on-the-fly learning(즉각적 학습)을 측정하기 위한 새로운 벤치마크, EBR-bench를 소개합니다
요약
AI의 즉각적 학습(on-the-fly learning) 능력을 측정하기 위한 새로운 벤치마크인 EBR-bench를 소개합니다. 텍스트 기반 보드 게임인 Earthborne Rangers를 활용하여 모델이 반복적인 플레이를 통해 스스로 개선되는지를 평가합니다.
핵심 포인트
- EBR-bench는 AI의 실시간 학습 능력을 측정하는 새로운 지표임
- Earthborne Rangers 게임을 통해 전략적 덱 빌딩 및 전술적 플레이 평가
- 최신 모델들의 성능 향상은 즉각적 학습이 아닌 기본 성능 향상에 기인함
- 즉각적 학습 능력은 AI의 범용성 및 안전성 측면에서 매우 중요함
on-the-fly learning(즉각적 학습)을 측정하기 위한 우리의 새로운 벤치마크인 EBR-bench를 소개합니다.
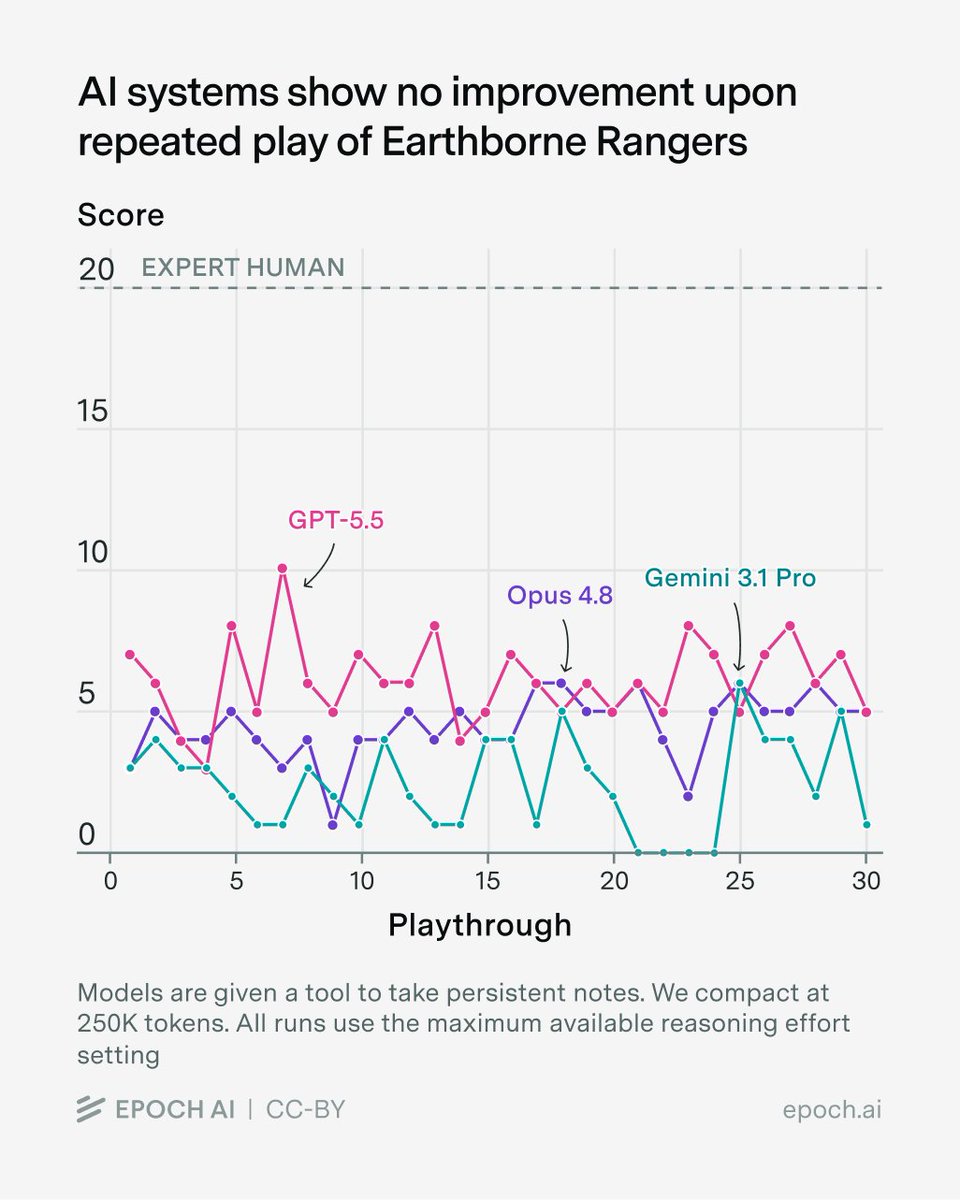
AI가 Earthborne Rangers라는 도전적인 보드 게임을 반복적으로 플레이하며 자신의 실수로부터 배우려고 시도합니다. 지금까지는: 개선의 징후가 없습니다.
만약 AI가 on-the-fly learning(즉각적 학습)을 할 수 있다면, 훨씬 더 범용적인(general-purpose) 존재가 될 것입니다. 이는 경제적 영향(직무 중 학습)뿐만 아니라 안전상의 결과(출시 후 위험한 능력 개발)를 초래할 수 있습니다. 우리는 이러한 역동성을 대리 지표로 삼아, 익숙하지 않은 게임을 학습하는 능력을 연구합니다.
이를 위해 우리는 다소 생소하고 주로 텍스트 기반인 캠페인 게임인 Earthborne Rangers를 사용합니다. 이 게임은 전략적인 덱 빌딩(deck-building)과 전술적인 턴제 플레이(turn-by-turn play)의 조합을 요구합니다. 단 한 번의 플레이에 인간은 2~4시간이 소요되며, 숙달하려면 수십 번의 플레이가 필요할 수 있습니다.
AI 시스템은 게임을 반복적으로 플레이합니다. 이들에게는 규칙서, 카드 데이터베이스, 그리고 게임의 지도가 주어집니다. 또한 플레이 간에 유지되는 노트 작성 도구가 제공됩니다. 이들의 과제는 마지막 20%의 플레이에서 점수를 최대화하는 것입니다. 우리는 on-the-fly learning(즉각적 학습)을 발견하지 못했습니다.
기초 성능(Baseline performance)은 최신 세대의 모델들과 함께 어느 정도 향상되었습니다. GPT-5.5와 Opus 4.8은 GPT-5와 Opus 4.1보다 확실히 높은 점수를 기록했지만, 그 이후의 진전은 그리 명확하지 않습니다. 어쨌든, 이는 on-the-fly learning(즉각적 학습)이 아니라 더 나은 out-of-the-box(기본 성능)에서 기인한 것입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X 토픽: Benchmark의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기