새로운 구글 네트워크가 GenAI 추론 및 훈련을 위한 최적화 완료
요약
구글은 GenAI 추론 및 훈련 워크로드에 최적화된 새로운 네트워크 인프라를 개발했습니다. 이 인프라는 분산형, 컴포지블(composable) 데이터센터 아키텍처의 핵심을 이루며, 다양한 컴퓨팅/메모리/I/O 구성 요소를 하나의 랙에 배치할 수 있게 합니다. 구글은 Snap, Pony Express, Aquila 프로토콜, TiN 칩, 그리고 TPU 클러스터링을 위한 Virgo와 같은 자체 개발 기술들을 통해 데이터센터 규모의 고성능 네트워킹 역량을 입증하고 있습니다.
핵심 포인트
- 구글은 GenAI 워크로드를 위해 최적화된 분산형 및 컴포지블(composable) 데이터센터 인프라를 구축했습니다.
- 네트워크는 이제 컴퓨팅, 메모리, I/O 등 모든 구성 요소의 중심이 되며, 맞춤형 네트워크 설계가 필수적입니다.
- 구글은 Snap OS, Pony Express, Aquila 프로토콜 등 자체 개발한 다양한 네트워킹 기술 스택을 보유하고 있습니다.
- 최신 TPU 8t 훈련 클러스터는 기존 토러스 구조의 한계를 뛰어넘어 대규모 연결성을 확보했습니다.
- TPU 클러스터링에는 Inter-Chip Interconnect와 데이터센터 규모 Ethernet 패브릭인 Virgo가 사용됩니다.
새로운 구글 네트워크가 GenAI 추론 및 훈련을 위한 최적화 완료
구글의 검색 엔진, 광고, 그리고 이제 AI 모델 거대 기업에서 인프라 개발을 책임지는 네트워크 전문가가 상위에 올랐다는 것은 확실히 우연이 아닐 것입니다. 이는 구글이 우리들이 The Next Platform 에서 10 년 이상 주장해 온 분산형 데이터센터 인프라를 거의 확실하게 개발했다는 사실과 더욱 맞닿아 있습니다.
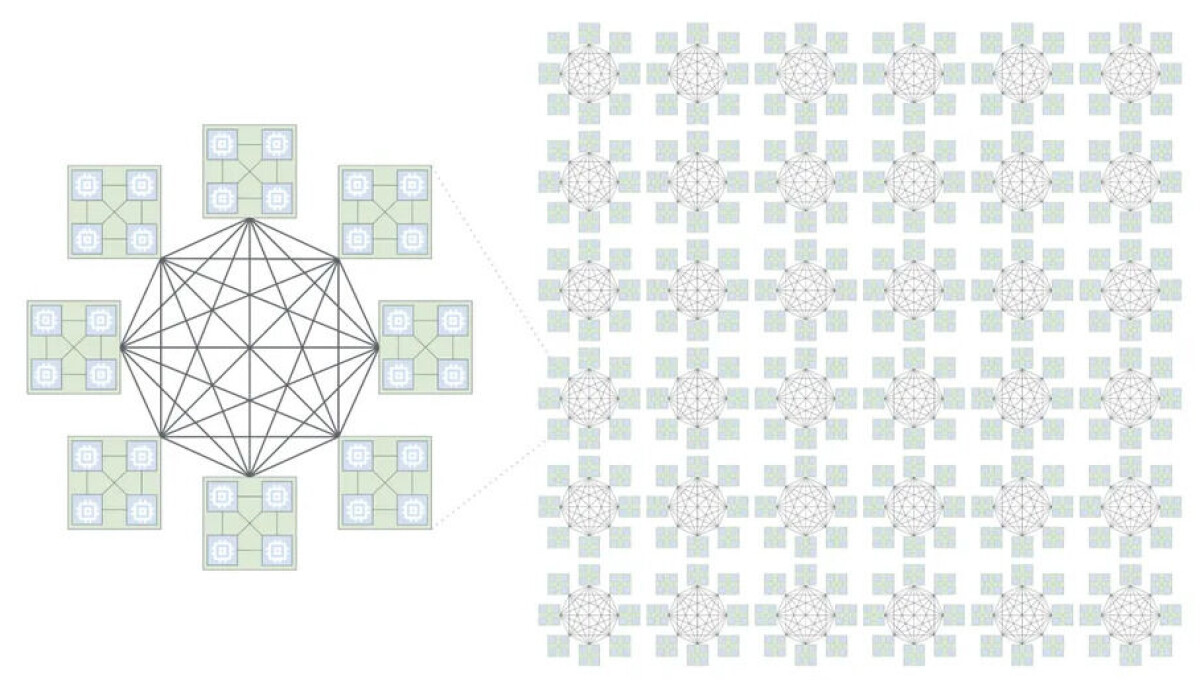
이러한 분산형 및 컴포지블 (composable) 세계에서는 네트워크가 항상 모든 것의 중심에 있으며, 특정 작업이나 일련의 작업을 수행하기 위해 단순히 튜닝된 것이 아니라 처음부터 다른 네트워크를 만드는 가치가 있는 만큼 잘 만들어져야 하는 수요가 항상 존재합니다. 이는 독립 시스템이었던 구성 요소들이 다양한 컴퓨팅/메모리, I/O, 가속기, 스토리지 구성을 가진 가상 시스템을 허용하는 랙에 분해되어 배치되는 경우 특히 그렇습니다. 작은 시스템이 많은 작업을 수행하고 필요시 하나의 클러스터가 하나의 큰 작업을 수행하는 방식에서부터 시작합니다. 단순히 컴퓨팅/메모리, I/O 및 스토저를 동일한 랙에 배치하고 PCI-Express 스위치를 여러 개 넣는 것만으로 간단하지 않습니다.
네트워크와 프로토콜의 확산은 고전적 분산 컴퓨팅과 스토리지에서 시작하여 데이터센터 범위를 넘어 데이터센터 지역 간 연결을 넘어 전 세계로 확장됩니다. 여기에는 몇 가지 예시가 있습니다. 구글은 2019 년 자체 개발한 Linux 기반 네트워크 운영 체제인 Snap 과 그 동반자 Pony Express 데이터 플레인 엔진을 공개했으며, 이는 약 2016 년부터 프로덕션에서 사용되었습니다. 4 년 전 구글은 상대적으로 작은 밀집된 클러스터에 대해 InfiniBand 스타일의 저지연을 제공하기 위해 Aquila 프로토콜을 개발했다고 발표했습니다. 또한 1,000 개의 노드가 dragonfly all-to-all 토폴로지로 연결된 클러스터에 대한 커스텀 네트워크를 구현하기 위한 동반자 Top of Rack in Network Interface Card, 또는 TiN 칩도 함께 공개되었습니다. 그리고는 Intel 과 협력하여 설계한 "Mount Evans" DPUs 를 위한 Falcon 저지연 네트워크 인터페이스 전송이 있습니다.
최근 TPU 8 발표의 일환으로 구글은 추론을 위해 맞춤화된 TPU 8i 와 훈련을 목표로 한 TPU 8t 을 발표했습니다. 이번 주에 구글이 TPU AI 컴퓨팅 엔진을 클러스터링하기 위해 발명된 Inter-Chip Interconnect 의 새로운 Boardfly 구성과 그 컴퓨팅 엔진들 간의 일정 수준 – 그리고 우리는 어떤 수준인지 확실하지 않습니다 – 메모리 일관성을 언급했습니다. 또한 TPU 포드를 포함한 기계 랙들을 연결하기 위해 구글이 개발한 "Virgo" 스케일 아웃, 데이터센터 규모 Ethernet 패브릭에 대해 깊이 있게 파고들고 싶습니다.
지금까지, 제가 원래 TPU 8 컴퓨팅 엔진 스토리에서 게시한 거대한 표를 다시 아래에 재인쇄하여 편의성을 위해 제공했습니다. 이전 세대 TPU 클러스터는 2D 토러스 또는 매우 대규모 기계 (천 개의 TPU 가 컴퓨팅 포드에 있는 경우) 에 대해 3D 토러스 인터커넥트를 사용했습니다. 한번 보십시오:
토러스 토폴로지는 이름처럼 여러 차원을 가지며, 일부 슈퍼컴퓨터 아키텍처에서 인기가 있습니다 – IBM 의 BlueGene massively parallel 기계는 3D 토러스를 사용했고 Fujitsu 가 구축한 "K" 와 "Fugaku" 슈퍼컴퓨터는 6D "Tofu" 인터커넥트를 사용했습니다. 토러스는 많은 장비를 연결하는 데 훌륭하지만, 새로운 장비를 추가하는 것은 매우 어렵습니다. 2D 토러스는 256 개의 가속기로 끝나고, 구글이 "Ironwood" TPU v7e 와 함께 사용한 3D 토러스의 경우 연결성 제한은 9,216 개의 가속기로까지 확장되었습니다. 새로운 "Sunfish" TPU 8t 훈련 클러스터에서는 이 한계가 하나의 시스템 이미지로 3D 토러스를 통해 연결된 9,600 개의 TPU 로 확장되었습니다.
토러스 토폴로지는 분산 처리에 훌륭하지만, 장치 간 홉 (hop) 이 많고 이는 장치가 많을수록 지연 시간이 높다는 것을 의미합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기