프롬프트 최적화(Prompt Optimization) 탐구
요약
본 기사는 수동적인 시행착오 대신 체계적인 데이터 측정과 테스트를 통해 프롬프트를 개선하는 '프롬프트 최적화' 기술을 탐구합니다. 5가지 최적화 알고리즘과 5개의 데이터셋을 활용하여 GPT-4o, Claude-3.5-Sonnet, o1 모델의 성능을 벤치마킹한 결과를 다룹니다.
핵심 포인트
- 프롬프트 최적화에 가장 권장되는 모델은 o1보다 성능이 우수한 Claude-3.5-Sonnet입니다.
- 기반 모델의 도메인 지식이 부족한 작업에서 프롬프트 최적화의 효과가 가장 극대화됩니다.
- 적절한 최적화 적용 시 베이스라인 프롬프트 대비 정확도를 약 200% 향상시킬 수 있습니다.
- 테스트된 5가지 방식은 Few-shot prompting, Meta-prompting, Meta-prompting with reflection, Prompt gradients, Evolutionary optimization입니다.
Krish Maniar 및 William Fu-Hinthorn 작성
더 많은 프롬프트 최적화 기술의 베타 테스트에 관심이 있다면, 여기에서 관심 양식을 작성해 주세요.
우리가 프롬프트를 작성할 때, 우리는 LLM(Large Language Models)이 지저분한 데이터에 적용할 수 있도록 우리의 의도를 전달하려고 시도하지만, 한 번에 모든 뉘앙스를 효과적으로 전달하기란 어렵습니다. 프롬프팅(Prompting)은 일반적으로 결과가 더 나아질 때까지 테스트하고 수정하는 수동적인 시행착오를 통해 이루어집니다. 반면, DSPy 및 promptim과 같은 도구들은 실제 데이터에 대한 측정 및 테스트를 통해 의도와 지시 사이의 간극을 메움으로써, 프롬프트 "프로그래밍 (programming)"과 체계적인 프롬프트 최적화(prompt optimization)의 유용성을 보여주었습니다. 이 포스트에서 우리는 다음을 수행합니다:
- 프롬프트 최적화 벤치마킹을 위해 검증 가능한 결과가 포함된 5가지 서로 다른 데이터셋을 큐레이션합니다.
- 프롬프트를 체계적으로 개선하는 5가지 서로 다른 방법을 구현하고 벤치마킹합니다.
- 3가지 서로 다른 모델(
gpt-4o,claude-sonnet,o1)이 프롬프트 최적화에서 얼마나 잘 수행하는지 벤치마킹합니다.
우리의 결론:
프롬프트 최적화를 위해 우리가 권장하는 모델은 claude-sonnet 입니다 (o1 보다 우수)
프롬프트 최적화는 기반 모델(underlying model)이 도메인 지식(domain knowledge)이 부족한 작업에서 가장 효과적입니다
위와 같은 상황에서, 프롬프트 최적화는 단순한 베이스라인(baseline) 프롬프트 대비 정확도를 약 200% 향상시킬 수 있습니다
이러한 상황에서의 프롬프트 최적화는 데이터로부터 직접 적응하는 법을 배우는 일종의 장기 기억(long-term memory) 형태로 생각할 수 있습니다
우리가 테스트한 것
우리는 5가지 대중적인 프롬프트 최적화 접근 방식(자세한 설명은 뒤에 나옵니다)을 벤치마킹했습니다:
- Few-shot prompting (퓨샷 프롬프팅): 기대되는 동작의 예시로서 학습 데이터(training examples)를 사용함
- Meta-prompting (메타 프롬프팅): LLM을 사용하여 프롬프트를 분석하고 개선함
- Meta-prompting with reflection (성찰을 포함한 메타 프롬프팅): 업데이트된 프롬프트를 확정하기 전에 LLM이 스스로의 분석을 생각하고 비판하도록 함
- Prompt gradients (프롬프트 그래디언트): 각 예시에 대해 "텍스트 그래디언트 (text gradients)"로서 목표 지향적인 개선 권장 사항을 생성한 다음, 이를 별도의 LLM 호출에 적용함
- Evolutionary optimization (진화적 최적화): 통제된 변이(mutations)를 통해 프롬프트 공간을 탐색함
우리는 다음과 같은 주요 질문에 답하기 위해, 일반적인 작업들을 대표하는 5개의 데이터셋을 대상으로 3개의 모델(O1, GPT-4, Claude-3.5-Sonnet)에서 이 방식들을 실행했습니다:
- 프롬프트 최적화가 가장 효과적인 시점은 언제인가?
- 어떤 프론티어 모델(frontier models)이 프롬프트 최적화에 적합한가?
- 어떤 알고리즘이 가장 신뢰할 수 있는가?
알고리즘 (Algorithms)
우리는 프롬프트를 개선하는 각기 다른 이론을 가진 5가지 프롬프트 최적화 접근 방식을 테스트했습니다:
Few-shot prompting (퓨샷 프롬프팅)
테스트한 가장 단순한 기술로서, 우리는 학습 세트에서 최대 50개의 예시(몇 번의 에포크(epochs)에 걸쳐 샘플링됨)를 선택하여 기대되는 동작의 시연(demonstrations)으로서 프롬프트에 포함했습니다. 이는 (변경 사항을 제안하기 위해 LLM 호출이 필요하지 않으므로) 학습하기에는 효율적이지만, (일반적인 시연 데이터가 직접적인 단일 지시문보다 더 많은 콘텐츠를 포함하므로) 테스트 시점에 더 높은 토큰 비용이 발생합니다.
Meta-prompting (메타 프롬프팅)
이는 가장 단순한 인스트럭션 튜닝(instruction-tuning) 접근 방식이었습니다. 먼저 대상 LLM을 예시들에 대해 실행했습니다. 그런 다음 출력값에 대한 점수를 계산했습니다. 참고: 이 과정은 평가자(evaluator) 설정이 필요합니다. 그 다음 메타 프롬프팅 LLM에 입력값, 출력값, 참조 출력값(사용 가능한 경우), 그리고 해당 출력값들에 대한 현재 프롬프트의 점수 예시를 보여주었습니다. 이러한 변수들을 바탕으로, 우리는 LLM에게 더 나은 프롬프트를 작성하도록 요청했습니다. 우리는 이 과정을 미니 배치(mini-batches) 단위로 반복하며, 주기적으로 홀드아웃 개발(dev) 세트에서 평가를 수행합니다. 개발 세트 점수가 가장 높은 프롬프트가 유지됩니다.
Meta-prompting with reflection (성찰을 포함한 메타 프롬프팅)
첫 번째 단계에서 사용한 메타 프롬프팅 (meta-prompting) 기술을 재사용하되, LLM에게 "think" 및 "critique" 도구를 사용할 수 있는 옵션을 제공합니다. 이 도구들은 LLM이 특정 프롬프트 업데이트를 확정하기 전에 연습장 (scratchpad)에 생각을 적어볼 기회를 제공하는 것 이상의 역할은 하지 않습니다. 이는 LLM이 더 많은 테스트 시간 연산 (test-time compute)을 사용하여 이전 프롬프트들을 분석하고, 다음 프롬프트 업데이트를 결정하기 전에 기저의 데이터 분포 (data distribution)에서 더 숨겨진 패턴을 찾을 수 있도록 돕습니다.
프롬프트 그래디언트 (Prompt Gradients)
Pryzant 등이 작성한 "Automatic Prompt Optimization"과 같은 논문들을 통해 대중화된 이 접근 방식은 최적화를 더 작은 단계로 나눕니다:
- 현재 프롬프트의 출력값에 점수를 매깁니다.
- LLM을 사용하여 프롬프트가 실패한 각 사례에 대해 구체적인 피드백을 생성합니다 (이것이 "그래디언트 (gradients)"입니다).
- 수집된 이러한 "그래디언트"를 기반으로 프롬프트 업데이트를 제안합니다.
변경을 수행하기 전에 세밀한 피드백을 수집하는 것이 메타 프롬프팅 접근 방식보다 더 목표 지향적인 개선으로 이어진다는 것이 핵심 아이디어입니다.
진화적 최적화 (Evolutionary Optimization)
이 알고리즘들은 "세대 (generations)\
- 다양한 초기 프롬프트 생성 (일련의 학습 예시에 대해 기대되는 출력을 생성할 수 있는 지침을 추측한 뒤, 더 높은 다양성을 위해 이 프롬프트들을 의역(paraphrasing)함)
- 가장 성과가 좋은 프롬프트에 프롬프트 경사 (prompt gradients) 적용 (자세한 내용은 위의 프롬프트 경사 섹션 참조)
- 상위 5개의 성과를 낸 프롬프트를 의역을 통해 새로운 변형(variants) 생성
- 성공적인 프롬프트들을 결합하여 그들의 최상의 요소들을 포착. 이는 가장 이질적인 두 개 이상의 기존 프롬프트로부터 새로운 프롬프트를 생성합니다. 이는 기존 프롬프트를 증류(distilling)하거나 확장하는 데 집중하므로, 국소적 오류 (local errors)에 갇히는 것을 방지하고 추가적인 탐색을 장려합니다.
- 승자들에 대해 경사 최적화 (gradient optimization)를 반복하여 마무리.
이러한 유형의 접근 방식에 대한 가설은, LLM이 데이터를 전체적으로 충분히 분석하거나 다른 프롬프팅 기법을 적절히 탐색하지 않은 채, 관찰된 오류를 바탕으로 피상적인 수정만을 수행하며 정체되는 경향이 있다는 것입니다. 이론적으로 구조화된 프롬프트 진화 (structured prompt evolution)는 더 단순한 언덕 오르기 (hill-climbing) 방식에 비해 프로세스가 더 전역적으로 최적화된 솔루션 (globally optimal solution)을 찾도록 도울 수 있습니다.
데이터셋 (Datasets)
우리는 이를 벤치마크하기 위해 5개의 데이터셋을 생성했습니다.
Support email routing 3: 각 수신 이메일에 대해 3명의 담당자 중 올바른 담당자에게 라우팅(routing)합니다.
Support email routing 10: (1)과 동일하지만 10명의 가능한 담당자가 있습니다. 각 담당자의 "도메인 전문성 (domain expertise)"이 덜 뚜렷하기 때문에 이 작업은 더 어렵습니다.
Multilingual math: LLM에 수학 문장제 문제가 주어지면, 5개 언어 중 하나로 정확한 정답을 철자로 적어 응답해야 합니다. 언어는 문장제 문제의 주제나 테마에 의해 결정됩니다 (스포츠 -> 한국어, 우주 -> 아랍어, 요리 -> 독일어, 음악 -> 영어, 야생동물 -> 러시아어). 프롬프트(prompt)나 최적화 도구(optimizer) 모두 왜 특정 대상 언어가 선택되었는지 알지 못하므로, 최적화 도구는 데이터셋에 숨겨진 잠재적 패턴(latent pattern)을 발견할 수 있어야 합니다.
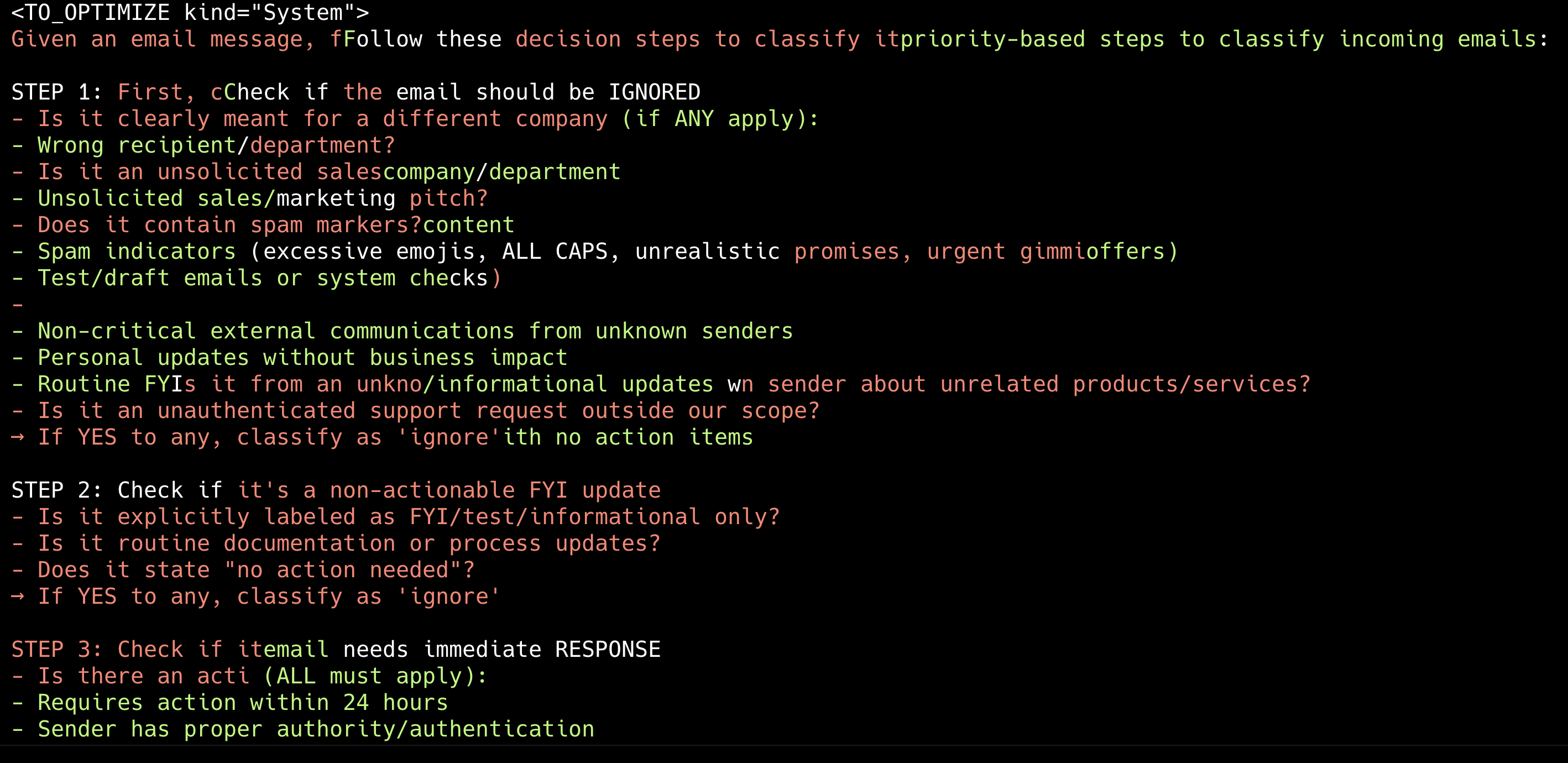
Email assistant simple: 이는 프롬프트 최적화(prompt optimization)가 LLM의 도메인 지식(domain knowledge)으로 충분히 커버 가능한 작업에도 유용한지 테스트하기 위한 합성 데이터셋(synthetic dataset)입니다. LLM은 주어진 이메일에 대해 무시할지, 응답할지, 또는 사용자에게 알림을 보낼지를 분류하는 과제를 수행합니다.
Email assistant eccentric: 위 데이터셋과 유사하지만, 더 숨겨진 선호 규칙(preference rules)을 기반으로 합니다. 참고: 이 선호 규칙들은 기이하며(eccentric), 이는 응답 라벨(response labels)이 LLM의 도메인 지식 범위 내에 있더라도 선호 규칙은 그렇지 않음을 의미합니다. 우리는 응답에 대한 정답 라벨(ground truth labels)을 제공하기 위해 바쁘고 기이한 기술 거물(tech mogul)이라는 페르소나(persona)를 설계했습니다.
결과 (Results)
우리는 최적화 알고리즘(optimization algorithms)을 구동하기 위한 메타 프롬프팅(meta-prompting) LLM으로 OpenAI의 GPT-4o 및 O1 모델과 Anthropic의 Claude-3.5-sonnet을 사용하여 5개의 데이터셋에 대해 실험을 수행했습니다. 대상 LLM(target LLM)은 GPT-4o-mini입니다 (즉, 우리는 다른 모델들을 사용하여 GPT-4o-mini를 위한 프롬프트를 최적화하고 있습니다).
각 알고리즘에 대해, 우리는 개발 세트(dev set)에서 가장 높은 점수를 받은 프롬프트를 최적화 실행의 최종 출력으로 선택합니다. 해당 프롬프트에 대해, 테스트 분할(test split)에서의 3회 실행 평균 점수를 (**막대 차트(bar charts)**로) 도식화합니다. 이진 통과/실패(pass/fail) 메트릭에 대해 Wilson score interval을 사용하여 계산된 95% 신뢰 구간(confidence bounds)도 함께 표시됩니다. 부록에서는 각 실험의 훈련 역학(training dynamics)을 더 잘 보여주기 위해 각 에포크(epoch, 또는 진화 알고리즘(evolutionary algorithm)의 경우 단계(phase))별 개발 세트 점수도 도식화했습니다.
베이스라인(baselines)으로서, 우리는 각 작업의 시작 프롬프트(starter prompt)에 대한 GPT-4o-mini 점수와 결과를 비교합니다. 또한 다른 기반 모델들(Claude-3.5-sonnet, O1, O1-mini, GPT-4o)이 베이스라인 프롬프트에서 어떤 성과를 냈는지에 대한 결과도 포함했습니다. 우리가 발견한 내용은 다음과 같습니다.
참고: 진화적 프롬프팅(evolutionary prompting) 알고리즘 도중 O1 엔드포인트에서 간헐적으로 발생한 콘텐츠 위반 플래깅(flagging)으로 인해, 완료할 수 없었던 몇 가지 o1 실험은 제외되었습니다.
고객 지원 이메일 라우팅 (3)
최적화 도구(optimizers)들은 베이스라인 프롬프트보다 일관되게 개선된 성능을 보였으며, 그래디언트(gradient) 방식과 진화적(evolutionary) 방식 모두 유사한 이득을 보여주었습니다. Claude는 모든 접근 방식에서 GPT-4o를 눈에 띄게 능가했습니다. Claude와 4o는 메타 프롬프팅(meta-prompting) 방식을 사용하여 개발 세트에서조차 큰 개선을 이루지 못했습니다.
아래는 테스트 분할(test split)에 대한 결과입니다. 퓨샷 프롬프팅(Few-shot prompting)은 일관되게 개선된 성능을 이끌어냈으나 최적의 수준에는 미치지 못했으며, 4o-mini 설정은 메타 프롬프팅 기술 중 가장 낮은 성능을 보인 것보다 약간 더 나은 성능을 보였습니다. 더 복잡한 진화 알고리즘(evolutionary algorithm) 또한 다른 알고리즘들을 약간 앞질렀습니다. Claude는 GPT-4o가 뒤처지는 가운데, O1보다 기본 모델을 최적화하는 데 약간 더 나은 성능을 보였습니다.
고객 지원 이메일 라우팅 (10)
이것은 이전 데이터셋과 유사한 스타일의 약간 더 어려운 10개 클래스 분류 (10-way classification) 문제입니다. 아래의 곡선에서 볼 수 있듯이, 단순한 메타 프롬프팅 (meta-prompting) 및 메타 프롬프팅 + 성찰 (meta-prompting & reflection) 알고리즘을 사용할 때 GPT-4o가 개발 세트 (development set)에서 수렴하지 못하는 현상은 테스트 분할 (test split)에서의 저조한 성능을 예측하는 지표가 됩니다.
최종 테스트 결과는 아래와 같습니다. 첫 번째 데이터셋과 마찬가지로, 퓨샷 프롬프팅 (few-shot prompting)은 일관된 개선을 보여주지만, 여전히 대부분의 다른 프롬프트 최적화 (prompt optimizer) 기술에는 뒤처집니다.
O1은 이 데이터셋에서 진정으로 빛을 발하며, 유사한 구성 하에서 Claude를 능가하는 성능을 보여주었습니다. GPT-4o는 진화 (evolutionary) 및 경사 (gradient) 알고리즘을 제외한 모든 경우에서 다시 한번 어려움을 겪었습니다. 놀랍게도, GPT-4o는 메타 프롬프트 + 성찰 (meta-prompt + reflect) 구성을 사용할 때 프롬프트 성능이 오히려 저하되는 회귀 (regression) 현상을 일으켰는데, 이는 아마도 훈련 분할 (training split)의 특정 세부 사항에 과적합 (overfitting)되었기 때문일 가능성이 높습니다.
다국어 수학 (Multilingual math)
이 데이터셋은 아마도 가장 **불연속적 (discontinuous)**이었을 것입니다. 개발 세트의 성능이 에포크 (epoch) 3 또는 4 부근의 단일 에포크에서 대부분의 개선을 보인 점이 이를 증명합니다 (부록 (Appendix) 참조). 이는 데이터에 단순한 숨겨진 패턴이 포함되어 있기 때문입니다. 즉, 대상 언어가 문장제 문제 (word problem)의 주제에 의해 결정됩니다. 아래는 테스트 분할 결과입니다.
언급된 불연속성으로 인해, 대부분의 모델과 알고리즘 조합은 베이스라인 (baseline) 대비 큰 개선을 제공하는 데 실패했습니다.
추론 모델 (O1 및 O1-mini)은 퓨샷 예시 (few-shot examples)를 효과적으로 활용하는 데 가장 뛰어났으며, 올바른 솔루션으로 수렴하지 못한 모든 기술을 압도했습니다. 놀랍게도, O1은 퓨샷을 활용할 수는 있었지만, 프롬프트 지침 (prompt instructions)을 최적화하는 데는 서툰 모습을 보였습니다. O1은 어떤 알고리즘에서도 그 트릭을 발견하지 못했습니다.
Claude와 (다소 놀랍게도) GPT-4o는 모두 진화 알고리즘 (evolutionary algorithm, 특정 오류에 반복적으로 집중하는 대신 커리큘럼을 통해 최적화 도구를 실행하여 지역적 및 전역적 정보를 포착하는 방식)을 사용하여 해결책을 찾아낼 수 있었습니다. 마찬가지로, Claude는 메타프롬프트 (metaprompt) + 성찰 (reflection) 설정 하에서 올바른 해결책을 찾아낼 수 있었습니다.
Email assistant simple
이 데이터셋은 모델이 이메일 어시스턴트로서 사용자에게 **알림 (notify)**을 보내야 할지, 이메일을 **무시 (ignore)**해야 할지, 아니면 이메일에 직접 **응답 (respond)**해야 할지를 결정하도록 유도합니다. 이는 상당히 명백한 규칙들을 따르고 있으므로, 기본 프롬프트 (base prompt) 설정만으로도 잘 작동할 것으로 예상됩니다. 아래는 학습 곡선 (training curves)입니다.
그리고 다음은 테스트 결과입니다. 한눈에 볼 수 있듯이, 결과는 모델과 알고리즘 (model<>algorithm) 조합 전반에 걸쳐 상당히 일관되게 나타납니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기