
Imec의 2026 로드맵: 2038년까지 0.3nm 노드 상세 계획, 0.7nm에서 CFET 트랜지스터 실용화 — 셀 크기가 밀도에
요약
Imec이 발표한 차세대 반도체 공정 로드맵에 따르면, 2038년까지 0.3nm(3Å) 공정 기술을 목표로 하고 있습니다. 스케일링 한계를 극복하기 위해 CFET 트랜지스터와 Hyper-NA EUV 노광 시스템 같은 혁신적인 기술 도입이 필수적임을 강조합니다.
핵심 포인트
- 2038년까지 0.3nm급 제조 기술 구현 계획
- 2030년 A10 단계에서 CPP 스케일링 정체 예상
- CFET 트랜지스터 및 Hyper-NA EUV 기술 채택 필요성
- TSMC, Intel 등 주요 기업의 공정 주기와 연계된 로드맵
Imec의 반도체 공정 기술 로드맵은 산업 발전의 일반적인 방향을 설정하며, 향후 수십 년 동안 이 분야가 직면하게 될 과제들을 보여줍니다. 이 로드맵은 Imec이 TSMC, Intel, Nvidia, AMD, Samsung, ASML 등 여러 업계 거물들과 협력하여 연구 개발할 차세대 주요 공정 노드 및 트랜지스터 아키텍처(transistor architectures)의 타임라인에 대한 아이디어를 제공합니다.
Imec의 최신 생산 노드 로드맵에 따르면, 이 국제 연구 개발 기관은 2038년까지 3 옹스트롬(angstrom)급(0.3nm) 제조 기술을 구상하고 있으나, 컨택 폴리 피치(CPP, contact poly pitch)는 2030년 A10 단계에서 스케일링(scaling)이 멈출 것으로 예상합니다. Imec에게 무어의 법칙(Moore's Law)이 그리 낙관적이지 않을 수도 있지만, 스케일링을 지속하기 위해 칩 제조사는 CFET 트랜지스터 및 Hyper-NA EUV 노광 시스템 (Hyper-NA EUV Lithography systems)과 같은 새로운 기술을 채택해야 할 것입니다.
GAA 트랜지스터에게 남은 시간은 7년
반도체 생산이 실질적으로 더 복잡해짐에 따라, 칩 제조사들은 더 이상 몇 년마다 완전히 새로운 공정 기술을 도입하지 않습니다. 대신, 이들은 일반적으로 3년마다 새로운 노드 세대를 출시하며, 그 사이에는 매년 점진적인 개선 사항을 도입합니다. TSMC는 2023년에 N3B 생산을 확대했고, 이어 2024년에 N3E, 2025년에 N3P를 선보였습니다. Intel은 2024년 20A(취소됨), 2025년 18A, 그리고 2027년 18A-P를 통해 동일한 패턴을 따를 계획이었습니다.
imec의 로드맵에 따르면, 차세대 공정 기술은 이와 유사한 주기로 계속해서 등장할 것입니다.
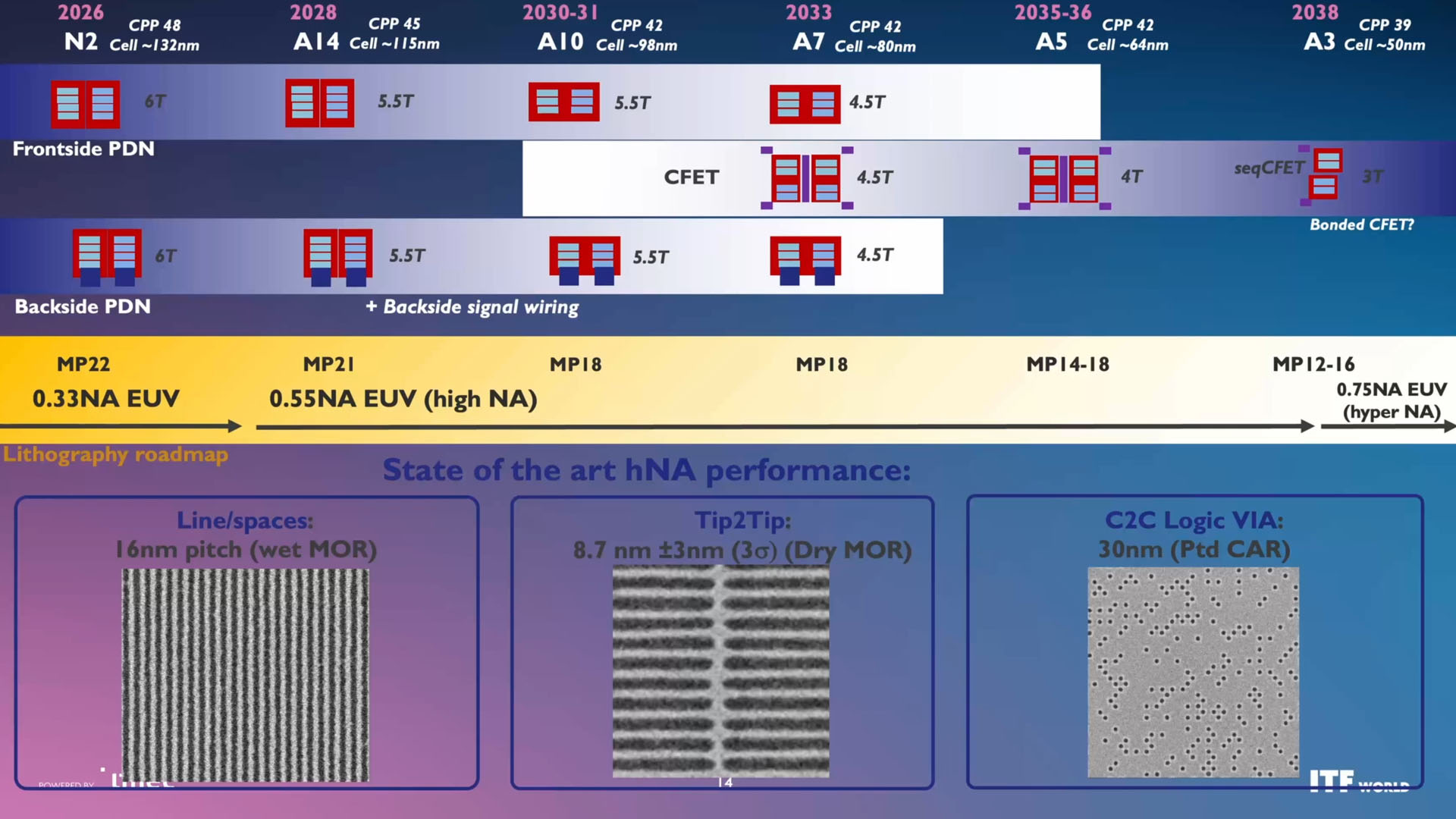
(이미지 출처: Imec)
Interuniversity Microelectronics Centre (imec)는 현재 우리가 약 48nm의 컨택트 폴리 피치 (CPP, Contact Poly Pitch), 약 132nm의 셀 높이 (Cell Height), 그리고 6개의 메탈 트랙 (Metal Tracks)을 갖춘 2nm급 (N2) 시대에 살고 있다고 간주합니다. 하지만 실제 상황은 조금 다를 수 있습니다. Intel의 18A는 50nm의 CPP와 160nm (고밀도, High Density) 또는 190nm (고성능, High Performance)의 셀 높이를 가지는 반면, TSMC의 N3는 45nm의 CPP를 자랑할 수 있기 때문입니다. N2 (또는 원한다면 18A) 이후에는 향후 몇 년 안에 성능과 효율이 강화된 버전이 뒤따를 것이며, 이는 최근 몇 년간 업계가 운영되어 온 방식과 일치합니다.
"물론, 우리는 로직 로드맵 (Logic Roadmap)을 N2 너머의 차세대 단계로 확장할 것입니다."라고 imec의 R&D 부사장인 Julien Ryckaert는 말했습니다. "아시다시피, 2nm에서는 이미 나노시트 (Nanosheet) 시대라는 새로운 기술 소자 패러다임으로 도약했으며, 이는 우리를 옹스트롬 (Angstrom) 노드로 깊숙이 인도할 것입니다."
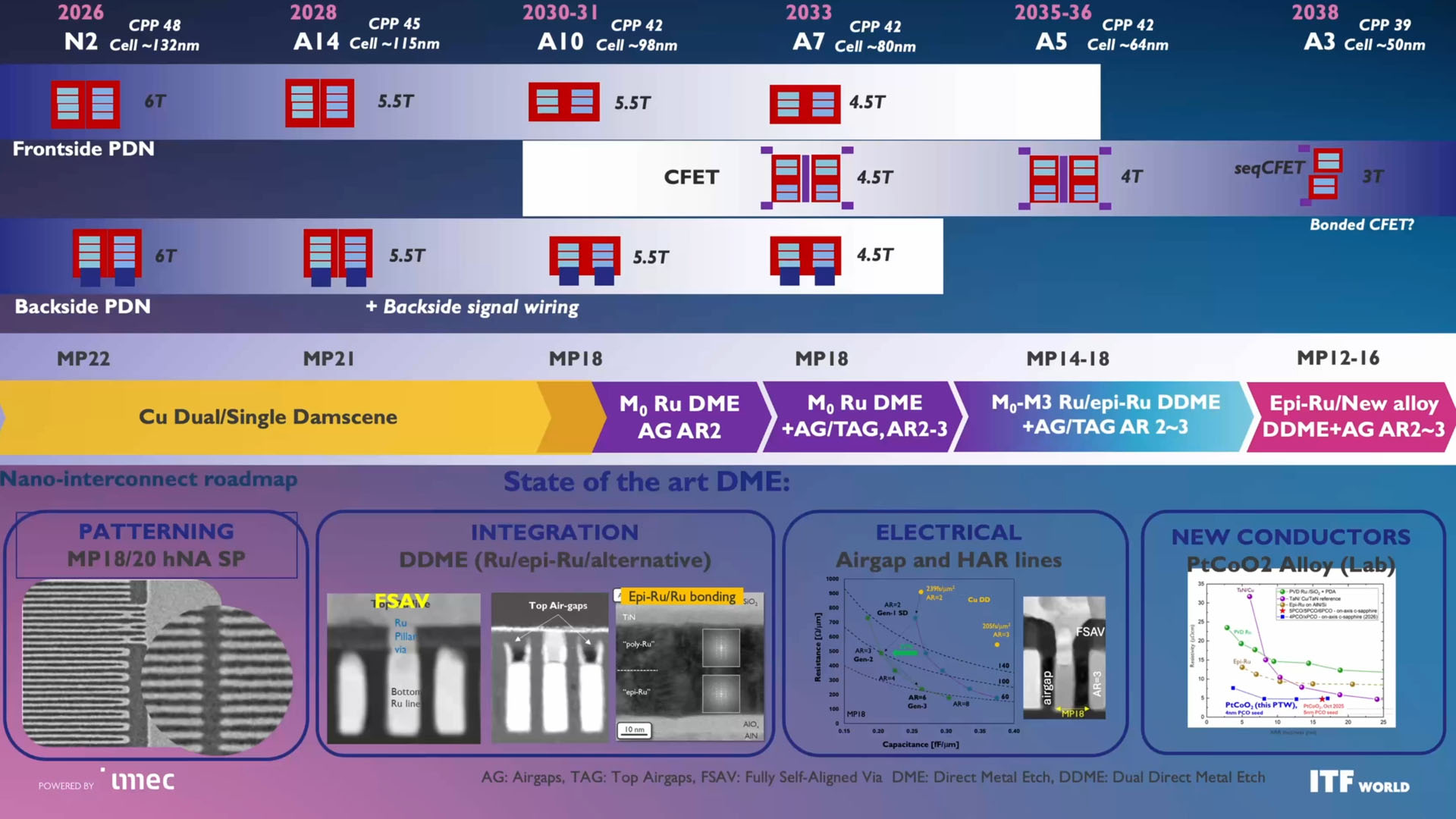
(이미지 출처: Imec)
Imec은 A14급 기술이 2028년에 등장할 것으로 예상합니다. TSMC는 2028년 하반기에 A14를 사용하여 대량 생산(high-volume manufacturing)을 시작할 것으로 예상하므로, 실제 양산(ramp)은 2029년에 이루어질 것입니다. Intel의 14A 역시 동일한 패턴을 따릅니다. A14를 통해 imec은 CPP(Contacted Poly Pitch)가 45nm로 축소되고, 셀 높이(cell height)가 115nm 및 5.5 메탈 트랙(metal tracks)으로 감소할 것으로 전망합니다. 2030~2031년경, imec은 42nm CPP와 98nm 셀 높이를 가진 A10급 기술 — 즉 1nm급 기술 — 을 예상하며, 이는 여전히 5.5-트랙 아키텍처에 의존할 것입니다.
게이트 올 어라운드 (GAA) 트랜지스터 기반 노드는 기존의 전면 전력 공급 네트워크(frontside power delivery networks) 또는 후면 전력 공급(backside power delivery) 방식으로 구현될 수 있다는 점은 주목할 만합니다. 이는 많은 애플리케이션이 후면 전력 공급(BSPDN)으로부터 즉각적인 이득을 얻지 못하기 때문에, BSPDN이 모든 응용 분야에서 즉시 필수 요소가 되지는 않을 것이라는 imec과 TSMC의 공통된 믿음을 반영합니다.
또한 imec은 A14 단계에서 High-NA EUV 장비의 도입을 예상하고 있는데, 이는 Intel의 계획과는 일치하지만 TSMC의 계획과는 일치하지 않는다는 점도 언급할 가치가 있습니다.
2030년대 초반의 CFET 도입
로드맵은 imec이 2033년에 등장할 것으로 예상하는 A7 세대에서 특히 흥미로워집니다. CPP는 42nm로 유지되지만, 셀 높이는 약 80nm로 떨어지며, 표준 셀(standard-cell) 아키텍처는 4.5 트랙으로 이동합니다. 더 중요한 것은, A7이 CFET가 생산 도입을 위한 진지한 후보로 부상하는 시점이라는 것입니다. CFET는 n형 및 p형 트랜지스터를 나란히 배치하는 대신 수직으로 쌓아 올림으로써, 트랜지스터 스케일링(scaling)에 세 번째 차원을 추가합니다.
Imec의 로드맵은 CFET를 A7의 선두 주자로 명시적으로 자리매김하고 있으며, 이는 해당 조직이 기존의 나노시트 (nanosheet) 아키텍처가 2030년대 초반에 실질적인 스케일링 (scaling) 한계에 도달할 것으로 보고 있음을 의미합니다. 하지만 A7의 CPP (Contacted Poly Pitch)가 A10에서 변하지 않기 때문에, 칩 제조사들이 A7에서 완전히 새로운 트랜지스터 아키텍처를 채택할지 여부는 불투명할 수 있습니다. 또한, imec은 CFET를 위해 BSPDN (Backside Power Delivery Network)을 필수적인 요소로 고려하고 있는 것으로 보입니다.
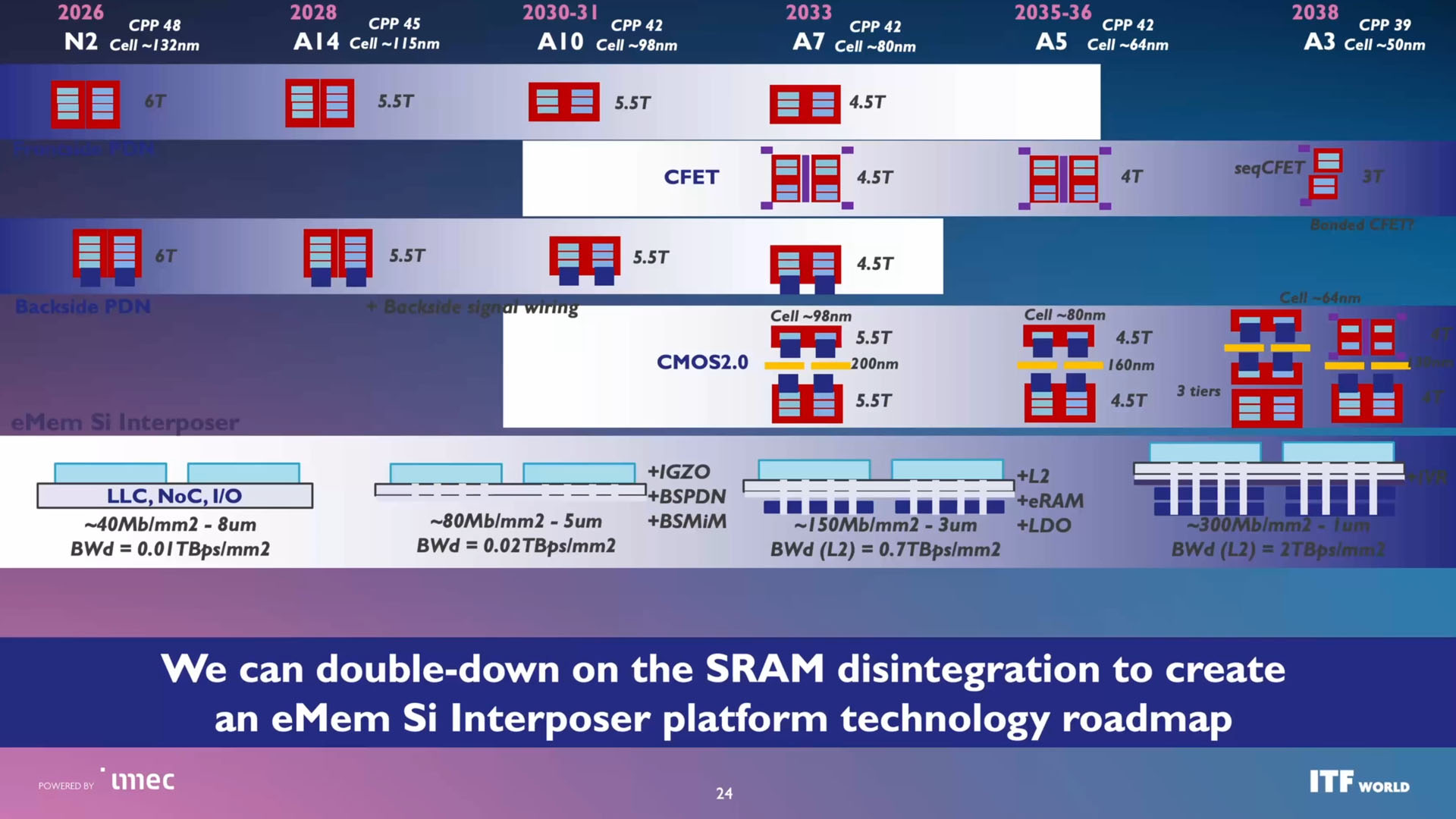
(Image credit: Imec)
"나노시트의 네 번째 세대인 7옹스트롬(A7) 세대로 넘어가면서, 우리는 기존의 나노시트 소자 기술을 스케일링하는 데 있어 점점 더 많은 도전에 직면하고 있습니다"라고 Ryckaert는 말했습니다. "이전 발표에서도 이미 언급한 경쟁자가 있는데, 바로 CFET가 다음 세대 트랜지스터를 위한 솔루션으로 부상하기 시작할 수 있는 후보입니다."
A7 이후의 로드맵은 CFET의 진화에 달려 있는 것으로 보입니다. 2035~2036년에 예상되는 A5 세대는 42nm CPP를 유지하지만, 4-트랙 (4-track) 라이브러리를 사용하여 셀 높이 (cell height)를 약 64nm로 줄입니다. 2038년까지 로드맵은 39nm CPP와 50nm 셀 높이를 가진 A3에 도달합니다. 이 시점에서 imec은 순차적 CFET 구현과 더 나아가 수직 통합 (vertical integration)을 더욱 활용하는 본딩 (bonded) CFET 구조를 구상하고 있습니다. 사실, 수직 통합은 우리가 무어의 법칙 (Moore's Law)의 진화를 바라봐야 할 새로운 방식인 것으로 보입니다. 한편, imec에 따르면 39nm CPP와 50nm 셀 높이에 도달하기 위해 칩 제조사들은 Hyper-NA EUV 리소그래피 (lithography) 스캐너를 사용해야 할 수도 있습니다.
무어의 법칙 재정의

(Image credit: Imec)
Imec 로드맵에서 가장 흥미로운 점은 그것이 본질적으로 무어의 법칙이 무엇을 의미하는지를 재정의한다는 것입니다. 전통적으로 우리는 무어의 법칙을 특정 크기의 칩에 있는 트랜지스터의 수가 작아짐에 따라 18~24개월마다 두 배로 증가한다는 관찰 결과로 간주해 왔습니다.
Imec이 A10부터 A5에 이르기까지 CPP(Contacted Poly Pitch)가 42nm에서 정체되어 있음을 보여주는 사실은, 전통적인 트랜지스터 스케일링(scaling)이 한계에 다다랐음을 거의 인정하는 것과 다름없으며, 향후 밀도 이득은 반드시 수직 통합(vertical integration)을 통해 얻어야 한다는 것을 의미합니다. Imec의 로드맵에서 트랜지스터는 여전히 더 조밀해지고 있지만, 이는 개별 트랜지스터가 수십 년 전과 같은 속도로 축소되기 때문이 아니라, 서로 다른 트랜지스터 아키텍처(architecture), 3D 통합(3D integration), 또는 후면 전력 공급(backside power delivery) 덕분에 칩 설계자들이 주어진 면적에 더 많은 로직 게이트(logic gates)를 배치할 수 있기 때문입니다.
그 결과, 향후 몇 년 동안 우리는 게이트 피치(gate pitch)나 개별 트랜지스터가 몇 나노미터인지보다는 표준 셀(standard cell)의 크기에 더 주목하게 될 수도 있습니다. 결국 AMD, Intel 또는 Nvidia와 같은 기업들이 칩을 설계할 때, 개별 트랜지스터를 배치하는 것이 아니라 표준 셀로 구축된 실제 블록(blocks)을 배치하기 때문입니다. 하지만 표준 셀의 크기를 계산하는 것은 복잡합니다. 셀 높이(cell height)는 고정되어 있지만, 너비(width)는 고정되지 않고 실제 기능에 따라 달라지기 때문입니다.
라이브러리 높이(Library height) × CPP는 특정 표준 셀의 크기가 아닙니다. 이는 표준 셀 라이브러리의 근본적인 풋프린트 단위(footprint unit)이며, 로직 밀도(logic density)를 나타내는 널리 사용되는 대리 지표(proxy)입니다. 실제 표준 셀은 해당 높이를 갖지만, 너비는 기능에 따라 달라집니다. 대신 업계에서는 설계자들이 사용하는 로직 빌딩 블록(logic building blocks)의 실제 풋프린트를 측정하는 로직 셀 면적(logic cell area, 표준 셀 풋프린트) — 즉, 셀 높이(Cell Height) × CPP — 와 같은 지표를 사용하며, 이는 단순히 개별 트랜지스터의 치수만을 측정하는 것이 아닙니다.
N2에서의 6-트랙(6-track) 셀에서 A3에서의 3-트랙(3-track) 셀로의 전환은, 향후 밀도 이득이 트랜지스터 피치(transistor pitch)를 줄이는 것만큼이나 표준 셀 높이를 줄이는 것에 얼마나 크게 의존할 것인지를 잘 보여줍니다. 결과적으로 CPP 축소가 수년간 정체될 것으로 예상됨에도 불구하고, 로직 셀 면적은 감소할 예정입니다. 설계자들은 미래 노드에서 트랜지스터 밀도 이득을 추출할 수 있을 것이며, 이는 무어의 법칙(Moore's Law)이 여전히 유효함을 증명할 것입니다.
이종 대규모 통합(Heterogeneous Large-Scale Integration) × 교차 기술 공동 최적화(Cross-Technology Co-Optimization)
반도체 산업이 이미 겪고 있는 모든 변화와 앞으로 다가올 변화를 고려할 때, imec은 이 분야가 이질적 대규모 집적 (Heterogeneous Large-Scale Integration, HLSI)이라 부르는 새로운 시대에 진입하고 있다고 믿습니다. 이 개념은 발전이 주로 트랜지스터의 진화와 트랜지스터 밀도 증가에 의존했던 전통적인 VLSI 스케일링(scaling)에서 벗어나, 단일 컴퓨팅 플랫폼 내에 여러 기술을 결합하는 모델로의 전환을 반영합니다.
imec의 예측에 따르면, 미래의 시스템은 첨단 3D 및 3D + 2.5D 패키징 기술을 사용하여 로직(logic), 메모리(memory), 전력 공급 회로(power-delivery circuitry), 그리고 광학 I/O(optical I/O)의 이질적 집적(heterogeneous integration)에 의존하게 될 것입니다. 물론, imec은 AI 워크로드가 반도체 수요의 주요 동력이 될 것으로 예상하므로, 컴퓨팅 아키텍처와 반도체 산업 모두 AI 애플리케이션의 요구 사항을 충족하는 방향으로 진화할 것으로 기대됩니다.
"우리가 AI 중심 아키텍처로 더 깊이 들어감에 따라, 기술이 제공하는 이질성(heterogeneity)에 더욱 집중해야 할 것이며, 이는 아마도 VLSI 패러다임을 HLSI 패러다임인 이질적 대규모 집적(Heterogeneous Large Scale Integration)으로 이동시킬 것입니다."라고 Ryckaert는 말했습니다.
개별 구성 요소를 고립되어 개발하기보다 시스템 수준에서 미래 플랫폼을 최적화하기 위해, imec은 HLSI 비전의 필수적인 부분으로 볼 수 있는 교차 기술 공동 최적화 (Cross-Technology Co-Optimization, XTCO) 프레임워크를 구축했습니다. XTCO는 로직, 메모리, 상호 연결(interconnects), 전력 공급(power delivery), 냉각(cooling), 그리고 패키징의 개발을 결합하도록 설계되었으며, 컴퓨팅 밀도(compute density), 에너지 효율(energy efficiency), 열 성능(thermal performance), 그리고 메모리와 같은 주요 시스템 지표에 미치는 영향을 평가합니다.
로직 공정 기술(logic process technologies)은 파운드리(foundries)에서 개발되고, 메모리 기술(memory technologies)은 DRAM 제조사에서 설계되는 반면, 냉각(cooling)은 CoolIt이나 Frore Systems와 같은 제3자 업체에서 개발된다는 사실을 고려할 때, 이것이 실제로 어떻게 작동할지는 아직 지켜봐야 합니다.
전력 및 냉각 (Power and cooling)
개별 칩의 밀도가 높아지고 전력 소모가 커짐에 따라, 전력 공급(power delivery)은 결정적인 병목 현상(bottleneck)이 될 것으로 보입니다. 이것이 바로 Intel, Samsung, TSMC와 같은 모든 선도적인 칩 제조사들이 후면 전력 공급(backside power delivery) 기술과 통합 전압 조절기(integrated voltage regulators, IVRs)를 구현하고 있거나 구현할 예정인 이유입니다.
Imec은 미래의 AI 가속기(AI accelerators)와 CPU가 손실을 줄이고 효율성을 높이기 위해 BSPDN, IVR, 임베디드 커패시터(embedded capacitors), 그리고 첨단 전력 반도체(advanced power semiconductors)의 조합에 의존할 것으로 예상합니다. 시간이 지남에 따라, 트랜지스터에 더 깨끗한 전력을 직접 전달하기 위해 더 많은 전력 변환 단계(power-conversion stages)가 랙(racks)과 메인보드(motherboards)에서 패키지(packages) 자체로 이동할 것으로 전망됩니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Tom's Hardware의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기