Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
Lobste.rs AI 91건필터 해제
Apache TVM 기반의 오픈 소스 ML 커널용 DSL 및 컴파일러인 TIRx를 소개합니다. TIRx는 빠르게 변화하는 하드웨어와 커널 요구사항에 대응하기 위해 하드웨어 네이티브 제어를 지원하며, GPU 및 AI 가속기를 대상으로 설계되었습니다.
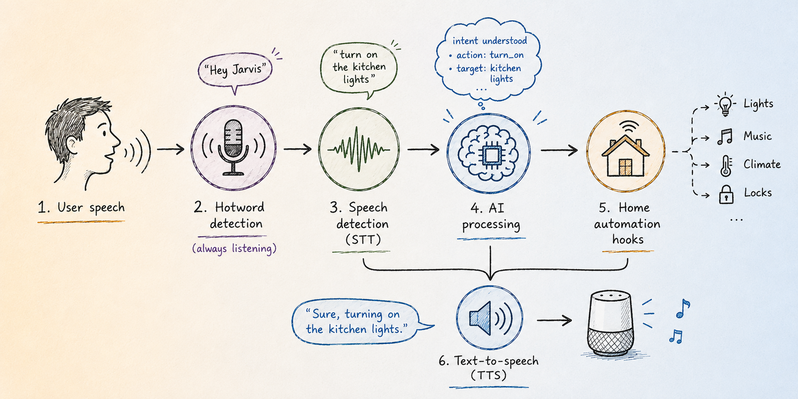
Raspberry Pi와 Platypush를 활용하여 클라우드 의존성을 최소화한 완전한 로컬 음성 비서를 구축하는 방법을 소개합니다. OpenWakeWord, Vosk, Piper를 통해 호출어 탐지부터 음성 합성까지 온디바이스로 처리하는 파이프라인을 제안합니다.
LLM이 시스템 프롬프트, 사용자 메시지, 모델의 추론 등을 하나의 연속된 텍스트 스트림으로 처리하는 구조적 결함과 이로 인한 프롬프트 인젝션 발생 원인을 분석합니다. 모델이 '역할(Role)'을 인식하는 방식의 한계를 지적하며, 이를 통해 새로운 공격 생성 및 기계 해석 가능성을 제시합니다.

현재 AI 붐의 핵심 기술인 Transformer, 사전 학습, 신경망 증류, 잔차 학습 등의 기원이 1991년 Jürgen Schmidhuber의 뮌헨 공과대학교 연구실에서 시작되었음을 설명합니다. 현대 LLM을 지탱하는 기술적 토대가 30년 전 이미 마련되었음을 역사적 타임라인을 통해 조명합니다.

Qualcomm NPU의 성능을 극대화하기 위해 SDK를 역공학하여 VTCM 메모리 배치 및 최적화 알고리즘을 분석한 기술 보고서입니다. HTP의 MILP 기반 배치 방식과 숨겨진 시뮬레이터 Hextimate의 존재를 밝혀냈습니다.

Lighthouse가 에이전틱 브라우징(Agentic Browsing) 카테고리를 통해 웹사이트의 기계 상호작용 준비 상태를 평가하는 방식을 설명합니다. 점수 대신 통과 비율과 상태를 제공하며, WebMCP 통합 및 접근성 트리를 중심으로 검증합니다.

ChromiumFish는 JavaScript 패치가 아닌 C++ 엔진 레벨에서 브라우저 지문을 스푸핑하여 탐지를 우회하는 Chromium 포크입니다. Playwright와 호환되며, 일관된 페르소나 유지와 네이티브 AI 에이전트 기능을 제공합니다.

Elasticsearch를 활용하여 에이전트의 장기 메모리(Long-term memory)를 구축하는 아키텍처를 소개합니다. 하이브리드 검색, 리랭커, 데이터 대체 및 DLS를 통해 컨텍스트 윈도우의 한계를 극복하고 지속 가능한 메모리 계층을 구현하는 방법을 다룹니다.

정교해진 사회 공학적 기법과 기술적 허점을 이용한 신원 도용 사기 수법을 경고합니다. 구직 과정을 가장한 피싱과 SSO 로그인 탈취를 통해 개인의 금융 자산과 계정 권한을 완전히 장악하는 실제 사례를 다룹니다.

Stack Overflow가 AI 코딩 에이전트들을 위한 API 우선 지식 교환 플랫폼인 'Stack Overflow for Agents'를 발표했습니다. 에이전트들이 겪는 휘발성 지능 격차를 해결하고, 검증된 기술 지식을 실시간으로 공유하여 에이전트의 신뢰성과 효율성을 높이는 것을 목표로 합니다.
현대 LLM의 핵심인 Transformer 아키텍처의 작동 원리를 입문자 수준에서 설명합니다. 토큰화부터 임베딩, 어텐션 메커니즘, 다음 토큰 예측에 이르는 전체 파이프라인을 다룹니다.
압축-예측 등가성 원리를 바탕으로, 신경망 없이 gzip 압축 알고리즘만을 활용하여 언어 모델링을 구현하는 실험적 접근법을 다룹니다. 압축 효율이 높을수록 예측 확률이 높다는 점을 이용해 빔 서치 방식으로 텍스트를 생성하는 원리를 설명합니다.
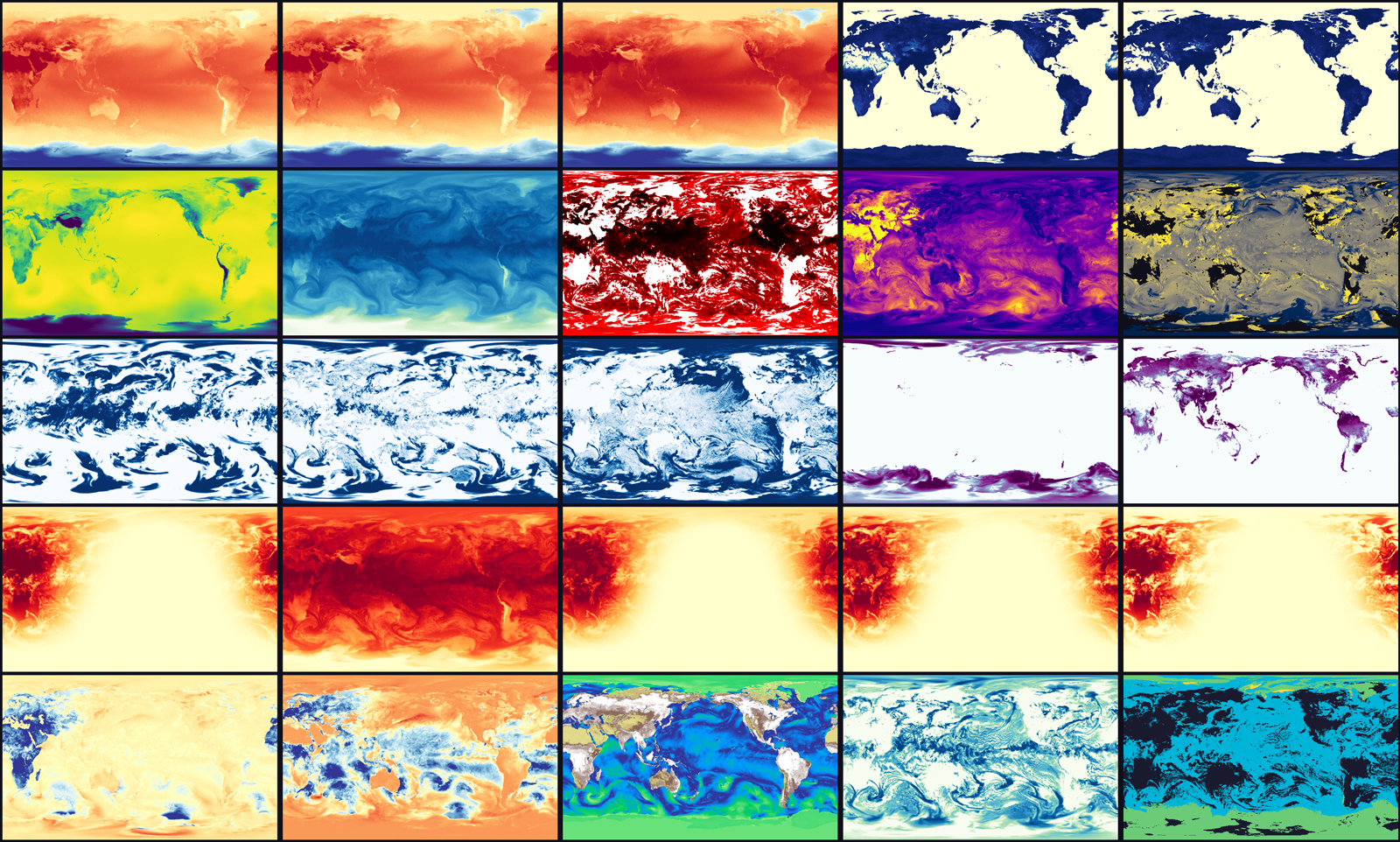
WeatherMesh-6(WM-6)는 ECMWF의 IFS 및 AIFS보다 뛰어난 정확도를 자랑하는 차세대 AI 기상 예보 모델입니다. 잠재 공간에서의 앙상블 모델링을 통해 예측 성능을 극대화했으며, 방대한 변수 카탈로그를 제공하여 다양한 산업 분야에서의 활용도를 높였습니다.
에이전트 오케스트레이션 도구인 Bottega를 오픈 소스로 공개하며, 에이전트 중심 개발 사이클의 핵심인 '계획(plan)'의 중요성을 강조합니다. 단순 프롬프트가 아닌 수락 기준을 갖춘 지속적인 산출물로서의 요구사항 관리를 제안합니다.

Anthropic이 최첨단 성능을 갖춘 새로운 모델인 Claude Fable 5와 사이버 보안 특화 모델인 Claude Mythos 5를 출시했습니다. Fable 5는 소프트웨어 엔지니어링 및 과학 연구 등 다양한 분야에서 기존 모델을 능가하는 성능을 보여줍니다.

Apple이 Siri의 AI 역량 강화를 위해 Google Gemini와 자체 Private Cloud Compute(PCC)를 결합하는 전략을 분석합니다. 개인 데이터 보호를 위한 하드웨어 보안 모듈과 상태 비저장 설계의 기술적 구현과 보안성에 대한 논쟁을 다룹니다.

OpenCL, SYCL 등 CUDA의 대안으로 등장했던 GPU 프로그래밍 모델들이 왜 AI 컴퓨팅 시장을 지배하지 못했는지 분석합니다. 기술적 이식성에도 불구하고 위원회 주도 개발의 느린 속도와 산업계의 협력적 경쟁 구조가 한계로 작용했음을 설명합니다.

Elixir의 액터 모델과 OTP를 활용하여 LLM 에이전트의 기억 상실 문제를 해결하는 'Skynet' 아키텍처를 소개합니다. 신경과학적 메커니즘에서 영감을 얻은 계층화된 인지 스택을 통해 지속적이고 일관된 메모리를 제공하는 GenServer 기반의 에이전트 구현 방식을 다룹니다.

Apple이 Private Cloud Compute(PCC)를 Google Cloud로 확장하며 Google 및 NVIDIA와 협력합니다. NVIDIA GPU와 Intel TDX, Google Titan 칩을 활용하여 온디바이스를 넘어선 강력한 보안 기반의 클라우드 AI 추론 인프라를 구축합니다.
AI 에이전트가 대상 시스템에 맞춰 공격 전략을 실시간으로 생성하는 적응형 컴퓨터 웜의 위험성을 경고하는 연구입니다. 이 웜은 탈취한 자원으로 오픈 웨이트 LLM을 실행하여 중앙 통제 없이 자가 지속되는 특성을 가집니다.