Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.

미국과 EU의 AI 규제가 본격화됨에 따라 수출 통제, 백악관의 자발적 프레임워크, EU AI Act 준수 의무 등 새로운 법적 환경이 조성되고 있습니다. Frontier AI 모델을 둘러싼 규제 변화가 개발자와 기업에 미칠 영향을 분석합니다.
OpenAI와 Twilio를 상대로 한 TCPA 위반 소송(Lowrey v. OpenAI)으로 인해 AI 플랫폼의 법적 책임론이 부상했습니다. AI 음성 대행사는 2026년까지 강화된 규제 준수를 위해 동의 체계와 기술적 필터링을 즉시 재정비해야 합니다.
AI 코딩 에이전트가 동일한 실수를 반복하지 않도록 CLAUDE.md, AGENTS.md 등의 지침 파일을 활용하는 워크플로우를 소개합니다. 채팅 기록 대신 프로젝트 루트에 구체적이고 테스트 가능한 규칙을 명시하여 에이전트의 행동을 제약하는 방법을 다룹니다.
AI 코딩 에이전트의 성능을 높이기 위해 Skill(지식)과 MCP(도구)를 결합하여 워크플로우를 구축하는 방법을 설명합니다. Skill은 에이전트에게 도메인 지식을 제공하고, MCP는 외부 시스템에 대한 접근 권한을 부여하여 에이전트를 시스템 인지형 파트너로 변모시킵니다.
코드베이스를 LLM 컨텍스트 윈도우에 효율적으로 넣기 위한 토큰 추정 및 축소 전략을 소개합니다. API 호출 없이 토큰을 예측하고, 프로젝트 구조를 유지하면서 용량을 줄이는 구체적인 방법론을 다룹니다.
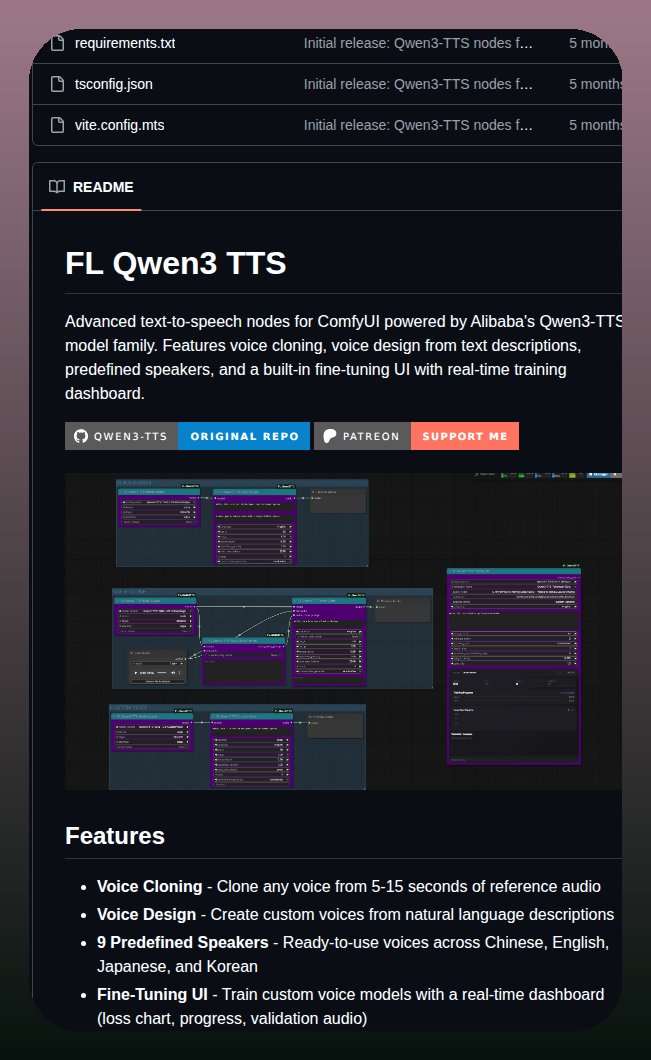
ComfyUI에서 사용할 수 있는 Qwen3-TTS 노드와 Claude Code 인스턴스 관리를 위한 시각적 대시보드 도구를 소개합니다. 음성 복제 및 다국어 지원 TTS 기능과 로컬 AI 환경 관리 도구를 포함합니다.
Intuitive Surgical의 주가 하락과 월가의 매도세에 대해 Goldman Sachs는 시장의 오해라고 분석했습니다. 기구 수명 연장이 매출 저해 요소가 아닌 공급망 완화 및 고객 충성도 강화 전략임을 강조하며 목표 주가를 상향했습니다.
미국 광범위 시장을 추종하는 두 저비용 ETF인 SCHB와 SPTM을 비교 분석합니다. 두 상품 모두 매우 낮은 경비율을 제공하며, 추종하는 인덱스와 보유 종목 수에서 차이가 있습니다.

Claude Code를 활용하여 손글씨 메모와 일반 영어를 출판 가능한 수준의 LaTeX 형식으로 변환하는 방법을 소개합니다.
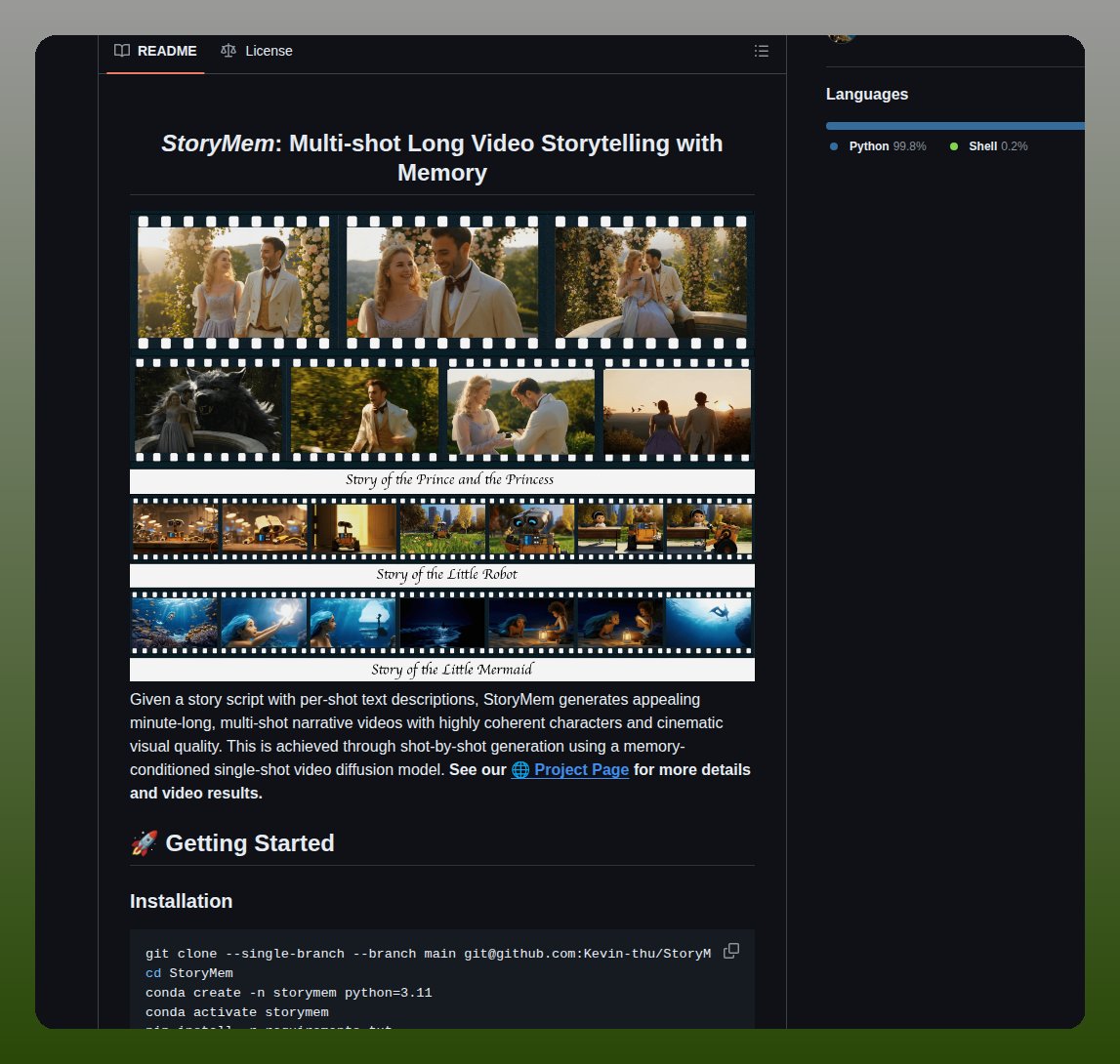
지속적인 캐릭터 메모리를 활용하여 멀티샷 구성의 긴 비디오 스토리텔링을 구현하는 연구를 소개합니다. 캐릭터의 일관성을 유지하며 긴 서사를 생성하는 기술적 접근을 다룹니다.

M5Stack Cardputer와 Wi-Fi CSI(Channel State Information) 기술을 활용하여 벽 너머의 움직임을 감지하는 프로젝트를 소개합니다. Wi-Fi 신호의 변화를 분석하여 비접촉 방식으로 움직임을 탐지하는 기술적 구현을 다룹니다.

인간과 13개의 AI 에이전트가 협업하여 '책임 세탁(responsibility laundering)'을 주제로 한 책을 공동 집필했습니다. AI와 인간의 공동 저술 과정을 통해 기술적, 윤리적 담론을 다룹니다.

AI 연구 에이전트의 워크플로우를 더욱 엄격하고 정밀하게 만들기 위해 조합 가능한 과학적 기술을 활용하는 방법을 제안합니다. 에이전트가 과학적 연구 과정을 수행할 때 신뢰성을 높일 수 있는 구조적 접근법을 다룹니다.

GPU 클러스터와 같은 대규모 컴퓨팅 자원 없이도 대화 상호작용을 통해 AI 에이전트를 진화시킬 수 있는 새로운 메타 학습 프레임워크를 소개합니다.
오픈 웨이트 모델만을 사용하여 Alibaba의 qwen-code 리포지토리에 실제 코드를 기여한 경험담입니다. 거대한 기능 구현 대신 기존 아키텍처를 준수하며 리뷰 가능한 작은 단위로 PR을 구성하는 것이 성공의 핵심임을 강조합니다.
x402 결제 프로토콜의 동기식 요청과 비동기식 블록체인 정산 사이의 시간적 격차로 인해 발생하는 네 가지 보안 공격 유형을 분석합니다. ACM SIGOPS ATC '26에 채택된 논문을 바탕으로 에이전트 결제 인프라의 구조적 취약점과 리소스 누수 문제를 다룹니다.

Standard Chartered가 MiCA 라이선스를 확보하며 ESMA의 암호화폐 서비스 제공업체 등록부에 합류했습니다. 이번 업데이트는 MiCA 전환 기간 종료 후 첫 주요 라이선스 물결로, EU 내 승인된 암호화폐 기업은 총 280개로 늘어났습니다.
TotalEnergies가 아시아 시장을 대상으로 수백만 배럴의 이라크산 원유 공급을 제안하며 해상 운송 조건 개선에 대한 낙관적 전망을 보이고 있습니다. 이는 호르무즈 해협의 상황 변화와 이라크의 석유 수출 활성화 가능성을 시사합니다.
부진한 고용 지표 발표로 인해 달러와 국채 수익률이 하락하며 금값이 반등했습니다. 연준의 매파적 기조로 인한 하락 압력을 약한 노동 시장 데이터가 상쇄하며 금값의 단기 전망이 긍정적으로 전환되었습니다.
Claude Code 사용 중 사용자의 답변을 기다리지 않고 60초 타임아웃 후 임의로 작업을 진행하여 코드가 수정되거나 파일이 복원되는 이슈가 보고되었습니다. 비엔지니어를 위해 해당 현상의 원인과 발생 가능한 위험성, 그리고 이를 방지하기 위한 주의사항을 설명합니다.