Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
LangChain Blog 128건필터 해제

에이전트 성능 개선의 핵심은 실행 과정에서 발생하는 트레이스(Traces) 데이터를 마이닝하여 지속적 학습 루프를 구축하는 것입니다. 이를 위해 관측 가능성(Observability) 확보와 대규모 데이터 큐레이션 역량이 필수적입니다.

OpenWiki는 코딩 에이전트가 코드베이스를 더 잘 이해할 수 있도록 저장소 문서를 자동으로 생성하고 유지 관리하는 오픈 소스 도구입니다. 코드가 변경될 때마다 위키를 최신 상태로 업데이트하여 에이전트에게 구조화된 컨텍스트를 제공합니다.

LangChain이 채팅 로그에서 구조화된 정보를 추출하는 LLM의 능력을 측정하기 위한 새로운 'Chat Extraction' 데이터셋을 공개했습니다. 이 데이터셋은 비구조화된 텍스트 분류 및 기계 판독 가능한 정보 생성 능력을 테스트하여 LLM 애플리케이션 개발의 실질적인 도전 과제를 다룹니다.

LLM 에이전트의 핵심 역량인 도구 사용(Tool Use) 능력을 평가하기 위한 네 가지 새로운 벤치마크 환경을 소개합니다. 계획 수립, 함수 호출, 사전 학습된 편향 극복 능력을 테스트하며 다양한 모델의 성능 차이를 분석합니다.

에이전트의 컨텍스트 부패 문제를 해결하기 위해 재귀적 언어 모델(RLM)을 활용하는 방법을 소개합니다. RLM은 컨텍스트를 모델 윈도우에 직접 넣는 대신 REPL 환경에서 코드를 실행하여 대규모 데이터를 효율적으로 처리합니다.

Pendo는 LangSmith를 활용하여 사용자 행동 데이터를 분석하고 코드를 자동으로 수정하는 제품 에이전트 'Novus'를 구축했습니다. Novus는 세션 리플레이와 행동 데이터를 기반으로 사용성 문제를 감지하고, 근본 원인을 진단하여 즉각적인 코드 수정을 제안함으로써 제품 피드백 루프를 완성합니다.

Deep Agents의 동적 서브에이전트 도입에 따른 보안 문제를 해결하기 위한 설계 방식을 다룹니다. 프롬프트 인젝션 위험을 고려하여 실행 격리, 권한 격리, 지속 가능한 일시 중지를 핵심 요구사항으로 정의하고 WebAssembly를 활용한 해결책을 제시합니다.

Harbor와 LangChain을 통합하여 에이전트 성능을 평가하기 위한 통합 스택을 소개합니다. 격리된 샌드박스 환경에서 에이전트를 병렬로 실행하고, LangSmith를 통해 트레이스를 분석하여 평가 결과의 원인을 파악할 수 있습니다.

Deep Agents가 대규모 작업의 안정성과 컨텍스트 관리를 위해 '동적 서브에이전트' 방식을 도입했습니다. 이는 단순 도구 호출 대신 에이전트가 직접 오케스트레이션 스크립트를 작성하여 실행하는 프로그래밍 방식의 접근법입니다.
LangChain의 LangSmith 업데이트와 에이전트 개발 생명주기(ADLC)를 다루는 뉴스레터입니다. Fleet On-Call Copilot, Computer Use 기능, Deep Agents Rubrics 등 에이전트 운영 및 평가를 위한 최신 도구와 방법론을 소개합니다.

SmithDB에서 전문 검색을 지원하기 위한 역색인(Inverted index)의 구축, 압축, 쿼리 과정을 설명합니다. 특히 대규모 JSON 페이로드를 효율적으로 처리하기 위해 JSON 테이프 방식을 활용한 평탄화 기법과 토큰화 과정을 다룹니다.

Klarna는 LangGraph와 LangSmith를 활용하여 8,500만 명의 사용자를 지원하는 AI 어시스턴트를 구축했습니다. 이 시스템은 멀티 에이전트 아키텍처를 통해 고객 지원 업무를 자동화하며, 700명의 직원과 맞먹는 효율성을 보여줍니다.
.png)
AI 에이전트가 이전 경험을 통해 학습할 수 있도록 돕는 메모리(Memory) 구축 방법을 설명합니다. 단기 메모리와 장기 메모리의 개념적 차이를 정의하고, LangSmith를 활용하여 트레이스를 메모리로 변환하는 구현 프로세스를 다룹니다.

Kubernetes 환경에서 셀프 호스팅 LangSmith의 운영 복잡성을 줄여주는 'Mission Control'을 소개합니다. 클러스터 내부에서 단일 인터페이스를 통해 구성, 상태 확인, 진단 및 문제 해결을 통합 관리할 수 있습니다.
성공적인 AI 에이전트 운영을 위한 구축, 테스트, 배포, 모니터링의 4단계 개발 라이프사이클을 소개합니다. 단순한 데모를 넘어 반복 가능하고 체계적인 시스템을 구축하는 방법론을 다룹니다.

Monday.com이 LangSmith를 활용하여 AI 에이전트의 품질을 개발 초기 단계부터 검증하는 '평가 주도 개발 프레임워크' 구축 사례를 소개합니다. LangGraph 기반 ReAct 에이전트의 자율성으로 인한 오류를 방지하기 위해 오프라인 평가와 실시간 모니터링을 결합한 이중 계층 접근 방식을 제안합니다.

LangChain이 코딩 에이전트의 급격한 사용량 증가로 인한 비용 폭주를 방지하기 위해 LangSmith LLM Gateway를 구축했습니다. 이 게이트웨이는 조직, 워크스페이스, 사용자별로 예산을 설정하고 실시간으로 지출을 모니터링하여 비용 예측 가능성을 높입니다.

LangSmith가 LLM 평가자와 인간의 선호도를 일치시키는 새로운 기능인 'Align Evals'를 출시했습니다. 이 기능은 LLM-as-a-judge 평가 프로세스를 간소화하고, 평가 프롬프트 개선 및 정렬 점수 확인을 통해 고품질의 평가 환경을 구축하도록 돕습니다.
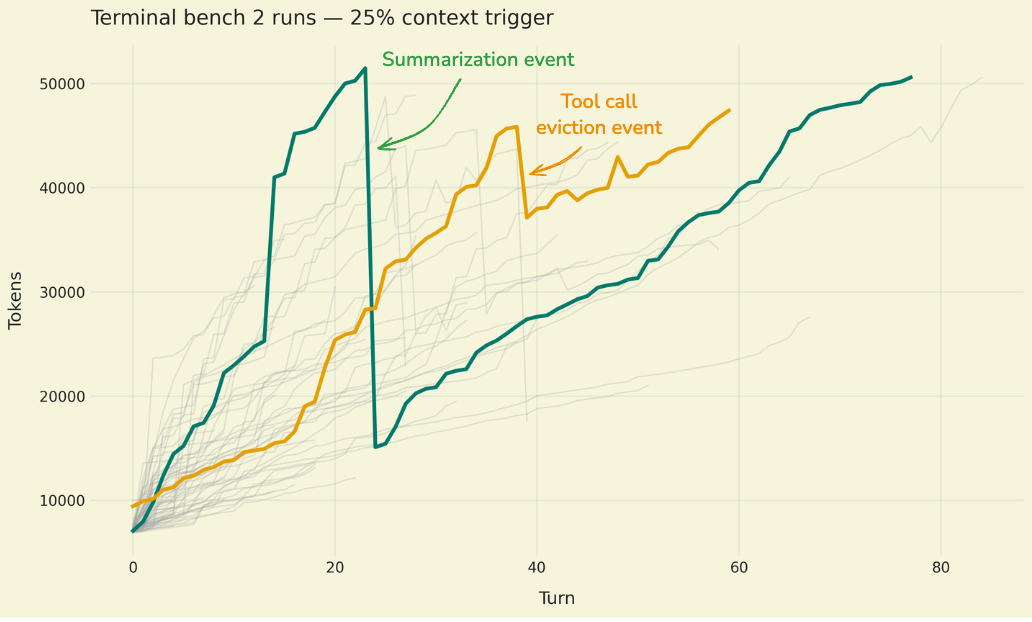
Deep Agents SDK는 AI 에이전트의 컨텍스트 부패를 방지하고 메모리 제약을 관리하기 위한 컨텍스트 관리 기술을 제공합니다. 파일 시스템 오프로딩과 요약 기술을 통해 대규모 작업 중에도 효율적인 컨텍스트 유지가 가능합니다.

에이전트 엔지니어링은 비결정론적인 LLM 시스템을 신뢰할 수 있는 프로덕션 환경으로 구축하는 반복적인 프로세스를 의미합니다. 이는 제품 사고, 엔지니어링, 데이터 과학이라는 세 가지 핵심 기술 세트가 결합된 새로운 학문 분야입니다.