AI 에이전트가 직접 호출하는 로컬 영상/음성 문서화 도구 v2t 배포
2026년 4월 16일200#AI #DevOps #CLI +7

영상/음성 파일을 문서화하는 도구를 하나 만들었다.
v2t (Video-to-Text Converter). 전부 내 PC에서 돌아가고, 무료고, CLI/MCP로 AI 에이전트가 직접 호출할 수 있다.
## 왜 만들었나
유튜브, 강의 녹화, 회의, 스트리밍 VOD — 영상 포맷 안에 잠긴 정보가 너무 많다. 이게 텍스트로 바뀌기만 하면 AI한테 요약시키든 검색하든 RAG에 넣든 뭐든 할 수 있다.
그래서 생각은 이랬다:
영상 데이터를 자동으로 문서화할 수 있으면, 그걸 AI와 묶을 수 있으면, 훨씬 더 많은 양질의 데이터를 얻을 수 있지 않을까.
근데 이 파이프라인을 만들려고 하면 보통 이렇게 된다:
- Whisper API 쓰면 → 1시간 영상당 $0.36, 한 달 쓰면 꽤 나감 + 데이터 외부 전송
- 오픈소스 faster-whisper → 무료지만 CLI로 수동 실행 + 결과 SRT를 외부 에디터에서 고치고 → AI한테 먹이려면 또 변환
- 구글/네이버 API → 월 제한 + 유료 + 민감한 내용 부담
돈 최대한 덜 쓰고, 사실상 무료로 돌릴 수 있는 파이프라인이 필요했다. 그리고 핵심 포인트 하나:
CLI로든, MCP 서버로든, 프로그램을 AI가 직접 쓸 수 있어야 했다.
Claude Code 같은 에이전트한테 "이 녹화본 요약해줘" 했을 때, 걔가 v2t를 MCP 툴로 호출해서 전사하고, 결과를 받아서 요약하는 흐름. 사람이 중간에 끼지 않아도 되는 형태.
그렇게 만들어진 게 해당 툴
## 뭐 하는 도구냐
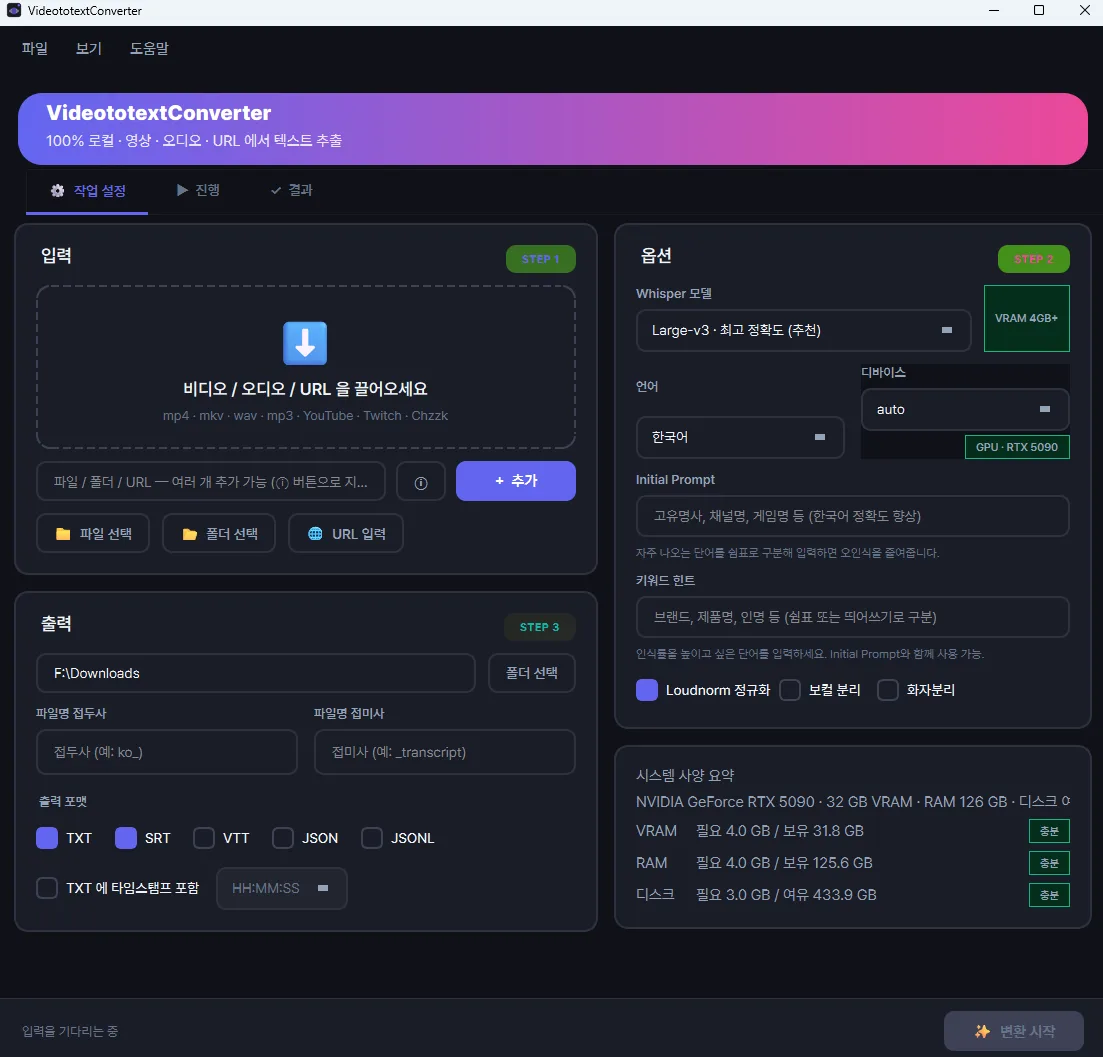
한 줄 요약: "영상 파일 → 자막 파일 + AI가 먹기 좋은 JSON".
파이프라인:
```
입력(파일/URL) → ffmpeg 오디오 추출 → (선택) 보컬 분리
→ Whisper 전사 → (선택) 화자 분리 → SRT/VTT/TXT/JSON/JSONL
```
지원하는 입력:
- 로컬 MP4/MP3/WAV/M4A 등 ffmpeg 디코딩 가능한 건 전부
- YouTube / Twitch / 치지직 / 숲 URL (yt-dlp로 오디오만 다운)
- 폴더 드래그 — 안에 든 영상들이 전부 큐로
출력도 여러 형식:
- SRT / VTT — 영상 편집기에 바로 쓰는 자막
- TXT — 타임스탬프 유무 선택
- JSON / JSONL — word-level 타임스탬프까지, AI가 파싱하기 좋음
### 전부 로컬
외부 서버로 데이터가 한 줄도 안 나간다. 네트워크 요청은 세 가지뿐:
- 첫 실행 시 Whisper 모델 다운로드 (HuggingFace, 1회성)
- 업데이트 확인
- URL 입력한 경우만 해당 플랫폼에서 오디오
회의 녹음, 비공개 강의, 인터뷰 — 어디에도 올리면 안 되는 자료를 안심하고 돌릴 수 있다. 이게 Whisper API 안 쓰는 가장 큰 이유.
### AI가 직접 쓸 수 있음 — CLI / MCP 서버
같은 코어를 3중 인터페이스가 공유한다:
- v2t-gui.exe — 드래그앤드롭 GUI (평소 사용)
- v2t.exe — CLI --json 옵션 있음, 종료 코드 명시적) — 자동화 스크립트에서 호출
- v2t-mcp.exe — MCP 서버 — AI 에이전트에서 직접 호출
원래 목적 — "영상 데이터를 자동 문서화해서 AI 파이프라인에 태운다" — 이걸 실제로 돌릴 수 있게 된 게 이 인터페이스 덕분이다.
## 기술 스택에서 고민한 것들
배포 파일을 줄이기 위해 여러 계략을 펼쳤다.
### PyTorch 대신 CTranslate2
Whisper 돌리는 흔한 방법이 PyTorch인데, 혼자서 2GB 먹는다. 인스톨러 용량이 터짐.
CTranslate2는 Whisper 추론에 필요한 것만 C++로 구현한 라이브러리라 400MB면 충분하고 속도도 빠름. 이거 선택하면서 CPU-only 인스톨러가 180MB로 들어갔다.
### CUDA DLL 온디맨드
cuBLAS/cuDNN을 번들하면 인스톨러가 1GB 된다. CPU 전용 사용자한텐 낭비.
→ CPU 전용 인스톨러(180MB)로 배포 + GPU 감지되면 companion venv에 NVIDIA 패키지를 자동 다운로드 (1GB, 1회). CPU 사용자는 추가 다운로드 없고, GPU 사용자는 한 번만 기다림.
### PySide6 수동 pruning
PyInstaller에 PySide6 전체 넣으면 QtWebEngine, QtMultimedia 같은 안 쓰는 모듈 125개가 따라옴. spec 파일에서 exclude해서 용량을 절반으로 줄였다.
## 앞으로
원래 목적인 "영상 → 자동 문서화 → AI 파이프라인" 을 완성시키기 위한 다음 단계들.
LLM 후처리: Ollama 로컬 LLM 연동해서 오탈자 교정/요약/번역까지 v2t 안에서. 여전히 클라우드 API는 안 씀. 전사 → 교정 → 요약/번역이 한 창에서 끝남.
영상 스크래핑: 특정 주제에 대한 영상 리서치, 조사 기능
내가 필요해서 만든 도구인데, 쓸수록 "데이터를 내 통제 아래 두면서 AI 파이프라인에 태울 수 있다" 라는 감각이 좋다. 클라우드 API에 의존하지 않고, 내 PC에서 내 데이터로 내가 원하는 만큼 돌릴 수 있다는 것.
- 레포: [GitLab (공개)](https://gitlab.molayo.synology.me/videototextconverter)
- 다운로드: [Releases](https://gitlab.molayo.synology.me/videototextconverter/-/releases)
- 현재 버전: v0.9.0 (2026-04-16)
쓰고 싶은 사람 누구든 써도 되고, 기여/피드백도 환영.
---
#v2t #Whisper #faster-whisper #PySide6 #로컬STT #자막편집기 #MCP #AI #개인프로젝트
태그
#AI#DevOps#CLI#Whisper#로컬STT#자동화#개인프로젝트#Tech#개발일지#인프라
관련 포스트
Tech 카테고리의 다른 글
