모델과 4x DGX Spark (430 GB Vram) 조합의 성능을 언급하며, 토큰/초(tok/sec) 향상에 대한 계획을 공유하고 있습니다. 또한, 개발 도구를 오픈소스로 공개할 예정임을 밝히고 있습니다.
제시된 도구를 두 가지 기능으로 분리하여, 계획(planning) 단계와 코딩(coding) 단계를 전문화한 파이프라인을 구축할 계획입니다. 구체적으로 Kimi-K2.6과 Minimax M3/GLM5.2/Kimi-K2.7-Coder를 연결하여 깊이 있는 구현을 목표로 합니다.
오랫동안 개발해 온 Codex 및 Cursor용 Planning 플러그인 프로젝트가 마침내 공개되었습니다. 이 플러그인은 강력하고 상세한 계획 구조를 제공하며, 사용자들의 피드백을 받아 개선될 예정입니다.

CodexQB는 리포지토리 전체의 맥락을 인식하여 계획 플러그인을 개발한 스킬입니다. 이 도구는 기존 레포를 읽고 질문하며, 메인 계획과 단계별 하위 계획, QA 감사 문서를 생성합니다. 특히 '게이트 구현' 프롬프트를 통해 검토가 완료된 경우에만 실제 코딩을 진행하도록 통제하여 컨텍스트 드리프트를 방지합니다.

이스라엘 가자 지구의 실향민 휴대폰 위치 데이터(geolocation data)를 '패닉 임프린트'라고 부르며, 이 데이터를 활용해 고스트레스 환경에서 혼란을 관리하는 AI 에이전트를 개발했습니다. 이 AI는 영국 NHS에 10억 파운드에 판매되어 대량 사상자 발생 시 의료진의 패닉 관리를 돕는 도구로 재활용되었습니다.

오픈 소스 에이전틱 사이버 보안 모델인 Titus-35B-A3B를 Hugging Face Space의 ZeroGPU 환경에서 테스트할 수 있게 되었습니다. 이 모델은 Qwen3.6-35B-A3B를 파인튜닝하여 제작되었으며, 특히 에이전틱 작업과 도구 사용 능력에 강점을 보입니다.
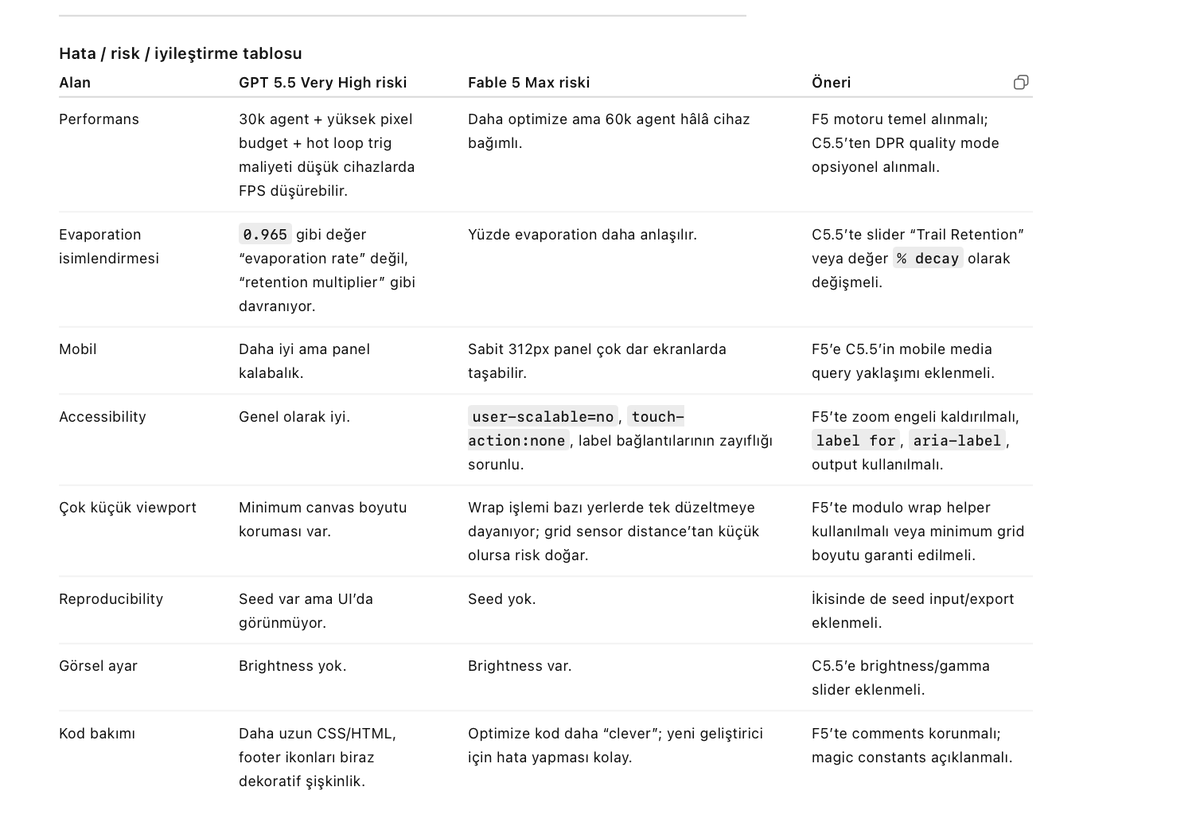
Fable 5와 GPT 5.5 모델 간의 케이스 스터디를 통해 도출된 오류, 리스크 및 개선 사항을 비교 분석한 테이블입니다.
Physarum 시뮬레이션 시나리오를 통해 Cursor Fable 5 Max와 Codex GPT 5.5 Very High의 성능을 비교했습니다. Fable 5는 고도의 알고리즘 최적화와 엔지니어링 측면에서, GPT 5.5는 시각적 완성도와 제품화 역량에서 각각 우위를 보였습니다.
Fable 5 Max와 GPT 5.5 Very High의 알고리즘 최적화 방식 차이를 비교합니다. Fable 5는 LUT와 분리 가능한 블러를 통해 성능을 극대화한 반면, GPT 5.5는 상대적으로 단순한 연산 방식을 사용합니다.

Fable 5와 GPT 5.5의 성능 비교를 바탕으로 Cursor와 같은 IDE 환경에서의 단계별 모델 활용 가이드를 제안합니다. 프로젝트의 초기 검토부터 계획 수립, 실행, 최종 리뷰까지 각 단계에 최적화된 모델 조합을 상세히 설명합니다.

Qwen3.6-35B-A3B를 기반으로 한 오픈 소스 터키어 금융 추론 모델 Mihenk-LLM v2가 공개되었습니다. 터키 금융 시장, 거시경제, 암호화폐 및 리스크 관리 등 특화된 금융 데이터로 SFT를 거쳤습니다.

Trendyol에서 새로운 TTS(Text-to-Speech) 모델인 Trendyol-TTS를 Hugging Face를 통해 공개했습니다. 사용자들이 직접 모델을 테스트해 볼 수 있도록 전용 Space 환경도 함께 구축되었습니다.

Gemma 4 31B 모델에 MTP(Multi-Token Prediction) 방식을 적용하여 vLLM 서버의 추론 속도를 약 2배 향상시킨 프로젝트입니다. FastAPI를 활용해 OpenAI 및 Anthropic 호환 API와 인증, 속도 제한 등의 게이트웨이 기능을 포함하도록 설계되었습니다.