Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
Lobste.rs AI 91건필터 해제
Deepseek-OCR을 발전시킨 새로운 OCR 모델인 Unlimited-OCR을 소개합니다. 이 모델은 원샷 롱-호라이즌(One-shot Long-horizon) 성능을 목표로 하며, vLLM 및 SGLang을 통한 추론과 Baidu Cloud 배포를 지원합니다.
Anthropic의 최신 모델에서 도구 호출(tool calling) 성능이 오히려 퇴보하는 현상이 관찰되었습니다. 이는 모델이 특정 Claude Code 하네스를 통해 강화학습되면서, 도구 선언의 미세한 차이에 민감하게 반응하는 오류를 유발하는 것으로 분석됩니다.

1956년 AT&T가 벨 연구소의 방대한 특허를 시장에 개방하기로 결정한 역사적 사건을 다룹니다. 독점 규제와 지적 재산권의 공공성, 그리고 기업의 수직적 통합 제한이 산업 생태계에 미친 영향을 분석합니다.
StoryScope는 AI 생성 소설과 인간의 소설을 구분하기 위해 스타일이 아닌 담론 수준의 서사적 특징을 분석하는 파이프라인을 제안합니다. 캐릭터의 주체성이나 시간적 복잡성 등 10가지 차원의 서사적 특징을 통해 AI와 인간의 창작물 차이를 정밀하게 식별합니다.
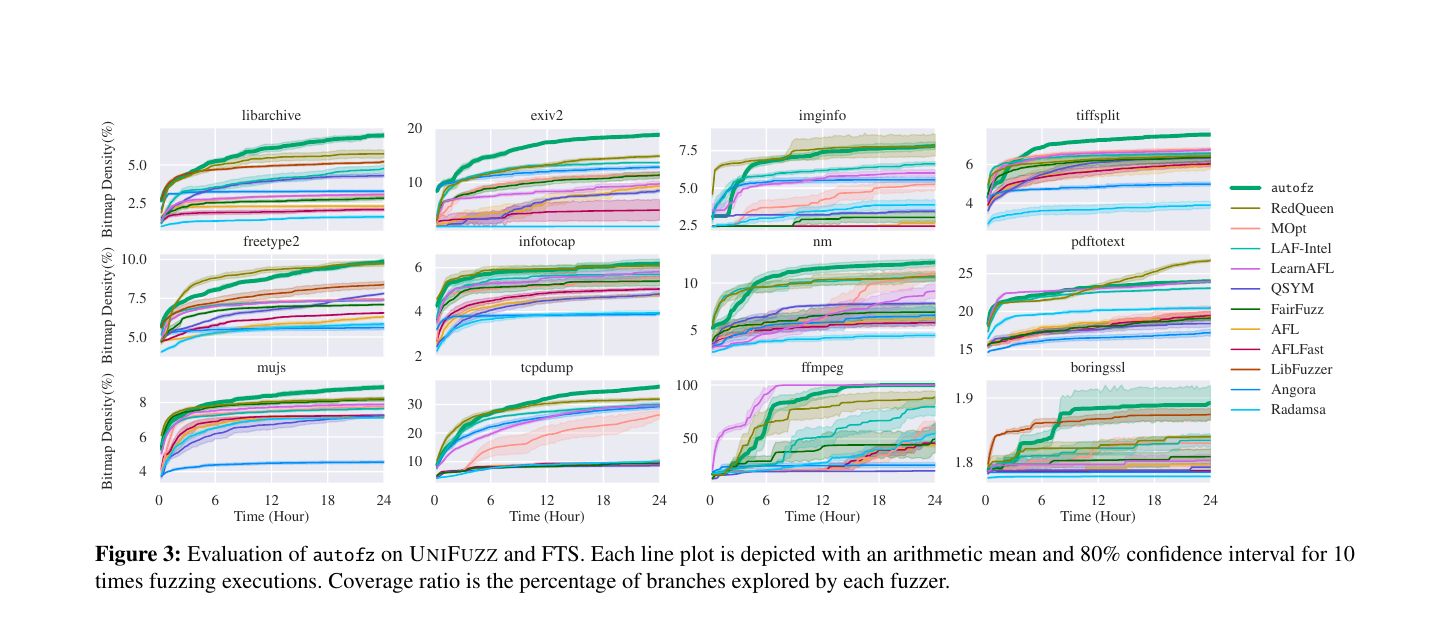
메타 퍼저 autofz의 제어 평면(control-plane) 프레임워크를 통해 LLM 에이전트 시스템의 오케스트레이션 문제를 고찰합니다. 불완전한 작업자들 사이에서 예산을 효율적으로 배분하고 최적의 작업을 선택하는 제어 평면의 중요성을 강조합니다.

순환 신경망(RNN)의 연상 회상 능력을 향상시키기 위해 mLSTM 메모리 행렬에 직교화(Orthogonalization)를 적용하는 연구를 소개합니다. Muon 옵티마이저의 아이디어를 차용하여 노이즈가 있는 환경에서도 약한 기억이 소실되지 않도록 개선하는 방법을 다룹니다.
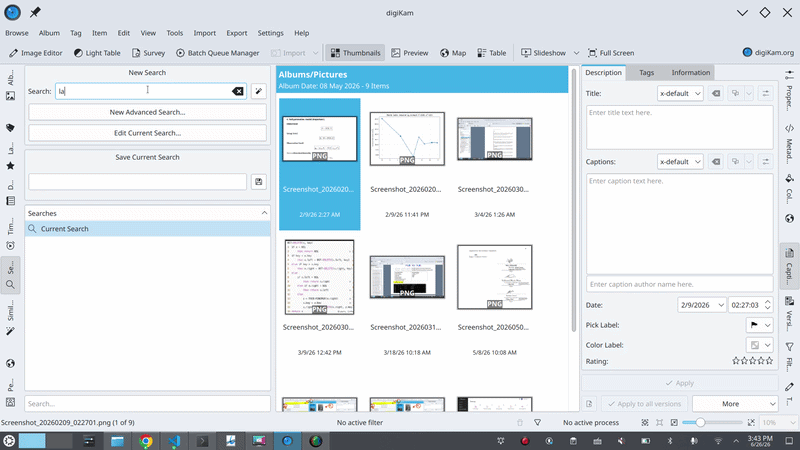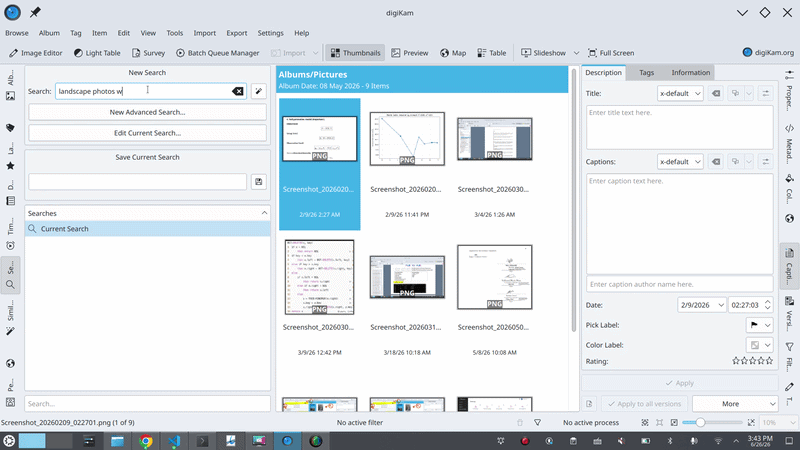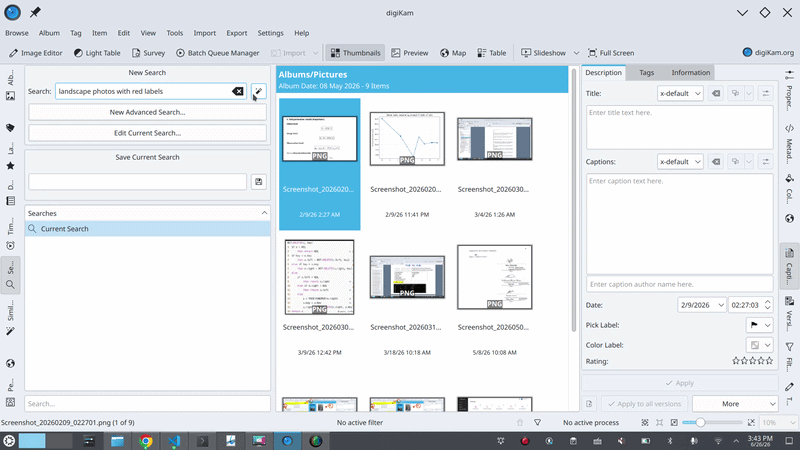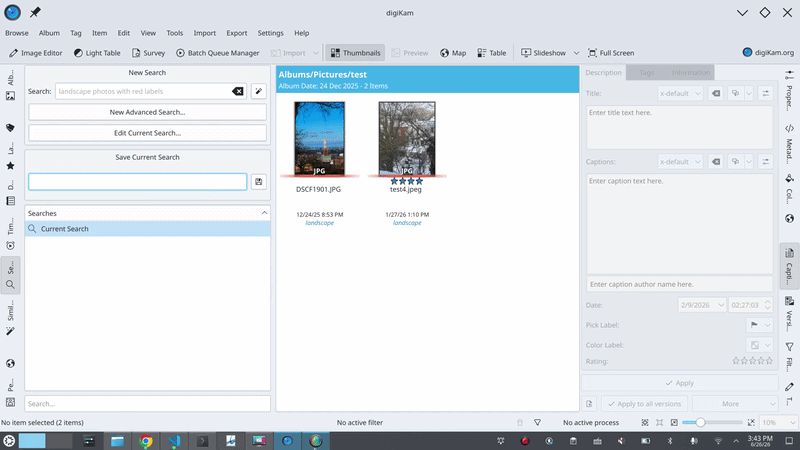
GSoC 프로젝트의 일환으로 digiKam에 로컬 LLM을 통합하여 자연어 기반 사진 검색 기능을 구현하는 설계 과정을 소개합니다. LLM이 직접 데이터를 검색하는 대신 사용자의 자연어 의도를 구조화된 쿼리로 번역하는 '번역가' 역할을 수행하도록 설계되었습니다.

NVIDIA Jetson Orin Nano를 활용하여 Kokoro-82M 모델 기반의 로컬 TTS 서비스를 구축하는 방법을 소개합니다. Durable Streams 방식을 통해 추론 과정 중 생성되는 오디오를 실시간으로 스트리밍하여 사용자 경험을 개선하는 아키텍처를 제안합니다.

Google DeepMind 연구원이 개인 자격으로 작성한 글로, Google의 미 국방부 계약과 관련하여 실질적인 AI 거버넌스의 부재를 비판합니다. 단순한 윤리적 선언을 넘어 독립적인 감독과 투명성, 책임성을 갖춘 강력한 거버넌스 체계가 필요함을 강조합니다.

정치적 목적을 가진 스팸 챗봇 'Emma'의 사례를 통해 LLM 기반의 자동화된 정치 홍보 활동을 분석합니다. Clock Tower X LLC와 Havas Media의 연관성을 추적하며, AI 챗봇 기술이 정치적 영향력 행사에 어떻게 활용되는지 다룹니다.

Zhipu AI의 오픈 웨이트 모델인 GLM 5.2가 보안 취약점 탐지 벤치마크인 IDOR 테스트에서 Claude Code를 능가하는 성능을 보였습니다. GLM 5.2는 MoE 구조를 통해 효율적인 추론 비용을 유지하며, 대규모 컨텍스트 처리 능력을 바탕으로 코딩 및 보안 작업에서 강력한 성능을 입증했습니다.

MAX 모델을 Apple silicon GPU에서 실행할 수 있는 기능이 26.4 릴리스를 통해 지원됩니다. M1부터 M5까지의 칩셋에서 LLM, 비전, 이미지 확산 모델을 구동할 수 있으며, 특히 M5 시스템의 Neural Accelerators를 활용해 최적의 성능을 제공합니다.

Princeton 연구진이 강화학습과 확산 모델을 활용해 복잡한 무선 주파수 집적 회로(RFIC)를 설계하는 기술을 개발했습니다. 이 방식은 기존의 수동 설계 방식보다 훨씬 빠르게 혁신적인 레이아웃을 생성하며 설계 시간을 획기적으로 단축합니다.
Transformer 아키텍처와 하이브리드 모델 간의 성능을 토큰 수준에서 비교 분석한 연구입니다. 모델의 효율성과 연산 특성을 심층적으로 다룹니다.
GPT2-BASIC은 DOS급 저사양 환경에서도 실행 가능한 BASIC 언어 기반의 고정 소수점 트랜스포머 런타임입니다. 양자화와 정수 산술을 활용하여 현대적 LLM의 핵심 알고리즘을 하드웨어 제약이 심한 시스템에서도 구현할 수 있음을 증명합니다.
LLM의 추론 능력을 활용하여 네트워크 취약점에 실시간으로 적응하고 스스로 확산하는 '적응형 컴퓨터 웜'에 관한 연구입니다. 오픈 웨이트 모델을 사용하여 중앙 집중식 AI 안전 제어를 우회하며, 감염된 기기의 자원을 기생적으로 활용해 자율적인 공격을 수행합니다.

위성 군집과 로켓 발사가 성층권 오존층 및 지구 온난화에 미치는 영향을 다룬 연구들을 소개합니다. 로켓 배출물과 우주선 재진입 시 발생하는 금속 입자가 대기 화학에 미치는 잠재적 위험성을 경고합니다.
Fastly는 경제학의 지니 계수를 활용하여 에지(Edge) 인프라의 용량 계획을 수립합니다. 트래픽 불평등도를 핵심 신호로 사용하여 대규모 이벤트나 급격한 워크로드 변화에 대응하는 효율적인 용량 모델을 구축했습니다.
3B 파라미터 규모의 소형 언어 모델인 VibeThinker-3B를 소개하며, 검증 가능한 추론 성능을 극대화하는 최적화 파이프라인을 제안합니다. 실험 결과, 이 모델은 대규모 플래그십 모델들과 대등한 수준의 추론 및 코딩 성능을 보여주었습니다.
LLM 추론 시 발생하는 커널 실행 오버헤드와 동적 형상 처리 문제를 해결하기 위한 'Event Tensor' 컴파일러 추상화를 제안합니다. 타일링된 작업 간 의존성을 인코딩하여 동적 특성을 지원하며, 최첨단 LLM 서빙 지연 시간을 달성합니다.