LLM은 이제 복잡해졌다
요약
LLM 아키텍처가 단순한 Transformer 구조를 넘어 MoE, 다양한 Attention 변형, 멀티모달 인코더 결합 등 매우 복잡해지고 있음을 설명합니다. 이는 과거 추천 시스템(Recsys)이 겪었던 복잡성 증가 과정과 유사하며, 성능 최적화가 필수적인 단계에 진입했음을 시사합니다.
핵심 포인트
- LLM 아키텍처가 MoE 및 다양한 Attention 변형을 통해 고도로 복잡해짐
- 모델의 복잡성 증가는 추천 시스템의 발전 과정과 유사한 궤적을 보임
- 성능 최적화가 단순한 선택이 아닌 시스템 유지를 위한 필수 요소가 됨
- 새로운 아키텍처 탐색을 위해서는 최적화된 베이스라인 확보가 중요함
2022년과 2023년에는 Meta에서 두 가지 큰 머신러닝 (Machine Learning) 분야가 진행되고 있었습니다. Llama로 이어진 LLM (Large Language Model) 작업은 반복되는 Transformer 모듈로 구성된 깔끔하고 매끄러운 스택이었던 반면, 추천 시스템 (Recommendation Systems) 그래프는 대조적으로 매우 복잡하고 위협적이었습니다. 다행히 업계는 LLM을 훨씬 더 복잡하게 만듦으로써 그 상황을 해결했습니다.
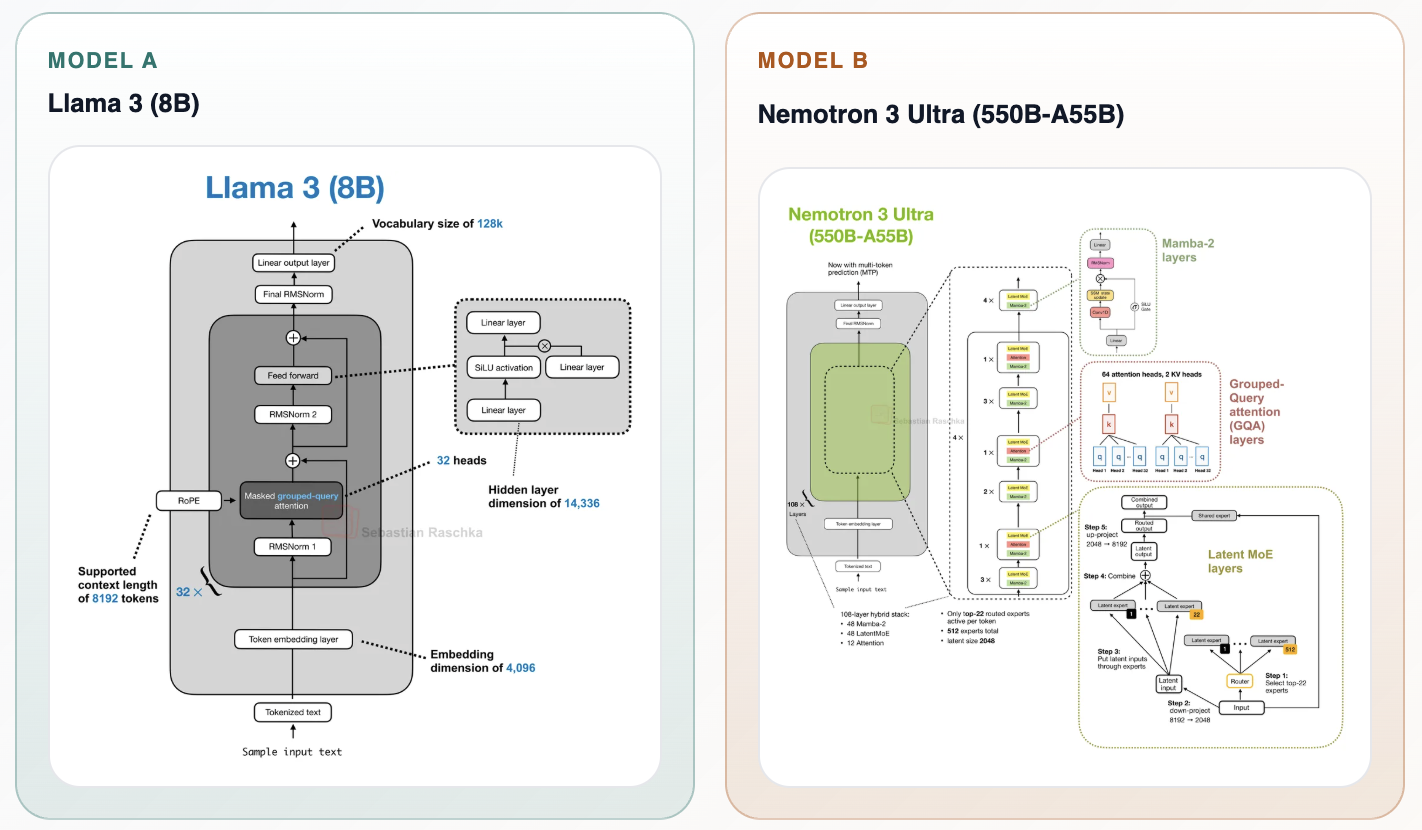
Seb Raschka는 모델 아키텍처 (Model Architectures)에 대한 훌륭한 갤러리를 유지하고 있습니다. 이를 사용하여 각 시대의 가장 뛰어난 오픈 모델인 Llama 3와 Nemotron 3 Ultra를 비교해 볼 수 있습니다.

Attention (어텐션)이 전부일 수도 있지만, 현대의 모델들은 분명히 query grouping, compressed, sparse, linear, sliding-window 등 다양한 변형들을 사용합니다. Mixture-of-Experts (MoE)는 피드포워드 레이어 (Feed-forward layers)에 선택적 라우팅 (Selective routing)을 추가했으며, 그 이후로 우리는 어텐션 블록 (Attention blocks)부터 잔차 스트림 (Residual stream)에 이르기까지 거의 모든 것에 라우팅을 시작했습니다. 비전 (Vision) 및 오디오 인코더 (Audio encoders)는 단순히 덧붙여진 형태에서 혼합된 형태로 발전했으며, 모델들은 추론 (Inference) 시점에 여러 GPU에서 실행되도록 확장되었습니다. 이는 모델 중간에 추가적인 경계를 만드는 통신 연산 (Comms ops)을 발생시킵니다.
이는 추천 시스템 (Recsys)에서 일어났던 일과 크게 다르지 않습니다. 지난 10년의 대부분 동안 추천 시스템의 기본 아키텍처는 비교적 단순한 two-tower sparse neural net (투 타워 희소 신경망)이었습니다. 복잡성은 지속적으로 능력을 향상시켜야 하는 필요성과 특히 추론 (Inference) 시에 효율성을 유지해야 하는 필요성 사이의 긴장에서 발생했습니다.
에이전트 (Agents)가 이 문제를 해결할 것이라고 가정하고 싶어질 수도 있습니다. 즉, 당신의 PyTorch 또는 JAX 정의를 Claude Telenovela나 다른 무언가에 전달하면 최적으로 융합된 커널 (Optimally fused kernels)을 생성해 줄 것이라고 말이죠. 그것이 제대로 작동하게 하려면, 생성된 것이... 맞는지 확인하기 위해 고정되고 사용 가능한 베이스라인 (Baseline)이 필요합니다.
추천 시스템 (recsys)에서 일어난 일은 성능이 하나의 최적화 (optimization) 대상인 상태와 성능이 하나의 *필수 사항 (necessity)*인 상태 사이의 간극이 매우, 매우 좁아졌다는 것입니다. 개념적으로는 베이스라인 (Baseline)을 제공하는 순수한 모델 정의를 유지할 수 있지만, 실제로 모델을 훈련하고 테스트하는 데는 상당한 리소스가 소요되며 성능 향상이 시스템을 지탱하는 핵심 요소 (load-bearing)가 됩니다.
만약 어텐션 (attention) 변형 A를 변형 B로 교체하고 싶다면, B가 10% 정도 느려지는 것은 감수할 수 있습니다. 하지만 B가 자릿수 단위 (order-of-magnitude)로 더 나빠지는 것은 아마 감당할 수 없을 것입니다. 만약 A가 융합 (fused)되고 최적화되어 있다면, B가 탐색할 가치가 있는지 판단하기 위해서라도 최소한 부분적으로 융합되고 최적화된 버전의 B가 필요합니다. 연구 반복 루프 (research iteration loop)는 단순히
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기