제어 평면(Control Plane)이 핵심이었다: LLM 시대에 다시 살펴보는 autofz
요약
메타 퍼저 autofz의 제어 평면(control-plane) 프레임워크를 통해 LLM 에이전트 시스템의 오케스트레이션 문제를 고찰합니다. 불완전한 작업자들 사이에서 예산을 효율적으로 배분하고 최적의 작업을 선택하는 제어 평면의 중요성을 강조합니다.
핵심 포인트
- 불완전한 작업자(LLM, 에이전트 등) 간의 효율적인 예산 배분 문제
- 타겟 민감도에 따라 최적의 작업자(퍼저, 에이전트)가 달라짐
- 캠페인 도중 최적의 작업자가 변하는 순위 역전 현상 발생
- 퍼징 연구의 피드백 및 증거 공유 교훈을 AI 에이전트에 적용 가능
서문
autofz는 메타 퍼저(meta-fuzzer)입니다. 즉, 기존 퍼저(fuzzer)들을 위한 런타임 오케스트레이터(runtime orchestrator)입니다. 저는 박사 과정 초기에 이를 개발했으며, USENIX Security 2023에 채택되었습니다. 논문과 GitHub 저장소는 모두 공개되어 있습니다.
몇 년이 지난 지금, autofz가 가장 많이 인용되는 퍼징(fuzzing) 논문 중 하나는 아니지만, 그 제어 평면(control-plane) 프레임워크는 제 예상보다 더 오랫동안 유효하게 유지되고 있습니다.
제가 지금 autofz를 다시 살펴보려는 이유는, 이 연구의 핵심 질문이 원래의 퍼징 맥락보다 더 관련성이 높게 느껴지기 때문입니다. 즉, 불완전한 작업자(worker)가 많을 때, 시스템은 정해진 예산(budget)을 이들 사이에서 어떻게 배분해야 하는가에 대한 문제입니다.
2023년에 작업자(worker)는 퍼저(fuzzer)였습니다. 오늘날 CRS 및 LLM-agent 시스템에서 작업자는 퍼저, 정적 분석기(static analyzer), 코드 에이전트(code agent), 패치 생성기(patch generator), 검증기(validator) 또는 모델 변체(model variant)가 될 수 있습니다. 대상 영역은 변했지만, 제어 평면(control-plane)에 관한 질문은 유사합니다. 어떤 작업자를 실행해야 하는가, 어떤 증거를 공유해야 하는가, 시스템은 언제 방향을 전환해야 하는가, 그리고 언제 중단해야 하는가 하는 점입니다.
보안 역량이 더 저렴해지고 더 널리 보급됨에 따라 이 문제는 더욱 중요해지고 있습니다. 보안 문제가 해결되었다거나 전문가 시스템이 더 이상 중요하지 않다는 뜻은 아닙니다. 저는 더 좁은 의미에서 말씀드리는 것입니다. 즉, 그럴듯한 버그 후보(bug candidate)를 생성하는 것은 점점 더 쉬워지고 있다는 점입니다. 더 어려운 문제는 노이즈가 섞인 후보 생성(candidate generation)을 신뢰할 수 있는 증거, 재현 가능한 PoV(Proof of Vulnerability), 유용한 패치, 그리고 적절한 예산 결정으로 전환하는 것입니다.
이것이 바로 지난 10년간의 퍼징(fuzzing) 연구가 구식으로 취급되어서는 안 된다고 생각하는 이유입니다. 정확한 기술이 문자 그대로 재사용되지 않더라도, 이 분야는 저렴한 피드백(feedback), 노이즈가 있는 평가(noisy evaluation), 증거 공유(evidence sharing), 그리고 고정 예산 자동화(fixed-budget automation)에 관한 값진 교훈들을 축적해 왔습니다. autofz는 그 더 큰 오케스트레이션(orchestration) 문제의 작은 버전 중 하나였습니다.
퍼저 선택이 어려운 이유
autofz의 이면에 있는 초기 관찰은 간단했습니다. 단 하나의 퍼저가 항상 최선의 퍼저일 수는 없다는 것입니다. 논문은 네 가지 관찰을 통해 이를 구체화했습니다.
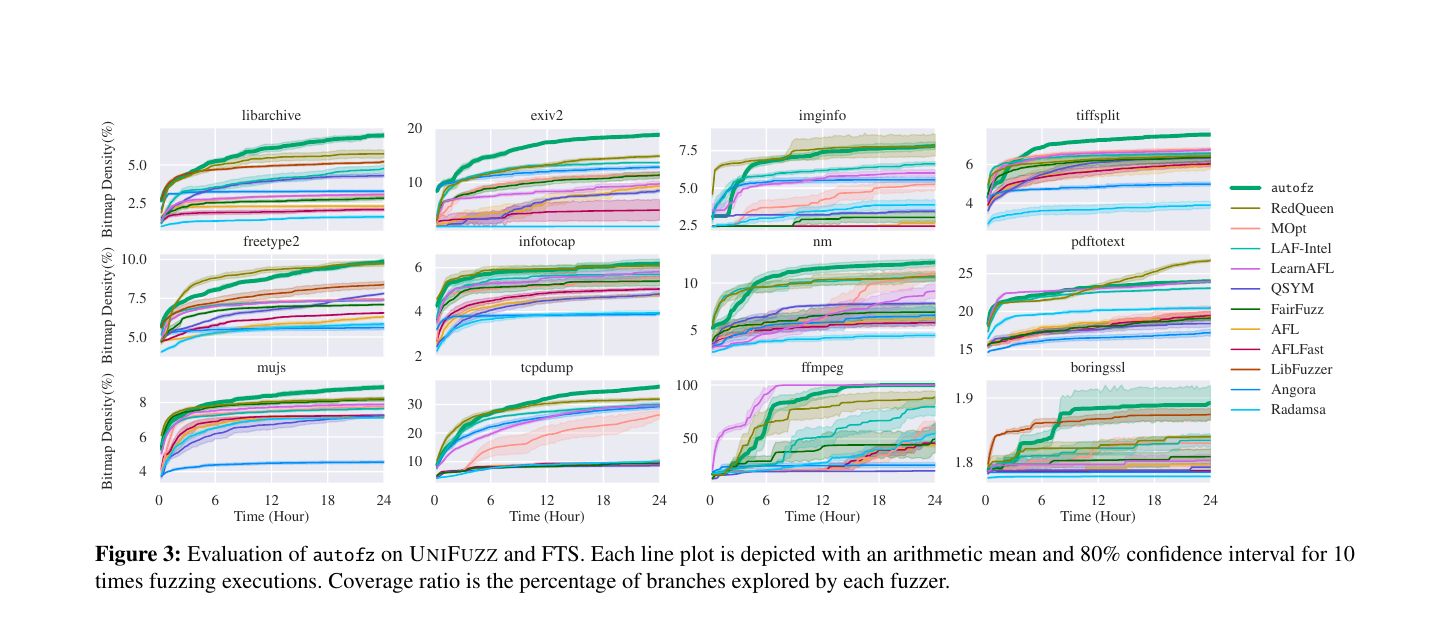
첫째, 범용적인 퍼저(fuzzer)는 존재하지 않습니다. 서로 다른 퍼저들은 변이 전략 (mutation strategy), 스케줄링 (scheduling), 인스트루멘테이션 (instrumentation), 시드 관리 (seed management), 그리고 탐색 압력 (search pressure) 측면에서 서로 다른 트레이드오프 (tradeoffs)를 가집니다. 논문의 동기 부여 사례에서, LearnAFL은 ffmpeg에서 가장 좋은 성능을 보였지만, exiv2에서는 6위로 떨어졌습니다. RedQueen 또한 동일한 리소스 예산 하에서 exiv2에 대해 Radamsa보다 10배 이상의 성능을 발휘했습니다. 이러한 타겟 민감도 (target sensitivity) 때문에 "그저 가장 좋은 퍼저를 사용하라"는 말은 만족스러운 운영상의 해답이 될 수 없습니다.
둘째, 동일한 캠페인 도중에도 최선의 퍼저가 바뀔 수 있습니다. 우리는 이를 순위 역전 (rank inversion)이라고 불렀습니다. exiv2에서 Angora는 초기에 강력한 진전을 보였으나, 약 2시간 후 LAF-Intel과 RedQueen이 따라잡았습니다. 이후 LAF-Intel과 RedQueen 사이에서 또 다른 역전이 발생했습니다. 시작 단계에서 내린 정적인 결정은 이러한 변화를 놓치게 됩니다.
셋째, 동일한 리소스 할당은 낭비입니다. 협업 퍼징 (collaborative fuzzing)은 시드 (seeds)를 공유함으로써 단일 퍼저보다 개선될 수 있지만, 모든 퍼저가 영원히 동일한 CPU 예산을 할당받는다면 시스템은 현재 유용하지 않은 워커 (workers)들에 여전히 너무 많은 시간을 소비하게 됩니다.
넷째, 퍼징의 무작위성은 오프라인 결정을 취약하게 만듭니다. 전문가가 하나의 벤치마크 실행을 위해 좋은 조합을 찾아내더라도, 그 가이드는 다음 워크로드, 다음 시드 코퍼스 (seed corpus), 또는 심지어 동일한 타겟의 다른 실행에서 재현되지 않을 수 있습니다. 선택의 부담은 사라지는 것이 아니라, 벤치마크 선택, 학습 데이터, 또는 수동 튜닝 (manual tuning)으로 옮겨질 뿐입니다.
이것이 autofz가 제거하고자 했던 실질적인 문제였습니다. 사용자는 사용 가능한 퍼저 풀 (pool)을 제공하기만 하면 되고, 어떤 퍼저가 현재의 예산을 할당받을 가치가 있는지는 시스템이 결정할 수 있어야 합니다.

autofz의 작동 방식
autofz는 새로운 퍼징 알고리즘을 구현하지 않습니다. 대신 기존의 퍼저들을 실행하며, 그 위에 제어 평면 (control plane)을 추가합니다.
제어 루프 (control loop)는 두 단계로 나뉩니다. 준비 단계 (preparation phase)에서 autofz는 베이스라인 퍼저 (baseline fuzzers)들에게 짧고 공평한 실행 기회를 부여하고 그들의 진행 상황을 관찰합니다. 퍼저들은 서로 다른 내부 피드백 (internal feedback)을 사용하기 때문에, autofz는 그들의 흥미로운 입력값들을 공통된 AFL 비트맵 뷰 (AFL bitmap view)로 매핑합니다. 이를 통해 오케스트레이터 (orchestrator)는 런타임 트렌드 (runtime trends)를 비교할 수 있는 통일된 방법을 갖게 됩니다.
두 번째 단계는 집중 단계 (focus phase)입니다. autofz는 관찰된 트렌드를 자원 할당 (resource allocation) 결정으로 변환합니다. 만약 특정 퍼저가 명확하게 앞서 나가고 있다면, autofz는 다음 예산 구간 (budget window)을 해당 퍼저에게 할당할 수 있습니다. 여러 퍼저가 유용해 보인다면, 자원을 비례적으로 분배할 수 있습니다. 시드 (seeds)는 퍼저들 간에 동기화되어, 한 작업자 (worker)의 발견이 다른 작업자의 시작점이 될 수 있도록 합니다.
그 후 시스템은 이를 반복합니다. 이전 구간에서 가장 좋았던 퍼저가 다음 구간에서도 여전히 가장 좋은 퍼저일 것이라고 가정하지 않습니다.

논문에서 중요한 문구는 “프로그램당이 아니라, 워크로드 (workload)당”입니다. 프로그램은 하나의 정적인 탐색 문제 (static search problem)가 아닙니다. 퍼징 (fuzzing)이 진행됨에 따라 남은 브랜치 (branches), 유용한 시드 (useful seeds), 그리고 병목 지점 (bottlenecks)이 변화합니다. autofz는 전체 캠페인 동안 하나의 퍼저 세트에 고착되는 대신, 그러한 런타임 워크로드에 반응하려고 시도합니다.
시간이 많이 걸렸던 부분: 결정의 방어 가능성 확보하기
첫 번째 작동 가능한 프로토타입은 EnFuzz를 빠르게 이겼습니다. 하지만 그 프로토타입을 논문으로 만드는 데는 훨씬 더 오랜 시간이 걸렸습니다. 리뷰어들의 명백한 질문은 “한 번 이기는가?”가 아니라, “스케줄링 결정 (scheduling decisions)이 실제로 좋은가?”였기 때문입니다.
그것이 바로 우리가 autofz의 결정에 대한 평가를 추가한 이유입니다. 각 라운드마다 우리는 준비 단계 직후의 시점을 기록하고, 캠페인을 해당 스냅샷 (snapshot)으로 여러 번 복구했습니다. 그런 다음 autofz의 자원 할당을, 한 번에 하나의 베이스라인 퍼저에게 전체 집중 단계 예산을 모두 부여하는 합성 결정 (synthetic decisions)과 비교했습니다. 이는 다음과 같은 반사실적 질문 (counterfactual question)을 던지는 방법이었습니다: 동일한 시작 코퍼스 (starting corpus)와 동일한 집중 단계 시간 예산이 주어졌을 때, autofz가 선택한 할당 방식이 명백한 대안들과 비교했을 때 경쟁력이 있는가?
답은 대체로 '예'였지만, 유용한 주의 사항(caveats)들이 있었습니다. libarchive의 경우, autofz의 결정은 14라운드 중 8라운드에서 1위를 차지했으며 평균 순위는 2.64였습니다. exiv2의 경우, 15라운드 중 4라운드에서 1위를 차지했으며 평균 3.5를 기록했습니다. 이는 핵심 주장인 '준비(preparation) 단계에서 관찰된 트렌드가 이후 집중(focus) 단계에서도 유용하게 유지되는 경우가 많다'는 점을 뒷받침하기에 충분했습니다.
이러한 주의 사항들은 논문 작성에 있어 중요했습니다. 커버리지(coverage)가 포화 상태에 도달하면, 어떤 할당을 하더라도 큰 진전을 보일 수 없기 때문에 퍼저(fuzzer)의 선택이 덜 중요해집니다. exiv2에서는 4라운드 이후 서로 다른 결정들이 매우 미미한 커버리지 차이를 만들어냈습니다. 한 후반 라운드에서는 최선의 결정과 최악의 결정 사이의 차이가 비트맵 밀도(bitmap density) 기준 단 0.07%에 불과했습니다. 퍼징의 무작위성(randomness) 또한 동일한 스냅샷(snapshot)에서 비교를 시작하더라도 노이즈를 추가합니다. 시드 동기화(Seed synchronization)는 다음 트렌드를 더욱 변화시킬 수 있습니다. 즉, 준비 단계에서 가장 강력하지 않았던 퍼저가 다른 퍼저가 차단을 해제하는(unblock) 입력을 발견하고 공유한 이후에 더 강력해질 수 있다는 것입니다.
이 부분이 제가 데모(demo)와 논문(paper) 사이의 진정한 엔지니어링/연구 격차로 기억하는 지점입니다. 프로토타입은 오케스트레이션(orchestration)이 도움이 될 수 있음을 보여주었습니다. 하지만 논문은 특정 스케줄링 알고리즘이 왜 합리적인지, 그 결정이 언제 신뢰할 수 있는지, 그리고 언제 신호(signal)가 약해지는지를 설명해야 했습니다. 우리는 또한 준비 단계와 집중 단계 주변의 하이퍼파라미터(hyperparameters)를 조정해야 했습니다. 얼마나 오래 측정할지, 준비 단계를 얼마나 빨리 조기 종료(early-exit)할지, 활용(exploitation) 대신 평가(evaluation)에 얼마나 많은 예산을 쓸지, 그리고 얼마나 자주 결정을 재검토할지 등을 결정해야 했습니다. 이러한 세부 사항들은 화려하지는 않지만, 메타 퍼저(meta-fuzzer)가 실제로 유용한지 아니면 단순히 벤치마크 실행에서 운이 좋았던 것인지를 결정합니다.
autofz의 타임라인: 아이디어에서 논문 채택까지
- 초기 아이디어: 정확한 날짜는 기억나지 않지만, 2020년 11월경.
- EnFuzz를 이기는 첫 번째 작동 가능한 프로토타입: 2020년 12월경.
- NDSS 2023: 2라운드까지 진출했으나 탈락; 아까운 결과였습니다. 2022년 5월.
- IEEE S&P 2023: 조기 탈락(early rejection).
- USENIX Security 2023: 2023년 1월 수정 제안(minor revision) 후 채택.
autofz를 출판 가능한 논문으로 만들기 위해서는 단순히 작동하는 프로토타입(prototype) 이상의 훨씬 많은 노력이 필요했습니다. 특히 제가 여전히 수업을 듣고 있던 시기였기에 더욱 그러했습니다. 퍼징(fuzzing) 연구에서는 베이스라인(baseline)을 뛰어넘는 것만으로는 충분하지 않습니다. 진짜 어려운 부분은 시스템이 왜 이기는지, 언제 이기는지, 그리고 실제로 어떤 메커니즘이 중요한지를 설명하는 것입니다.
autofz의 경우, 스케줄러(scheduler), 개별 퍼저(fuzzer), 시드 동기화(seed synchronization), 벤치마크 설정(benchmark setup), 그리고 리소스 할당(resource allocation) 등 많은 구성 요소가 움직이는 메타 퍼저(meta-fuzzer)이기 때문에 이 점이 특히 더 절실했습니다. 이 모든 요소가 최종 결과에 영향을 미칠 수 있기 때문입니다.
관련 연구: 정적 앙상블(static ensembles) vs 런타임 오케스트레이션(runtime orchestration)
EnFuzz
EnFuzz는 초기 프로토타입 단계에서 우리가 비교 대상으로 삼았던 주요 협업 퍼징(collaborative fuzzing) 베이스라인이었습니다. EnFuzz는 여러 퍼저를 앙상블(ensemble)하여 시드(seed)를 공유할 수 있게 합니다. 이는 이미 유용한 아이디어입니다. 서로 다른 퍼저들이 서로의 발견으로부터 이득을 얻을 수 있기 때문입니다.
한계점은 시드 공유만으로는 구성(composition) 문제의 전부를 해결할 수 없다는 것입니다. 만약 모든 퍼저가 거의 고정되거나 동일한 리소스를 할당받는다면, 시스템은 특정 시점에 어떤 퍼저가 더 많은 CPU를 할당받아야 하는지에 대한 답을 여전히 내놓지 못합니다. 즉, EnFuzz는 협업적이지만, 리소스 할당은 여전히 대부분 정적(static)입니다.
autofz는 유용한 부분인 시드 동기화(seed synchronization)는 유지하되, 그 위에 런타임 스케줄링(runtime scheduling)을 추가합니다. autofz는 퍼저 선택(fuzzer selection)과 리소스 할당(resource allocation)을 일급 문제(first-class problems)로 취급합니다.
CUPID
CUPID 역시 퍼저를 결합하는 데 초점을 맞추고 있다는 점에서 중요한 연구 흐름 중 하나입니다. 차이점은 선택 결정이 언제, 어떻게 이루어지는가에 있습니다. CUPID는 오프라인 분석(offline analysis)과 훈련 세트(training set)를 사용하여 타겟에 독립적인 퍼저 조합을 예측합니다. 이는 선택된 앙상블이 캠페인(campaign) 동안 여전히 정적임을 의미합니다.
해당 논문의 표 1(Table 1)은 그 차이점을 다음과 같이 요약했습니다:
| 속성 (Property) | EnFuzz | CUPID | autofz |
|---|---|---|---|
| 선택된 퍼저(fuzzer) 수 | 사용자 설정 (user-configured) | 사용자 설정 (user-configured) | 자동 (automatic) |
| ... |
저는 이제 이것을 정적 앙상블(static ensembles)과 런타임 오케스트레이션(runtime orchestration) 사이의 차이로 설명하겠습니다. EnFuzz와 CUPID는 유용한 퍼저 그룹을 선택하는 것에 관한 것입니다. 반면 autofz는 워크로드(workload)가 변화함에 따라 어떤 워커(worker)에게 예산(budget)을 할당할지 반복적으로 결정하는 것에 관한 것입니다.
그 결과는 단순히 더 나은 커버리지(coverage)에 그치지 않았습니다. 논문에서 autofz는 12개의 벤치마크 중 11개에서 최고의 개별 퍼저들을 능가했으며, 20개의 벤치마크 중 19개에서 협업 퍼징(collaborative fuzzing) 방식들을 이겼습니다. 평균적으로 UNIFUZZ와 FTS에서는 개별 퍼저보다 152% 더 많은 버그를 찾아냈으며, UNIFUZZ에서는 협업 퍼징보다 415% 더 많은 버그를 찾아냈습니다.


저수준 기술 조합(Low-level technique composition) vs. 고수준 퍼저 오케스트레이션(high-level fuzzer orchestration)
리뷰 과정에서, 그리고 이후 arXiv 버전 공개 후 Hacker News에서 공통적으로 나왔던 질문 중 하나는 autofz가 AFL++와 어떻게 다른가 하는 점이었습니다. 저는 두 가지 수준의 조합(composition)을 분리하여 생각하는 것이 더 나은 프레임워크라고 생각합니다.
AFL++는 저수준 조합(low-level composition)의 훌륭한 예시입니다. AFL++는 하나의 강력한 퍼저 구현체 내부에 호환 가능한 많은 퍼징 기술들을 결합합니다. autofz는 해당 계층과 경쟁하지 않습니다. autofz는 풀(pool) 내의 하나의 워커로서 AFL++를 사용할 수 있습니다.
그 차이점은 "하나의 퍼저 안에 많은 기술이 들어있는 것"이 "많은 워커를 오케스트레이션하는 것"과 같지 않다는 점입니다. AFL++의 CmpLog 지원과 같이 일부 기능들은 깔끔하게 조합됩니다. 하지만 -p 옵션으로 선택되는 파워 스케줄(power schedules)과 같이 프로세스당 상호 배타적인(mutually exclusive) 선택 사항들도 있습니다. QSYM 및 Angora와 같은 다른 워커들은 각자 고유의 인스트루멘테이션(instrumentation)과 런타임 가정(runtime assumptions)을 가지고 있습니다.
따라서 이 두 계층은 상호 보완적입니다. AFL++는 개별 퍼저(fuzzer)를 강화합니다. EnFuzz와 autofz는 더 높은 수준에서 작동합니다. 즉, 여러 퍼저를 별도의 워커(worker)로 실행하고, 유용한 아티팩트(artifact)를 공유하며, 어떤 워커에게 리소스를 할당할지 결정합니다. autofz의 기여는 바로 이 상위 수준의 오케스트레이션(orchestration) 문제입니다. 즉, 기존의 여러 퍼저가 주어졌을 때, 어떤 것을 실행해야 하는지, 시스템이 언제 전환해야 하는지, 그리고 각 퍼저가 얼마만큼의 리소스를 받아야 하는지를 결정하는 것입니다.
이러한 구분은 두 접근 방식이 공존할 수 있기 때문에 중요합니다. 더 나은 개별 퍼저는 풀(pool)을 더 강력하게 만듭니다. 더 나은 오케스트레이터는 정해진 예산 내에서 그 풀을 어떻게 사용할지 결정합니다.
퍼저를 추가하는 것이 오케스트레이션을 잘하는 것과 같지는 않다
동일한 함정이 멀티 에이전트 시스템(multi-agent systems)에서도 나타납니다. 더 많은 에이전트를 추가하면 다양성을 높일 수 있지만, 컨텍스트 손실(context loss), 메시지 전달 오버헤드(message-passing overhead), 그리고 조정 부담(coordination burden)을 초래하기도 합니다. 만약 오케스트레이터가 어떤 에이전트가 다음 단계를 맡아야 하는지, 어떤 증거를 압축하여 공유해야 하는지, 그리고 언제 스레드(thread)를 포기해야 하는지를 결정하지 못한다면, 시스템은 작업을 해결하는 대신 정보를 옮기는 데 예산의 대부분을 소비할 수 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기