LangGraph의 장기 기억 (Long-Term Memory) 지원 출시
요약
LangGraph가 Python과 JavaScript 환경에서 대화 간 정보를 저장하고 회상할 수 있는 장기 기억(Long-Term Memory) 지원을 시작했습니다. 이번 업데이트는 단순한 문서 저장소 형태의 지속 가능한 기억 계층을 제공하여, 에이전트가 사용자 선호도를 학습하고 여러 스레드에 걸쳐 정보를 유지할 수 있도록 돕습니다.
핵심 포인트
- 스레드 간 지속성: 서로 다른 대화 세션 간에 정보를 저장하고 불러올 수 있는 기능 제공
- 유연한 네임스페이스: 사용자, 조직 또는 컨텍스트별로 메모리를 체계적으로 관리 가능
- JSON 기반 저장 및 검색: JSON 문서 형태로 메모리를 저장하여 조작과 콘텐츠 기반 필터링 용이
- 애플리케이션 특화 로직 지원: 일률적인 솔루션 대신 개발자가 직접 고수준 추상화를 구축할 수 있는 기본 프리미티브 제공
오늘 우리는 Python과 JavaScript 모두에서 사용할 수 있는 LangGraph의 장기 기억 (Long-Term Memory) 지원을 향한 첫 번째 단계를 발표하게 되어 기쁩니다. 장기 기억을 사용하면 대화 간에 정보를 저장하고 회상할 수 있어, 에이전트가 **피드백으로부터 학습 (learn from feedback)**하고 **사용자 선호도 (user preferences)**에 적응할 수 있습니다. 이 기능은 OSS 라이브러리의 일부이며, 모든 LangGraph Cloud 및 Studio 사용자에게 기본적으로 활성화됩니다.
기억 (Memory)에 대하여
오늘날 대부분의 AI 애플리케이션은 금붕어와 같습니다. 대화 사이의 모든 것을 잊어버리기 때문입니다. 이는 단순히 비효율적인 문제가 아니라, AI가 할 수 있는 일을 근본적으로 제한합니다.
지난 1년 동안 LangChain은 고객들과 함께 에이전트에 기억을 구축하는 작업을 진행해 왔습니다. 이 경험을 통해 우리는 중요한 사실을 깨달았습니다. AI 기억을 위한 보편적으로 완벽한 솔루션은 없다는 것입니다. 각 애플리케이션에 가장 적합한 기억 방식은 여전히 매우 애플리케이션 특화적인 로직을 포함합니다. 결과적으로, 오늘날 대부분의 "에이전트 기억 (agent memory)" 제품들은 너무 추상적입니다. 그들은 많은 프로덕션 사용자들의 요구를 충족시키지 못하는 일률적인(one-size-fits-all) 제품을 만들려고 시도합니다.
이러한 통찰력 덕분에 우리는 초기 기억 지원을 단순한 문서 저장소 (document store) 형태로 LangGraph에 구축했습니다. 고수준 추상화 (High level abstractions)는 (아래에서 보여드릴 것처럼) 그 위에 쉽게 구축될 수 있지만, 그 밑바탕에는 모든 LangGraph 애플리케이션에 내장된 단순하고 신뢰할 수 있는 지속 가능한 기억 계층 (persistent memory layer)이 존재합니다.
스레드 간 기억 (Cross-Thread Memory)
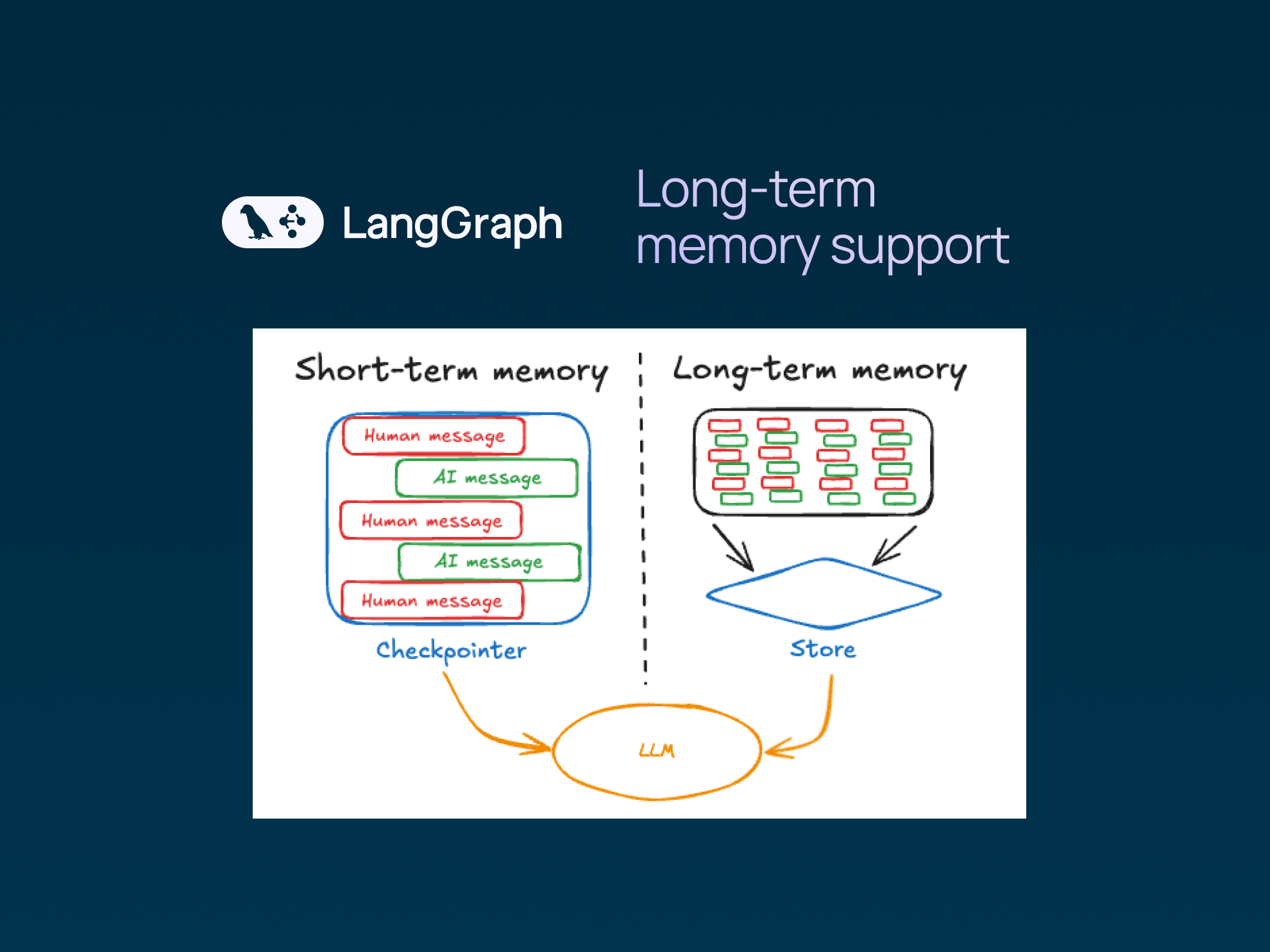
LangGraph는 체크포인터 (checkpointers)를 사용하여 단일 대화 스레드 내부의 상태를 관리하는 데 항상 탁월한 성능을 보여왔습니다. 이 "단기 기억 (short-term memory)"은 단일 대화 내에서 문맥 (context)을 유지할 수 있게 해줍니다.
오늘 우리는 그 능력을 여러 스레드에 걸쳐 확장하여, 여러분의 에이전트가 LangGraph 프레임워크 내에서 통합된 방식으로 여러 대화에 걸쳐 정보를 쉽게 기억할 수 있도록 합니다.
그 핵심은 스레드 간 기억이 저장된 기억을 저장 (put), 가져오기 (get), 그리고 **검색 (search)**할 수 있게 해주는 "단순한" 지속 가능한 문서 저장소 (persistent document store)라는 점입니다. 이러한 기본 프리미티브 (primitives)는 다음과 같은 기능을 가능하게 합니다:
스레드 간 지속성 (Cross-Thread Persistence): 서로 다른 대화 세션 간에 정보를 저장하고 불러올 수 있습니다.
유연한 네임스페이스 (Flexible Namespacing): 사용자 정의 네임스페이스를 사용하여 메모리를 구성함으로써, 서로 다른 사용자, 조직 또는 컨텍스트에 대한 데이터를 쉽게 관리할 수 있습니다.
JSON 문서 저장 (JSON Document Storage): 메모리를 JSON 문서로 저장하여 조작 및 검색을 용이하게 합니다.
콘텐츠 기반 필터링 (Content-Based Filtering): 콘텐츠를 기반으로 네임스페이스 전반에서 메모리를 검색할 수 있습니다.
이러한 개념에 대한 심도 있는 이해를 돕기 위해, 시작 방법을 안내하고 프레임워크를 제공하는 문서 세트를 준비했습니다:
- 메모리 개념을 설명하는 개념 영상
- LangGraph Python 및 JS에서의 메모리에 관한 개념 가이드
- Python 및 JS에서 스레드 간 메모리를 공유하는 방법에 대한 How-to 가이드
실질적인 구현 (Practical Implementation)
애플리케이션에 장기 기억 (Long-Term Memory)을 구현하는 데 도움을 드리기 위해, 새로운 LangGraph 템플릿을 준비했습니다:
이 LangGraph 템플릿은 자체적으로 메모리를 관리하는 챗봇 에이전트 (chatbot agent)를 보여줍니다. 이를 위한 주요 리소스는 다음과 같습니다:
- 구현 과정을 설명하는 엔드 투 엔드 (end-to-end) 튜토리얼 영상
- Python 기반의 LangGraph Memory Agent
- JavaScript 기반의 LangGraph.js Memory Agent
이 리소스들은 LangGraph에서 장기 기억을 활용하는 한 가지 방법을 보여주며, 개념과 구현 사이의 간극을 메워줍니다.
이 자료들을 탐색하고 여러분의 LangGraph 프로젝트에 장기 기억을 통합하는 실험을 해보시길 권장합니다. 언제나 그렇듯, 여러분의 피드백을 환영하며 여러분의 애플리케이션에 이러한 새로운 기능들을 어떻게 적용하실지 기대하겠습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기