OpenAI의 RAG 전략 적용하기
요약
OpenAI가 고객사와의 협업을 통해 실험한 다양한 RAG(검색 증강 생성) 전략과 구현 방법을 소개합니다. 쿼리 확장, HyDE, 스텝백 프롬프팅 등 검색 품질을 높이는 기술부터 데이터 소스에 따른 라우팅 및 SQL 쿼리 생성 전략까지 폭넓은 방법론을 다룹니다.
핵심 포인트
- Query expansion과 HyDE를 활용하여 검색 성능을 극대화할 수 있습니다.
- Step-back prompting과 Rewrite-Retrieve-Read 기법은 추론 및 검색 정확도 향상에 효과적입니다.
- 다양한 데이터 소스(벡터스토어, SQL 등)를 효율적으로 사용하기 위해 LLM 기반의 라우팅 기술이 필수적입니다.
- 관계형 데이터베이스 활용을 위해 Text-to-SQL과 같은 쿼리 생성 기술이 중요하게 작용합니다.
문맥 (Context)
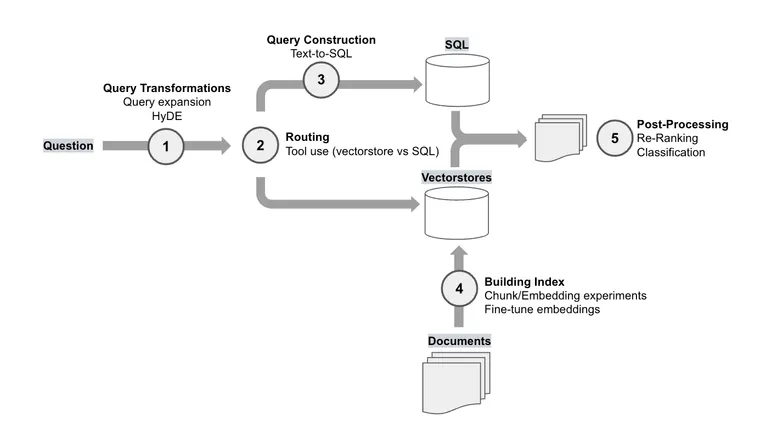
OpenAI는 데모 데이(demo day)에서 자신들이 협업한 고객을 위해 수행한 일련의 RAG (Retrieval-Augmented Generation, 검색 증강 생성) 실험 결과를 보고했습니다. 평가 지표(evaluation metrics)는 사용자의 특정 애플리케이션에 따라 달라지겠지만, 그들에게 무엇이 효과적이었고 무엇이 그렇지 않았는지 살펴보는 것은 흥미로운 일입니다. 아래에서는 언급된 각 방법을 확장하여 설명하고, 여러분이 직접 각 방법을 어떻게 구현할 수 있는지 보여드립니다. 이러한 방법들을 이해하고 애플리케이션에 적용하는 능력은 매우 중요합니다. 수많은 파트너 및 사용자와 대화해 본 결과, 서로 다른 문제에는 서로 다른 검색 기술(retrieval techniques)이 필요하기 때문에 모든 상황에 들어맞는
Query expansion (쿼리 확장): LangChain의 Multi-query retriever는 LLM을 사용하여 주어진 사용자 입력 쿼리로부터 다양한 관점의 여러 쿼리를 생성함으로써 쿼리 확장 (Query expansion)을 수행합니다. 각 쿼리에 대해 관련 문서 세트를 검색하며, 모든 쿼리에 걸친 고유한 합집합 (unique union)을 취합니다.
HyDE: LangChain의 HyDE (Hypothetical Document Embeddings, 가상 문서 임베딩) retriever는 들어오는 쿼리에 대한 가상 문서 (hypothetical documents)를 생성하고, 이를 임베딩하여 검색에 사용합니다 (논문 참조). 이 아이디어의 핵심은 이러한 시뮬레이션된 문서들이 질문 자체보다 원하는 소스 문서와 더 높은 유사성을 가질 수 있다는 점입니다.
고려할 만한 다른 아이디어들:
Step back prompting (스텝백 프롬프팅): 추론 작업의 경우, 이 논문은 스텝백 질문 (step-back question)을 사용하여 답변 합성을 더 높은 수준의 개념이나 원칙에 근거하게 할 수 있음을 보여줍니다. 예를 들어, 물리학에 관한 질문은 사용자 쿼리 뒤에 숨겨진 물리적 원리에 대한 질문과 답변으로 추상화될 수 있습니다. 최종 답변은 입력된 질문뿐만 아니라 스텝백 답변으로부터도 도출될 수 있습니다. 더 자세한 내용은 이 블로그 포스트와 LangChain 구현을 참조하십시오.
Rewrite-Retrieve-Read (재작성-검색-읽기): 이 논문은 검색을 개선하기 위해 사용자 질문을 재작성합니다. 더 자세한 내용은 LangChain 구현을 참조하십시오.
Routing (라우팅)
여러 데이터스토어 (datastores)에 걸쳐 쿼리할 때는 질문을 적절한 소스로 라우팅하는 것이 매우 중요해집니다. OpenAI의 발표에 따르면, 그들은 두 개의 벡터스토어 (vectorstores)와 하나의 SQL 데이터베이스 사이에서 질문을 라우팅해야 했습니다. LangChain은 LLM을 사용하여 사용자 입력을 정의된 서브 체인 (sub-chains) 세트로 분류하는 라우팅 기능을 지원하며, 이 경우 서로 다른 벡터스토어가 될 수 있습니다.
Query Construction (쿼리 생성)
OpenAI 연구에서 언급된 데이터 소스 중 하나가 관계형 (SQL) 데이터베이스이기 때문에, 필요한 정보를 추출하기 위해서는 사용자 입력으로부터 유효한 SQL이 생성되어야 했습니다. LangChain은 text-to-sql을 지원하며, 이는 쿼리 생성에 초점을 맞춘 최근 블로그에서 심도 있게 검토되었습니다.
고려할 만한 다른 아이디어들:
- 벡터 저장소 (Vectorstores)를 위한 Text-to-metadata 필터
- 그래프 데이터베이스 (Graph databases)를 위한 Text-to-Cypher
- Pgvector를 사용하는 Postgres 내 반정형 데이터 (Semi-structured data)를 위한 Text-to-SQL+semantic
인덱스 구축 (Building the Index)
OpenAI는 문서 임베딩 (Embedding) 과정에서 청크 크기 (Chunk size)를 실험하는 것만으로도 성능이 눈에 띄게 향상되었다고 보고했습니다. 이는 인덱스 구축의 핵심 단계이므로, 저희는 청크 크기를 테스트해 볼 수 있는 오픈 소스 Streamlit 앱을 제공하고 있습니다.
임베딩 미세 조정 (Embedding fine-tuning)을 통해 상당한 성능 향상이 있었다는 보고는 없었으나
MMR: 관련성 (relevance)과 다양성 (diversity) 사이의 균형을 맞추기 위해, 많은 벡터 저장소 (vectorstores)가 최대 한계 관련성 (max-marginal-relevance, MMR) 검색을 제공합니다 (관련 블로그 포스트 참조).
클러스터링 (Clustering): 일부 접근 방식은 샘플링을 동반한 임베딩된 문서의 클러스터링 (clustering)을 사용해 왔으며, 이는 광범위한 출처에 걸쳐 문서를 통합하는 경우에 도움이 될 수 있습니다.
결론
OpenAI가 RAG 주제에 대해 무엇을 시도했는지 살펴보는 것은 유익합니다. 위에서 보여준 것처럼 이러한 접근 방식들은 직접 재현해 볼 수 있습니다. RAG 설정에 따라 애플리케이션의 성능이 크게 달라질 수 있으므로 다양한 방법을 시도하는 것이 매우 중요합니다.
하지만 OpenAI의 결과는 이득이 거의 없거나 전혀 없는 접근 방식에 시간과 노력을 낭비하지 않기 위해 평가 (evaluation)가 매우 중요하다는 점도 보여줍니다. RAG 평가를 위해 LangSmith는 많은 지원을 제공합니다. 예를 들어, 여기 몇 가지 고급 RAG 체인 (chains)을 평가하기 위해 LangSmith를 사용하는 쿡북 (cookbook)이 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기