LangSmith 벤치마크 공유
요약
LangSmith가 LLM 아키텍처 평가를 위한 데이터셋과 결과 공유 기능을 출시하여 커뮤니티 주도의 벤치마크 활성화를 지원합니다. 새로운 `langchain-benchmarks` 패키지를 통해 개발자들은 다양한 아키텍처의 성능을 재현하고, 전체 트레이스(traces)를 포함한 상세한 비교 분석을 수행할 수 있습니다.
핵심 포인트
- LangSmith를 통한 평가 데이터셋 및 결과 공유 기능 도입으로 커뮤니티 기반 벤치마크 가능
- 새로운 `langchain-benchmarks` 패키지 출시로 실험 결과의 재현성 확보
- 단순 결과뿐만 아니라 단계별 실행 과정을 확인할 수 있는 전체 트레이스(traces) 제공
- LangChain Python 문서 Q&A를 활용한 첫 번째 벤치마크 공개
애플리케이션을 프로덕션(production) 환경으로 전환하는 개발자들로부터 듣는 가장 큰 고충은 테스트 및 평가(evaluation)에 관한 것입니다. 이러한 어려움은 새로운 모델, 새로운 검색(retrieval) 기술, 새로운 에이전트(agent) 유형, 그리고 새로운 인지 아키텍처(cognitive architectures)가 끊임없이 쏟아져 나오기 때문에 더욱 절실하게 느껴집니다.
지난 몇 달 동안, 우리는 LangSmith를 LLM 아키텍처 평가(LLM architecture evaluation)를 위한 최고의 장소(테스트 비교 보기, 데이터셋 큐레이션 등)로 만들어 왔습니다. 오늘 우리는 평가 데이터셋(evaluation datasets)과 결과(results)를 공유할 수 있도록 하여, 커뮤니티 주도의 평가와 벤치마크(benchmarks)를 더 쉽게 활성화할 수 있도록 합니다. 또한, 여러분이 이러한 결과들을 재현하고 자신의 아키텍처로 쉽게 실험할 수 있도록 새로운 langchain-benchmarks 패키지를 공유하게 되어 기쁩니다.
테스트 공유를 통해 LangSmith를 사용하는 누구나 동일한 작업 세트에 대해 서로 다른 아키텍처가 어떻게 성능을 내는지에 대한 모든 데이터와 메트릭(metrics)을 게시할 수 있습니다. 추가적인 이점으로, 우리는 단순히 최종 결과만을 기록하는 것이 아니라, 각 평가 결과에는 테스트된 체인(chains)에 수반되는 전체 트레이스(traces)가 포함됩니다. 이는 여러분이 집계 통계(aggregate statistics)와 시스템 수준의 출력(system-level outputs)을 넘어, 동일한 데이터 포인트에 대해 서로 다른 시스템이 단계별로 어떻게 실행되는지 확인할 수 있음을 의미합니다.
🦜
우리가 출시하는 첫 번째 벤치마크는 LangChain Python 문서에 대한 Q&A 데이터셋입니다. 이 질문들에 답하기 위해서는 시스템이 서로 다른 문서로부터 논리적인 방식으로 답변을 합성(synthesize)해야 합니다. 연결된 페이지에서 일반적인 접근 방식들의 성능을 검토할 수 있으며, langchain-benchmarks 패키지를 사용하여 여러분 자신의 애플리케이션 성능을 테스트해 볼 수 있습니다.
배경
배경
지난 1년 동안 LLM (Large Language Models)을 활용한 개발을 위한 툴링 (tooling)과 모델 품질은 엄청난 속도로 계속해서 개선되어 왔습니다. 매주 수십 가지의 새로운 프롬프팅 (prompting) 및 구성 (compositional) 기술들이 개발자와 연구자들에 의해 제안되며, 이들은 모두 우수한 성능 특성을 주장합니다. LangChain 커뮤니티는 밀도 체인 (chain of density)이나 스텝백 프롬프팅 (step-back prompting)과 같은 단순한 프롬프팅 기술부터, 고급 RAG (Retrieval-Augmented Generation) 기술, 그리고 RL (Reinforcement Learning) 체인, 생성형 에이전트 (generative agents), BabyAGI와 같은 자율 에이전트 (autonomous agents)에 이르기까지 이러한 기술 중 상당수를 구현해 왔습니다. 구조화된 생성 (structured generation)만 보더라도, 우리는 (다행스럽게도) 감정 프롬프팅 (emotion prompting) 기술에서 함수 호출 (function calling) 및 문법 기반 샘플링 (grammar-based sampling)과 같은 미세 조정된 (fine-tuned) API로 진화했습니다.
Hub와 LangChain Templates의 출시와 함께, 새로운 아키텍처의 출시 속도는 계속해서 가속화되고 있습니다. 하지만 이러한 접근 방식 중 어떤 것이 '여러분의' 애플리케이션에서 성능 향상으로 이어질까요? 각 기술은 어떤 트레이드오프 (tradeoffs)를 가정하고 있을까요?
신호와 소음을 구분하는 것은 어려울 수 있으며, 옵션이 풍부해질수록 신뢰할 수 있고 관련성 있는 벤치마크 (benchmarks)의 중요성은 더욱 커집니다. 일반적인 작업에 대해 언어 모델을 평가하는 데 있어서는 HELM이나 EleutherAI의 Test Harness와 같은 공개 벤치마크가 훌륭한 선택지입니다. LLM 추론 속도와 처리량 (throughput)을 측정하는 데 있어서는 AnyScale의 LLMPerf 벤치마크가 길잡이가 될 수 있습니다. 이러한 도구들은 언어 모델의 근본적인 능력을 비교하는 데는 탁월하지만, 여러분의 애플리케이션 내에서의 실제 동작을 반드시 반영하는 것은 아닙니다.
LangChain의 미션은 LLM을 활용한 개발을 최대한 쉽게 만드는 것이며, 이는 해당 분야의 관련 있는 발전 사항들을 여러분이 계속 파악할 수 있도록 돕는 것을 의미합니다. LangSmith의 평가 (evaluation) 및 트레이싱 (tracing) 경험은 집계 수준 및 샘플 수준에서 접근 방식들을 쉽게 비교할 수 있도록 도와주며, 각 단계를 상세히 파고들어 동작 변화의 근본 원인을 쉽게 식별할 수 있게 해줍니다.
공개 데이터셋과 평가(evals)를 통해 관련 데이터셋에서 모든 참조 아키텍처(reference architecture)의 성능 특성을 확인할 수 있으며, 이를 통해 노이즈(noise)에서 신호(signal)를 쉽게 분리할 수 있습니다.
📑 LangChain Docs Q&A 데이터셋
우리가 포함하는 첫 번째 벤치마크 작업은 LangChain 문서에 대한 Q&A 데이터셋입니다. 이는 LangChain의 Python 문서에 대해 우리가 직접 작성한 수동 제작 질문-답변 쌍(question-answer pairs) 세트입니다. 질문들은 RAG 시스템이 여러 문서의 정보가 필요하거나 질문이 문서의 지식과 충돌하는 경우에도 올바르게 답변할 수 있는 능력을 테스트하도록 작성되었습니다.
초기 출시의 일환으로, 우리는 몇 가지 차원에서 서로 다른 다양한 구현체들을 평가했습니다:
- 사용된 언어 모델 (OpenAI, Anthropic, OSS 모델)
- 사용된 "인지 아키텍처 (cognitive architecture)" (대화형 검색 체인 (conversational retrieval chain), 에이전트 (agents))
위 링크를 통해 결과를 검토하거나 아래의 정보를 계속 확인하실 수 있습니다!
🦜💪 LangChain 벤치마크
여러분이 Q&A 데이터셋에서 자신만의 아키텍처를 실험할 수 있도록 돕기 위해, 새로운 langchain-benchmarks 패키지(문서 링크)를 공개합니다. 이 패키지는 LLM을 사용하여 구축할 때 핵심 기능에 대한 실험과 벤치마킹을 용이하게 합니다. 또한 우리는 벤치마크 추출(benchmarks extraction), 에이전트 도구 사용(agent tool use), 그리고 검색 기반 질의응답(retrieval-based question answering)을 공개하고 있습니다.
각 데이터셋에 대해, 우리는 다양한 LLM, 프롬프트(prompts), 인덱싱 기술(indexing techniques) 및 기타 도구들을 쉽게 테스트할 수 있는 기능을 제공하므로, 여러분은 다양한 설계 결정의 트레이드오프(tradeoffs)를 빠르게 측정하고 애플리케이션에 가장 적합한 솔루션을 선택할 수 있습니다.
💡
위 링크를 사용하여 직접 시도해 보거나, LangChain Benchmarks 리포지토리(repository)에 새로운 작업(tasks)을 요청하는 기능 요청(feature request)을 열어보세요.
이 포스트에서는 이것이 어떻게 작동하는지 보여주기 위해 질의응답 작업 중 하나의 결과를 검토하겠습니다!
단순 RAG 접근 방식 비교
우리의 초기 벤치마크에서는 다음 템플릿을 기반으로 LLM 아키텍처를 평가했습니다:
단순 RAG 접근 방식 비교
우리의 초기 벤치마크에서는 다음 템플릿을 기반으로 LLM 아키텍처를 평가했습니다:
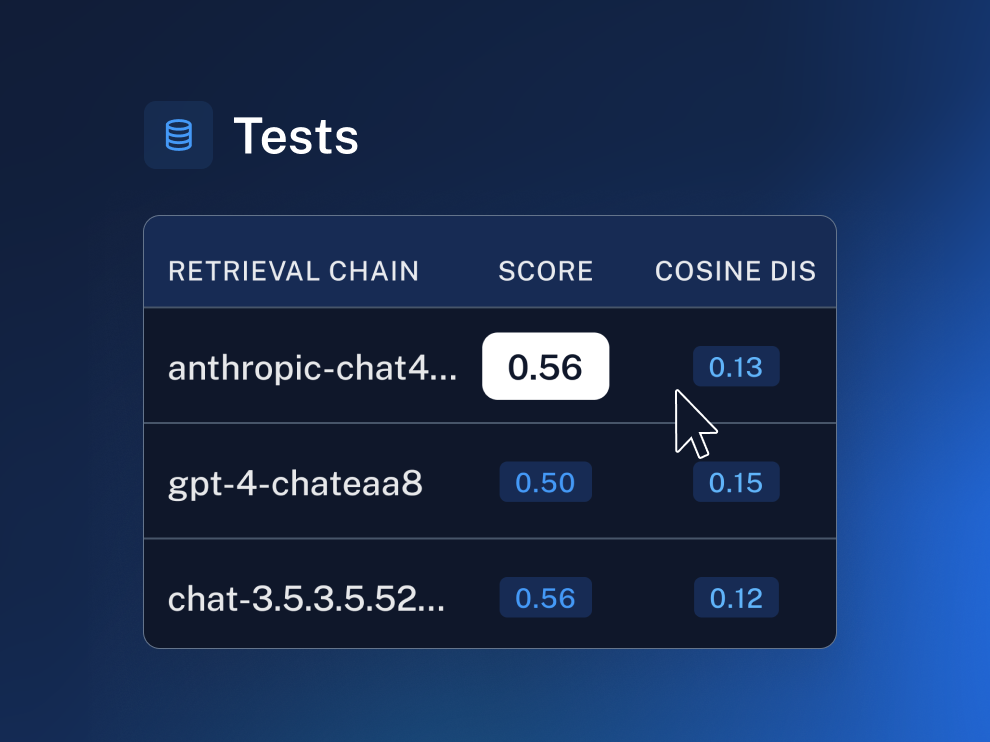
| Cognitive Architecture | Test Score ⬆️ | Cosine Dist ⬇️ | Link |
|---|---|---|---|
| Conversational Retrieval Chainzephyr-7b-beta a2f3 | 0.31 | 0.18 | link |
| mistral-7b-instruct-4k 0826 | 0.46 | 0.13 | link |
| gpt-4-chat f4cd | 0.50 | 0.15 | link |
| chat-gpt-3.5 1098 | 0.56 | 0.12 | link |
| anthropic-chat f290 | 0.56 | 0.13 | link |
| Agentopenai-functions-agent dc91 | 0.47 | 0.13 | link |
| gpt-4-preview-openai-functions-agent 5832 | 0.58 | 0.14 | link |
| anthropic-iterative-search 1fdf | 0.50 | 0.14 | link |
| Assistantopenai-assistant af8e | 0.62 | 0.13 | link |
The 위의 링크들은 자동화된 지표를 사용하여 각 구성의 결과를 확인하고 비교할 수 있도록 합니다. 이 테스트에서는 예측 응답과 참조 응답 간의 코사인 거리(cosine distance)와 LangChain의 LLM 기반 스코어링 평가기(LLM-based scoring evaluator)를 사용한 정확도
위의 모든 실행은 동일한 리트리버 (retriever)를 사용하므로, 결과의 차이는 검색된 데이터에 대해 추론하는 LLM의 능력에 기인합니다.
에이전트 (Agents)
다음 테스트는 질문에 답하기 위해 agent 아키텍처를 적용합니다. 에이전트에는 위에서 설명한 것과 동일한 벡터 스토어 리트리버 (vector store retriever)를 래핑한 단일 리트리버 도구가 제공됩니다. 에이전트는 직접 응답하거나, 질문에 답하기 위해 자신의 쿼리로 리트리버를 원하는 횟수만큼 호출할 수 있습니다. 실제로 우리는 에이전트가 일반적으로 도구를 한 번 호출한 후 응답한다는 것을 확인했습니다.
openai-functions-agent dc91:
OpenAI의 함수 호출 (function calling) API (현재는 '도구 호출 (tool calling)' API로 불림)를 사용하여 문서 리트리버와 상호작용합니다. 이 경우 에이전트는 gpt-3.5-turbo-16k 모델에 의해 구동됩니다.
gpt-4-preview-openai-functions-agent 5832:
위와 동일하지만, gpt-3.5보다 더 크고 유능한 모델인 새로운 gpt-4-1106-preview 모델을 사용합니다.
anthropic-iterative-searche 1fdf:
반복 검색 (iterative search) 에이전트를 적용하며, Anthropic의 claude-2 모델이 검색 도구를 호출하도록 프롬프트를 제공하고, 구조화된 텍스트 생성의 신뢰성을 높이기 위해 XML 형식을 사용합니다.
💡
**대화형 검색 체인 (conversational retrieval chain)**과 비교했을 때, 위의 결과들은 검색 (retrieval) 방식에서 차이가 있습니다. 즉, 이들은 LLM을 사용하여 관련 검색 쿼리를 생성합니다.
Assistant API
마지막으로, openai-assistant af83에서 OpenAI의 새로운 Assistants API를 테스트했습니다. 이 역시 동일한 검색 도구를 사용하지만, 쿼리와 최종 응답을 결정하는 데 OpenAI의 실행 로직을 사용합니다. 이 에이전트는 결과적으로 우리의 모든 테스트 중 가장 높은 성능을 기록했습니다.
결과 검토하기
비교 뷰 (comparison views)를 사용하면 출력을 수동으로 쉽게 검토하여 모델이 어떻게 동작하는지 더 잘 파악할 수 있으므로, 인지 아키텍처 (cognitive architecture)를 조정하고 식별된 실패 모드 (failure modes)를 해결하기 위해 평가 기술을 업데이트할 수 있습니다.
예를 들어, Mistral-7b RAG 애플리케이션 기반의 대화형 검색 체인(conversational retrieval chain)을 유사한 구조를 가진 GPT-3.5 기반 애플리케이션과 비교해 보겠습니다: (comparison link). 테스트된 프롬프트(prompts)를 사용했을 때, GPT-3.5의 성능은 이 예시를 위해 생성된 종합 지표(aggregate metrics) 측면에서 Mistral 7B 모델을 여유 있게 앞섭니다 (평균 코사인 차이(average cosine difference)는 0.01 차이지만, 평균 "정확도(accuracy)" 점수에서는 0.1 뒤처집니다).
참고: 이 실험에서 테스트된 오픈 소스(open-source) 모델 중 어떤 것도 별도의 설정 없는 상태(off-the-shelf)에서 독점 API(proprietary APIs)의 종합적인 성능을 따라잡지는 못했습니다. 다만, 추가적인 프롬프트 엔지니어링(prompt engineering)을 통해 그 격차를 줄일 수는 있습니다.
이는 흥미로운 결과이지만, 어떻게 개선할지 결정하려면 데이터를 살펴봐야 합니다. LangSmith는 이 과정을 쉽게 만들어 줍니다. 다음과 같은 까다로운 사례를 살펴보겠습니다:
이 데이터 포인트(data point)의 경우, 두 모델 모두 정답을 맞히지 못했습니다. 질문 자체가 '부재(absence)'에 대한 지식을 요구하는데, 이는 RAG 애플리케이션에 있어 매우 어려운 작업이며 종종 환각(hallucinations)으로 이어지곤 합니다.
육안으로 검사했을 때, gpt-3.5-turbo 모델은 명백하게 환각을 일으키며, 심지어 그럴싸하게 지어낸 링크(https://docs.langchain.com/java-sdk)까지 제공합니다. mistral 모델의 응답은 부정확한 정보를 생성하지 않으므로(공식적인 LangChain java SDK는 존재하지 않습니다) 더 바람직합니다.
모델들이 왜 그렇게 응답했는지 진단하려면, 해당 아키텍처(architecture)의 전체 트레이스(trace)를 클릭하여 확인할 수 있습니다.
트레이스(link)를 통해 확인하면, 검색된 문서(retrieved documents)들이 원래의 쿼리(query)와 모두 상당히 무관하다는 점이 명확히 드러납니다. 만약 gpt-3.5와 같은 모델을 사용하면서 이와 같은 환각이 발생한다면, 모델에게 검색된 콘텐츠에 기반해서만 응답하도록 상기시키는 추가적인 시스템 프롬프트(system prompt)를 더해볼 수 있으며, 검색기(retriever)를 개선하여 무관한 문서를 걸러내도록 작업할 수 있습니다.
또 다른 데이터 포인트를 검토해 보겠습니다. 이번에는 gpt-3.5는 올바르게 응답했지만 mistral은 그렇지 못한 사례입니다. 출력값(outputs)을 비교해 보면, mistral이
문서 내용에 너무 많이 영향을 받아 직접적인 답변 대신 문서에 포함된 클래스를 언급했습니다.
트레이스(trace)를 살펴보면, "SelfQueryRetriever"는 검색된 문서 중 문서 5(Document 5)에서만 언급되는데, 이는 해당 문서가 가장 관련성이 낮음을 의미합니다. LLM이 이 문서에 기반하여 응답을 결정한다는 것은, 입력 순서를 재조정함으로써 성능을 개선할 수 있음을 시사합니다.
이 가설을 확인하려면 플레이그라운드(playground)에서 LLM 실행(run)을 열 수 있습니다. 문서 1과 5의 순서를 바꿈으로써, LLM이 올바른 답변을 하는 것을 확인할 수 있습니다. 이 확인 과정을 바탕으로, 문서를 제시하는 순서를 업데이트하고 평가를 다시 실행할 수 있습니다!
응답 정확도 외에도 지연 시간(latency)은 LLM 애플리케이션을 구축할 때 중요한 또 다른 지표입니다. 우리의 경우, mistral-7b의 중앙값 응답 시간(median response time)은 18초로, gpt-3.5보다 11초 더 느렸습니다.
품질 지표(quality metrics)를 "시스템 지표(system metrics)"와 함께 측정하면 작업에 적합한 "적정 규모(right-sized)"의 모델과 아키텍처를 선택하는 데 도움이 됩니다.
마지막으로, openai-assistant af83를 유사한 gpt-4-preview-openai-functions-agent 5832 테스트와 비교해 보겠습니다. 두 테스트는 동일한 기반 모델과 검색 도구(retriever tool)를 사용하며 에이전트(agent)로서 작동하지만, 전자의 테스트는 OpenAI의 어시스턴트 API(assistant API)를 사용합니다. 비교 결과는 여기에서 확인할 수 있습니다: link.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기