
돌아온 Claude Fable 5는 정말 약체화되었는가? 2종의 벤치마크를 통해 쉽게 해설!
요약
Anthropic의 Claude Fable 5 재출시 이후 제기된 성능 저하 논란을 2가지 벤치마크 데이터를 통해 분석합니다. 강화된 안전 분류기(Safety Classifier) 도입이 벤치마크 결과에 미치는 영향과 모델 작동 메커니즘을 설명합니다.
핵심 포인트
- Claude Fable 5는 강화된 안전 분류기를 탑재하여 재출시됨
- 안전 분류기에 의해 위험 요청 시 Opus 4.8로 자동 폴백(Fallback) 발생
- BridgeBench와 Arena.ai 벤치마크 결과가 상이하게 나타나는 원인 분석
- 안전 분류기가 코딩 및 범용 성능 지표에 미치는 영향 확인
안녕하세요! Martim입니다!
이번에는 2026년 7월 1일에 제공을 재개한 Claude Fable 5의 "성능이 정말 떨어졌는가?"라는 의문에 대해, 2가지 벤치마크 데이터를 사용하여 접근해 보겠습니다!
본 기사의 정보는 2026년 7월 3일 시점의 것입니다. Fable 5는 재개 직후라 상황이 매일 변하고 있습니다. 요금 체계, 안전 분류기 (Safety Classifier)의 동작, 벤치마크 스코어는 향후 업데이트될 가능성이 있습니다.
여러분, 이런 목소리를 접하고 계시지 않나요?
"Fable 5, 돌아오긴 했는데 약체화 (nerf) 된 거 아냐?"
"코딩할 때 쓰면 멋대로 Opus 4.8로 전환되는데......"
"벤치마크 스코어가 급감했다고 하더라"
SNS나 개발자 커뮤니티에서 떠도는 이 화제, 조사해 보니 벤치마크 종류에 따라 정반대의 결과가 나오고 있었고, 그 차이의 원인이 상당히 흥미로웠기에 공유합니다!
- Claude Fable 5란
- 제공 중단부터 재개까지의 시계열
- 안전 분류기 (Safety Classifier)와 폴백 (Fallback)의 메커니즘
- 벤치마크 비교 (1) BridgeBench -- 코딩 성능이 급감?
- 벤치마크 비교 (2) Arena.ai -- 범용 성능은 거의 유지
- 왜 두 벤치마크에서 결과가 정반대인가
- Fable 5와 Opus 4.8, 결국 어느 것을 사용해야 하는가?
- AWS 엔지니어로서의 주목 포인트
- 마치며
먼저 Fable 5가 어떤 모델인지 대략적으로 짚고 넘어가겠습니다.
Claude Fable 5는 Anthropic이 일반 공개하고 있는 모델 중에서 가장 고성능인 AI 모델입니다.
본래 "Mythos 클래스"로서 일부 승인된 조직에만 제공되던 초고성능 모델에, 안전 기제 (Safeguard)를 탑재하여 일반 사용자용으로 공개한 것이 Fable 5입니다. 내부 내용은 Claude Mythos 5와 동일하며, 차이점은 안전 분류기 (safety classifier)의 유무뿐입니다. 위험하다고 판단된 요청은 자동으로 Claude Opus 4.8로 인계되는 메커니즘이 들어 있습니다.
스펙을 Opus 4.8과 비교하면 다음과 같습니다.
| 항목 | Claude Fable 5 | Claude Opus 4.8 (참고) |
|---|---|---|
| 모델 ID | claude-fable-5 | claude-opus-4-8 |
| ... |
→ 즉, Fable 5는 Opus 4.8의 약 2배 요금이며, 특히 난이도가 높은 코딩 태스크에서 큰 차이를 보이는 모델입니다.
Fable 5는 출시 후 불과 3일 만에 제공 중단이라는, AI 업계에서도 전례 없는 사태를 경험했습니다. 상당히 격동의 3주였기에 시계열로 되돌아보겠습니다.
| 날짜 | 사건 |
|---|---|
| 6월 9일 | Claude Fable 5 · Mythos 5 일반 공개 |
| ... |
포인트는 7월 1일에 돌아온 Fable 5가 "완전히 동일한 상태"는 아니라는 점입니다. Anthropic은 재공개에 있어, 보고된 탈옥 (jailbreak) 기법을 99% 이상 차단하는 개량된 안전 분류기를 탑재했습니다.
이 안전 분류기의 강화야말로 이번 "약체화되었나?" 소동의 핵심입니다.
이 부분이 이번 기사에서 가장 중요한 파트입니다. 재개 후의 Fable 5를 이해하려면 이 안전 분류기의 메커니즘을 알아두어야 합니다.
안전 분류기란, Fable 5로 전송되는 요청을 실시간으로 모니터링하여, 위험한 카테고리에 해당한다고 판단할 경우 자동으로 차단하는 메커니즘입니다.
차단 대상 카테고리는 주로 다음 3가지입니다.
공격적 사이버 보안 -- 취약점 악용 방법, 공격 코드 생성 등 -
생물학 · 화학 -- 위험한 물질의 합성 절차 등 -
모델 증류 (Model Distillation) -- AI 모델의 지식을 부정하게 추출하는 행위
요청이 분류기에 걸리면 다음과 같은 흐름으로 처리됩니다.
- Fable 5가 아니라
Claude Opus 4.8이 대신 답변함 (폴백 (fallback)) - - 사용자에게는 폴백이 발생했다는
알림이 표시됨 - - 과금은 Fable 5의 요금이 아니라
Opus 4.8의 요금이 적용됨
6월 최초 출시 당시에도 이러한 메커니즘은 존재했으며, Anthropic의 설명에 따르면 모든 세션의 5% 미만에서만 작동한다고 되어 있었습니다. 하지만 7월 1일 재개된 버전에서는 분류기 (Classifier)가 대폭 강화되었기 때문에, 일상적인 코딩이나 디버깅에서도 오탐지 (False Positive)가 증가했다고 Anthropic이 인정했습니다.
재개 이후, 개발자 커뮤니티에서는 구체적인 폴백 (Fallback) 사례가 다수 보고되고 있습니다 (2026년 7월 3일 기준 보고).
- 데드 코드 (Dead code) 검색만으로 Opus 4.8로 전환됨
- C, C++, Rust, Win32 API 관련 코드를 다루면 폴백이 발생함
- 메모리 관리 관련 작업 시 전환됨
- 소스 코드 내에 「security」, 「vulnerable」, 「unsafe」, 「hook」과 같은 단어가 포함되어 있는 것만으로 폴백이 트리거됨
반면, "나는 한 번도 리라우팅 (Reroute)되지 않았다", "Fable 5로 하루에 60건의 PR을 낼 수 있었다"라는 목소리도 있어, 워크로드 (Workload)의 내용에 따라 체감 차이가 상당히 큰 것으로 보입니다. 보안 관련 코드를 거의 다루지 않는 개발자에게는 이전과 다름없는 사용감을 제공할 수도 있습니다.
Anthropic은 "향후 몇 주 안에 오탐지 빈도를 개선해 나가겠다"라고 설명했습니다 (2026년 7월 1일 기준 공식 발표). 실제로 어디까지 개선될지 주목해 볼 필요가 있습니다.
여기서부터가 본론입니다. 우선 코딩 특화 벤치마크인 「BridgeBench」의 결과부터 살펴보겠습니다.
BridgeBench는 AI 에이전트 서비스를 개발하는 미국의 BridgeMind AI가 공개한 오픈 소스 코딩용 벤치마크입니다. 다음 3가지 관점에서 AI 모델을 평가합니다.
| 벤치마크 명 | 평가 내용 |
|---|---|
| Hallucination (환각) | 코드 분석 시 AI가 얼마나 허위 주장을 하는가. 30개 태스크 · 6개 클러스터 · 175개 문항으로 검증 |
| ... |
BridgeMind AI는 2026년 7월 2일, 재개된 Fable 5 (7월 1일 버전)로 BridgeBench를 재실행하고 그 결과를 공식 X 계정을 통해 공개했습니다.

(https://claude.ai/api/5fdf4930-f5c5-460c-b30d-85bcaeb2db18/files/38cd68fb-1b60-405a-9c86-86e690959fd2/preview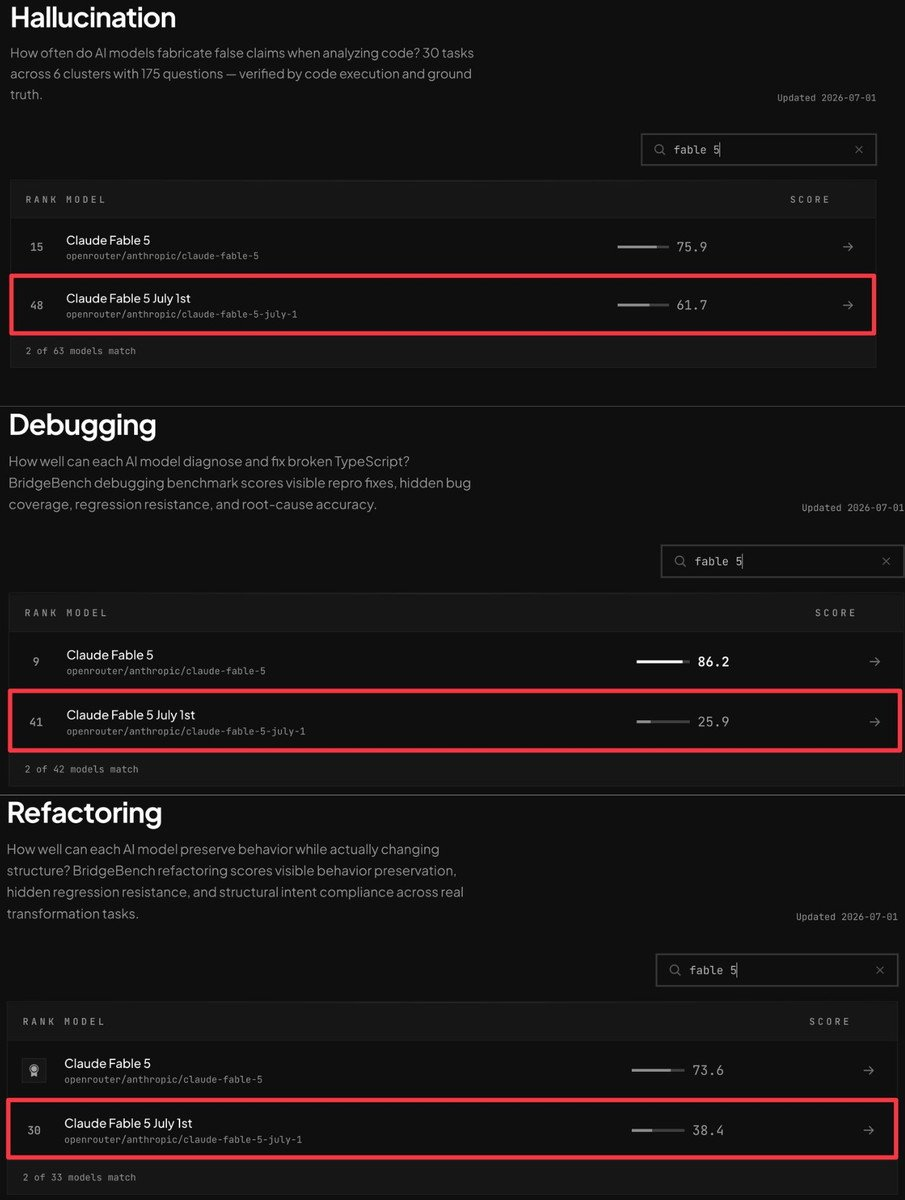
{kind=link}
{kind=link}
)
BridgeBench에서의 Claude Fable 5 점수 비교. 빨간색 테두리가 7월 1일 버전 (재개 후)의 점수. 디버깅은 86.2에서 25.9로, 리팩터링 (Refactoring)은 73.6에서 38.4로 하락했다. (출처: BridgeMind AI 공식 X 계정, 2026년 7월 2일)
다음은 점수의 한국어 정리입니다 (2026년 7월 2일 기준 BridgeBench 데이터).
| 벤치마크 | 제공 중단 전 (6월 버전) | 재개 후 (7월 1일 버전) | 변화 | 순위 변동 |
|---|---|---|---|---|
| Hallucination | 75.9 | 61.7 | -14.2 | 15위 → 48위 |
| Debugging | 86.2 | 25.9 | -60.3 | 9위 → 41위 |
| Refactoring | 73.6 | 38.4 | -35.2 | 상위권 → 30위 |
→ 즉, 디버깅 점수는 약 70% 하락했습니다. 리팩터링도 약 절반으로 줄었으며, 환각 (Hallucination) 내성도 2할 가까이 저하되었습니다.
이 숫자만 보면 "모델이 망가졌다"라고 보일 수 있지만, 실태는 다릅니다.
BridgeMind AI의 상세 분석에 따르면, TypeScript 디버깅 12개 태스크 중 9개 태스크가 Opus 4.8로 리라우팅되었으며, 리라우팅된 태스크는 모두 0점으로 집계된 것이 점수 붕괴의 주요 원인입니다. Fable 5가 실제로 태스크를 완료한 3개 태스크에서는 6월 버전과 동등한 성능을 발휘했다고 합니다.
BridgeMind AI 스스로가 이 상황을 단적으로 표현하고 있습니다.
"모델이 약해진 것이 아니다. 우리에 갇힌 (caged) 것이다"
이 표현은 매우 적절합니다. BridgeBench의 점수 하락은 "Fable 5 자체의 지능이 떨어진 것"이 아니라, "안전 분류기 (Safety Classifier)가 과잉 반응하여 Fable 5가 일을 하지 못하게 막고, 대신 Opus 4.8이 답변한" 결과라는 의미가 됩니다.
또 다른 벤치마크인 Arena.ai(구 LMArena / Chatbot Arena)의 결과는 BridgeBench와는 크게 다릅니다.
Arena.ai는 사용자가 AI 모델의 출력을 블라인드 형식으로 비교 및 투표하는 플랫폼입니다. 사용자는 어느 모델이 답변하고 있는지 모르는 상태에서 "어느 쪽이 더 나은가"를 선택하며, 그 투표 결과가 Elo 레이팅 (Elo rating)으로 집계됩니다. 2026년 7월 기준으로 누적 680만 표 이상, 366개 이상의 모델이 랭킹에 올라와 있습니다.
Arena.ai는 2026년 7월 2일, Fable 5의 서비스 중단 전후 스코어 비교를 잠정치 (Preview) 로 공개했습니다.

(images/arena-ai-comparison.png)
Arena.ai에 의한 Claude Fable 5의 Before (6월 버전 · 회색) / After (7월 버전 · 주황색) 비교. Code Arena: Frontend에서는 미세하게 감소했으나, Document (+34)나 Text: Expert (+25)에서는 오히려 스코어가 상승하고 있다. (출처: Arena.ai, 2026년 7월 2일, 잠정치)
다음은 스코어의 한국어 정리입니다 (2026년 7월 2일 기준 Arena.ai 잠정 데이터).
| 평가 카테고리 | 한국어 번역 | 서비스 중단 전 (6월 버전) | 재개 후 (7월 버전) | 변화 |
|---|---|---|---|---|
| Code Arena: Frontend | 코딩 (프론트엔드) | 1650 | 1623 | -27 |
| ... | ... | ... | ... | ... |
| → 즉, Arena.ai의 결과에서는 9개 항목 중 5개 항목에서 스코어가 미세하게 증가했으며, 전체적으로는 거의 보합세이거나 일부는 오히려 개선되었습니다. |
유일하게 명확한 저하는 Code Arena: Frontend (-27)와 Text: Coding (-18)로, 역시 코딩 계열에서 안전 분류기 (Safety Classifier)의 영향이 나타나고 있으나, BridgeBench만큼의 붕괴는 보이지 않습니다.
Arena.ai의 스코어는 2026년 7월 2일 기준의 잠정치입니다. 향후 더 많은 투표 데이터가 모임에 따라 스코어가 변동될 가능성이 있습니다.
지금까지의 결과를 정리하면 다음과 같이 요약할 수 있습니다.
| 관점 | BridgeBench | Arena.ai |
|---|---|---|
| 대상 태스크 | TypeScript 디버깅 · 리팩토링 (코딩 특화) | 텍스트 · 이미지 · 문서 · 코딩 등 다중 장르 |
| ... | ... | ... |
포인트는 두 가지가 있습니다.
첫 번째는, 안전 분류기의 오탐지 (False Positive)가 코딩 태스크에 집중되어 있다는 점입니다. BridgeBench의 태스크는 TypeScript 수정 및 리팩토링이 중심이며, 소스 코드 내에 보안 관련 어구가 포함되기 쉬워 분류기의 트리거에 걸리기 쉬운 구조입니다. 반면, Arena.ai의 범용 태스크 (텍스트 생성 · 문서 처리 · 크리에이티브 라이팅 등)에서는 분류기가 거의 반응하지 않습니다.
두 번째는, 벤치마크의 스코어 계산 방식의 차이입니다. BridgeBench에서는 폴백 (Fallback, Opus 4.8이 답변한 경우)을 0점으로 처리하기 때문에, 리루트율 (Reroute rate)이 그대로 스코어 붕괴로 직결됩니다. 반면 Arena.ai는 인간의 블라인드 투표이므로, Opus 4.8이 답변하더라도 Opus 4.8 나름의 품질이 평가에 반영됩니다.
→ 즉, "Fable 5의 성능이 떨어진 것"이 아니라, "Fable 5가 일할 기회를 안전 분류기에 의해 제한받고 있는 것" 이 실태입니다. 모델의 두뇌는 변하지 않았습니다.
여기까지 읽으면, "그럼 지금 Fable 5와 Opus 4.8 중 어느 것을 사용해야 하는가?"라는 의문이 생길 것입니다.
개인적으로 조사한 범위 내에서의 결론은, "기본적으로는 Opus 4.8을 디폴트 (Default)로 설정하고, 길고 복잡한 고난도 태스크만 Fable 5에 맡기는 것"이 현시점에서 가장 합리적인 구분법 입니다 (2026년 7월 3일 기준 판단).
대규모 코드베이스 이관 및 리팩터링 (Refactoring) -- 수만 행에서 수백만 행 규모의 작업. 실례로 결제 서비스인 Stripe는 5,000만 행 규모의 Ruby 코드베이스 이관을 Fable 5를 통해 하루 만에 압축 완료했다고 보고했습니다.
멀티 스텝의 장시간 에이전트 실행 (Multi-step Long-running Agent Execution) -- 수 시간에서 수일에 걸친 태스크. 계획 수립부터 서브 에이전트(Sub-agent)로의 위임, 자기 점검(Self-check)까지 자율적으로 진행 가능.
복잡한 아키텍처 설계 -- 정답이 자명하지 않은 의사결정 태스크나, 여러 요구사항을 동시에 균형 있게 고려해야 하는 설계 판단.
고정밀도가 필요한 심층 분석 및 리서치 -- 논문 수준의 조사나, 문서를 가로지르는 깊이 있는 분석.
일상적인 코딩 -- 1개 함수의 리팩터링, 테스트 생성, PR 리뷰 등 스코프가 명확한 짧은 작업.
레이턴시(Latency)나 비용을 중시하는 상황 -- 요금은 Fable 5의 절반 수준. 단순한 태스크에서는 Opus 4.8로도 충분한 품질이 나옵니다.
사이버 보안 관련 코드를 다루는 상황 -- Fable 5를 사용할 경우 안전 분류기(Safety Classifier)에 걸릴 리스크가 있으므로, Opus 4.8을 직접 사용하는 것이 더 안정적입니다.
| 항목 | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| 입력 (100만 토큰당) | $10 | $5 |
| ... | ... |
표면적으로는 Fable 5가 Opus 4.8보다 2배 비싸지만, "태스크당 비용"으로 생각하면 이야기가 달라집니다. Fable 5는 어려운 태스크를 더 적은 턴(Turn)과 적은 토큰으로 완료하는 경향이 있어, 재시도(Retry) 횟수가 줄어드는 만큼 결과적으로 Opus 4.8과 큰 차이가 없는 경우도 있다고 합니다.
반대로 간단한 태스크에 Fable 5를 사용하면 오버스펙이 되어 비용만 낭비하게 됩니다. "전부 Fable 5에게 맡기면 되잖아"라고 할 수 없는 점이 까다로운 부분입니다.
2026년 7월 7일까지는 Pro, Max, Team 및 일부 Enterprise 플랜에서 주간 이용 한도의 최대 50%까지 Fable 5를 추가 요금 없이 사용할 수 있습니다. 7월 8일 이후에는 이용 크레딧(종량제 과금) 방식으로 전환될 예정입니다.
단, Anthropic은 "용량이 확보되는 대로 구독의 표준 기능으로서 Fable 5를 복구할 의향"도 밝히고 있습니다. 이 부분은 향후 발표를 주의 깊게 살펴볼 필요가 있습니다.
AWS를 평소에 사용하는 입장에서 가장 궁금한 포인트는 이 지점입니다. Fable 5는 Amazon Bedrock에서도 이용 가능해졌으며, AWS 환경에서의 활용을 고려하는 분들을 위해 요점을 정리합니다 (2026년 7월 3일 기준 정보).
Fable 5는 7월 1일부터 Amazon Bedrock에서도 액세스가 복구되었습니다. DevelopersIO의 검증 기사에 따르면, 제공 리전은 최초 출시 당시의 2개 리전(us-east-1, eu-north-1)에서 5개 리전으로 확대된 것이 확인되었습니다.
이용 방법은 다음 두 가지입니다.
Amazon Bedrock -- 기존 AWS 환경에서 추론 워크로드(Inference Workload)를 확장할 수 있습니다. Converse API 또는 Anthropic Messages API를 통해 호출 가능합니다.
Claude Platform on AWS -- Anthropic의 네이티브한 플랫폼 경험을 AWS 상에서 이용할 수 있습니다.
참고로 DevelopersIO의 검증 기사에서는 Bedrock Mantle (/anthropic/v1/messages 엔드포인트)를 통한 호출은 404 에러가 발생하여, 7월 1일 시점에서는 동작하지 않았다고 보고되었습니다. 현재로서는 Converse API (bedrock-runtime)를 통한 이용이 확실합니다.
Fable 5를 이용하려면 30일간의 데이터 보유 (provider_data_share)에 동의해야 합니다. 이는 Bedrock의 "Data Retention API"를 통해 모드를 설정해야 하며, 이 설정을 하지 않으면 모델 호출 자체가 불가능합니다.
→ 즉, 제로 데이터 보유 (Zero Data Retention, ZDR) 정책으로 운영 중인 팀은 Fable 5 도입 전에 보안 및 컴플라이언스(Compliance) 팀과의 조율이 필요합니다. 이 점은 다른 Claude 모델과는 다른 중요한 차이점입니다.
API를 통해 Fable 5를 이용할 경우, 안전 분류기(Safety Classifier)가 요청을 차단하면 stop_reason: "refusal"이 HTTP 200으로 반환됩니다. 에러가 아니라 정상 응답(Normal Response)으로 반환된다는 점에 주의해야 합니다.
Bedrock을 사용할 경우에는, 이 폴백(fallback) 처리를 적절하게 설계하는 것이 요구됩니다. 구체적으로는 다음과 같은 대응이 고려될 수 있습니다.
stop_reason을 모니터링하고, `
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기