RamaLama: 컨테이너 기반 워크플로우를 통한 AI 모델 서비스 간소화
요약
RamaLama는 컨테이너 기반 워크플로우를 통해 AI 모델 서비스의 환경 전환 비용을 최소화하는 도구입니다. 로컬 실험부터 프로덕션 배포까지 동일한 컨테이너 사고 체계로 통합하여 재현 가능한 추론 서비스를 제공합니다.
핵심 포인트
- 컨테이너화를 통한 로컬 및 프로덕션 환경 통합
- 다양한 추론 백엔드 간의 전환 비용 절감
- Podman 및 컨테이너 워크플로우와 밀접한 연동
- MLOps 및 플랫폼 엔지니어링을 위한 재현성 확보
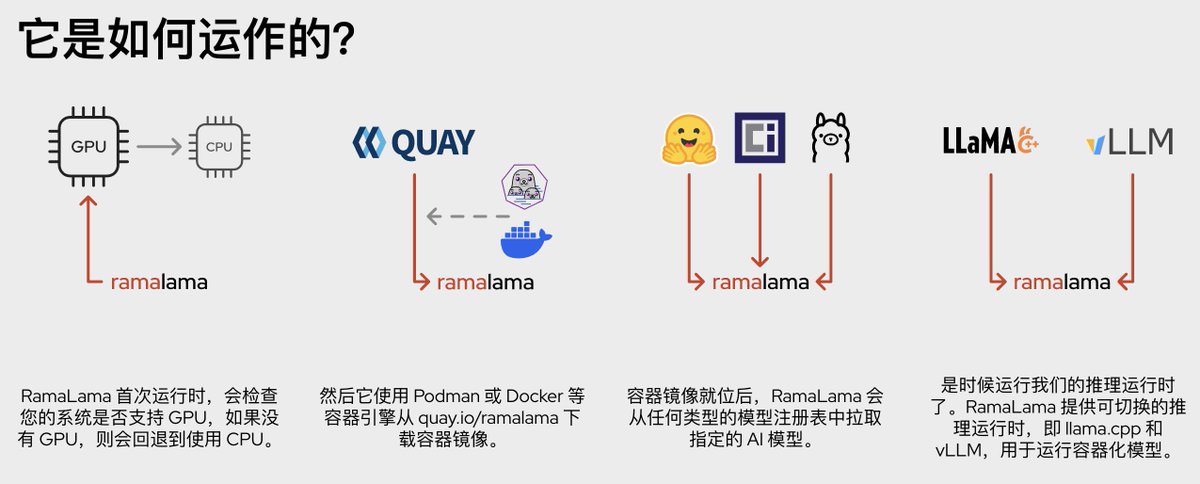
로컬에서 모델을 실행할 때 가장 번거로운 점은 백엔드(Backend)가 너무 많다는 것입니다: llama.cpp, vLLM, 서로 다른 그래픽 카드(GPU), 서로 다른 파라미터(Parameter)마다 각기 다른 세트가 필요합니다. 서버나 내부망 환경으로 이전하려고 하면 의존성(Dependency)을 다시 정리해야 합니다. RamaLama의 아이디어는 모델 서비스를 컨테이너화(Containerization)된 워크플로우(Workflow)에 넣어 환경 전환 비용을 줄이는 것입니다.
GitHub:
https://
github.com/containers/ram
alama
...
이것은 컨테이너 언어를 사용하여 AI 모델 서비스를 단순화하며, 로컬 실험, 컨테이너화된 실행, 그리고 프로덕션 배포(Production Deployment)를 동일한 사고 체계 안에 통합합니다. 개인 개발자에게는 설치 및 실행 비용을 낮춰주며, 플랫폼 팀에게는 재현 가능한 추론(Inference) 서비스의 래퍼(Wrapper) 계층과 같은 역할을 합니다.
핵심 하이라이트:
- 로컬 및 프로덕션 환경을 대상으로 하는 모델 서비스
- 컨테이너(Container) / Podman 워크플로우와 밀접하게 연동
- 서로 다른 추론 백엔드(Inference Backend) 간의 전환 비용 절감
- 기업 내부망, 서버, 로컬 LLM 시나리오에 적합
- 모델 실행 환경을 더욱 재현 가능하게 만드는 데 용이
로컬 LLM 사용자, MLOps, 플랫폼 엔지니어링(Platform Engineering) 팀이 연구하기에 적합합니다.
제가 Quark Cloud Disk를 통해 「AI 전체 공략집(지속 업데이트 중)」을 공유해 드렸습니다.
https://
pan.quark.cn/s/c7b6691bdf5d
많은 팀이 에이전트(Agent) 데모를 빠르게 구축하기 위해 TS/Node를 사용하지만, 그다음 단계에서 종종 막히곤 합니다: 오케스트레이션(Orchestration), 디버깅(Debugging), 평가(Evaluation), 그리고 배포(Deployment)가 각각 별도의 예시를 가지고 있어, 최종적으로 팀의 장기적인 유지보수로 넘기기가 어렵습니다. Google의 TypeScript용 ADK
AI 자동 생성 콘텐츠
본 콘텐츠는 X @wsl8297 (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기