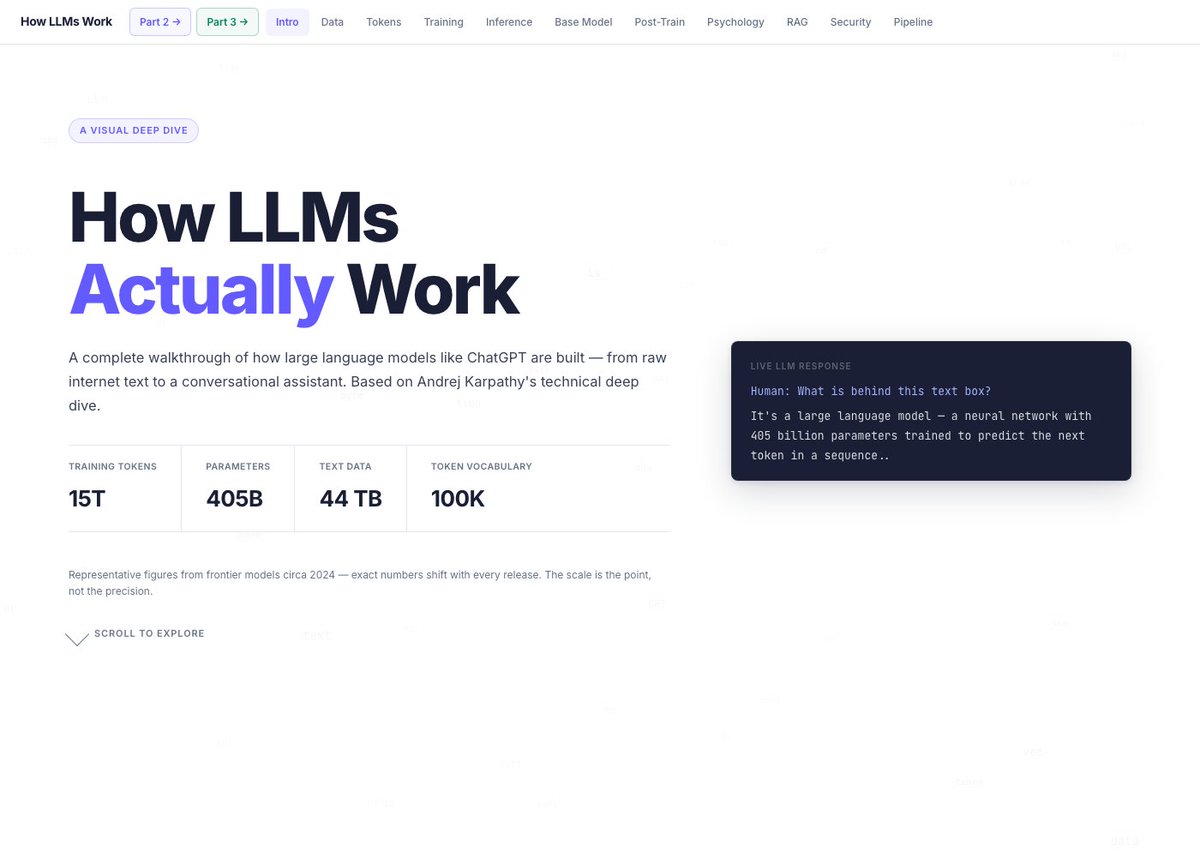
LLM의 작동 원리를 시각화한 인터랙티브 튜토리얼
요약
LLM의 작동 원리를 데이터 수집부터 사후 학습까지 전체 파이프라인으로 시각화한 인터랙티브 튜토리얼을 소개합니다. Andrej Karpathy의 강연을 바탕으로 토큰화, 신경망 학습, RAG 등 핵심 개념을 직관적으로 이해할 수 있도록 구성되었습니다.
핵심 포인트
- 데이터 수집부터 추론까지 LLM 전체 프로세스 시각화
- 토큰화, 신경망 학습, RLHF 등 핵심 기술 단계 포함
- Andrej Karpathy의 강연 기반의 명확한 흐름 제공
- RAG 및 LLM 심리학 등 심화 개념 학습 가능
대규모 언어 모델 (LLM)이 어떻게 작동하는지 이해하려고 하면, 많은 자료가 너무 논문 중심이거나 단순히 "모델은 다음 단어를 예측한다"와 같은 개념만 설명하여, 실제 전체적인 연결 고리(Full Pipeline)를 파악하기 어렵습니다.
'How LLMs Actually Work'는 대규모 언어 모델이 원시 인터넷 텍스트에서 채팅 어시스턴트로 변하는 과정을 시각화된 인터랙티브 (Interactive) 튜토리얼로 제작했습니다.
GitHub: https://t.co/ErSmz8NfDf
이 내용은 Andrej Karpathy의 《Intro to Large Language Models》 강연을 바탕으로 정리되었으며, 주요 흐름이 매우 명확합니다:
- 데이터 수집 (Data Collection): Common Crawl, FineWeb과 같은 학습 데이터가 어디서 오는지
- 토큰화 (Tokenization): 텍스트가 어떻게 BPE 서브워드 (Subword) 토큰으로 분해되는지
- 신경망 학습 (Neural Network Training): loss, 경사 하강법 (Gradient Descent), 순전파 (Forward Pass)란 무엇인지
- 추론 및 샘플링 (Inference & Sampling): 모델이 어떻게 토큰을 하나씩 생성하며 답변하는지
- 사후 학습 (Post-Training): RLHF, 지시어 튜닝 (Instruction Tuning)이 어떻게 베이스 모델 (Base Model)을 어시스턴트로 만드는지
- LLM 심리학 (LLM Psychology): 환각 (Hallucination), 컨텍스트 윈도우 (Context Window), 모델이 "무엇을 아는지"
- RAG: 임베딩 (Embedding), 벡터 검색 (Vector Search), 컨텍스트 주입 (Context Injection)의 역할
한 페이지의 웹사이트로 LLM의 전체 프로세스를 연결해서 보고 싶다면, 이 프로젝트를 먼저 살펴보기에 매우 적합합니다.
[IMG:https://pbs.twimg.com/media/HJPnt8RbcAAVbda.jpg]
AI 자동 생성 콘텐츠
본 콘텐츠는 X @wsl8297 (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기0