Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 447건필터 해제

NVIDIA가 Hugging Face를 통해 최적화된 Qwen3.6-27B 모델을 출시했습니다. 이 모델은 262K의 긴 컨텍스트를 지원하며, Blackwell GPU에 최적화된 NVFP4 양자화 기술을 적용했습니다.

서울대학교 연구진이 가중치 공간 산술을 활용해 도메인 변화와 작업 지식을 분리하는 DART 기술을 발표했습니다. 이를 통해 단 한 번의 시연만으로 로봇 정책을 새로운 카메라 환경이나 로봇 형태에 빠르게 적응시킬 수 있습니다.

Meta가 Hugging Face를 통해 R3D-Bench를 출시했습니다. 이 벤치마크는 1인칭 시점의 RGB-D 비디오를 활용하여 정량적인 3D 공간 추론 능력을 평가합니다.

PD-분리형 MoE 서빙 최적화를 위한 전문가 지역성 인식 디코딩 라우팅 기술인 ELDR를 소개합니다. 프리필 단계의 전문가 시그니처를 활용해 디코딩 요청을 라우팅함으로써 vLLM 환경에서 TPOT을 최대 13.9% 절감합니다.
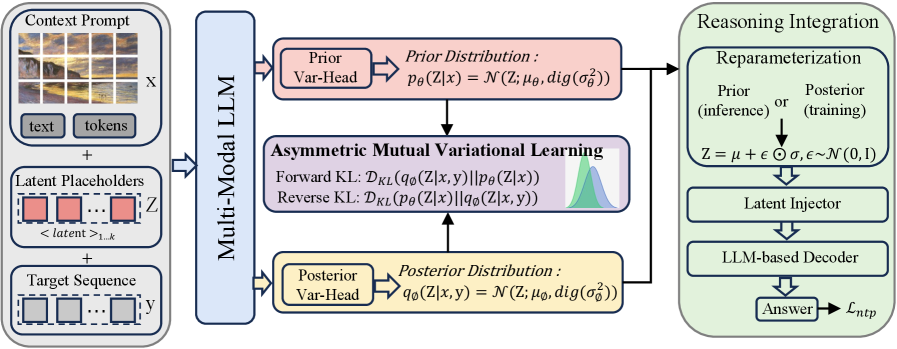
AMVL은 멀티모달 LLM에서 안정적인 연속적 추론을 가능하게 하는 새로운 방법론입니다. 비대칭 이중 KL 손실을 통해 잠재적 추론을 정렬함으로써 정답 유출을 방지하고 성능을 크게 향상시킵니다.

PerceptionRubrics는 10,000개 이상의 원자적 루브릭을 활용해 멀티모달 모델의 인지 능력을 평가하는 새로운 벤치마크입니다. 게이트형 점수 산정 방식을 통해 환각 현상에 엄격한 벌점을 부여하며, 오픈 소스와 폐쇄형 모델 간의 인지 격차를 분석합니다.

스트리밍 비디오 생성 워크로드에 최적화된 최초의 서빙 시스템인 TurboServe를 소개합니다. 이 시스템은 청크당 지연 시간을 37.5% 줄이고 GPU 운영 비용을 37.2% 절감하는 성능을 보여줍니다.

Microsoft가 Hugging Face에 안전 정렬된 Llama 모델인 HARC를 출시했습니다. 이 모델은 유해성 신호와 거부 신호를 결합하여 탈옥 시도를 효과적으로 방어하면서도 유용성을 유지합니다.

피드포워드 모델을 통해 3D 주석 없이도 이미지로부터 3D 장면을 인스턴스 구조화된 토큰 그룹으로 분해하는 기술을 소개합니다. 단 한 번의 포워드 패스로 객체의 정체성을 파악하여 재구성, 세그멘테이션, 조작을 가능하게 합니다.
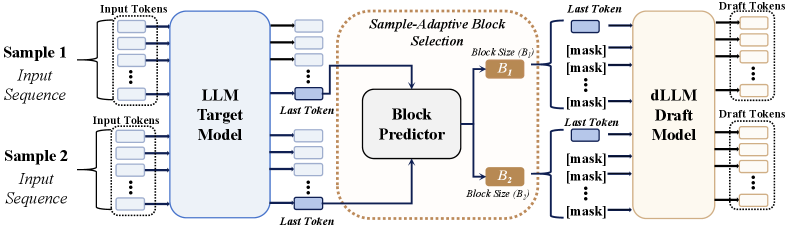
BlockPilot은 추측적 디코딩(Speculative Decoding) 시 고정된 블록 크기 대신 프리필링 표현을 기반으로 최적의 블록 크기를 예측하는 기술입니다. Qwen3-4B 모델 실험 결과, 수락 길이를 높이고 속도를 4.20배 향상시키는 성과를 보였습니다.

NVIDIA가 Hugging Face를 통해 양자화된 Mistral Medium 3.5 모델을 출시했습니다. 이 모델은 128B 파라미터를 가진 밀집 모델로, Blackwell GPU에서 NVFP4 정밀도를 통해 높은 정확도를 유지하며 실행됩니다.

로봇 공학 미세 조정 후에도 Embodied AI 모델이 상식과 세상에 대한 지식을 유지하는지 평가하는 새로운 벤치마크인 Act2Answer를 소개합니다. 모델이 행동을 통해 지식을 유지하고 있는지 검증하는 데 중점을 둡니다.

Docker 없이 코드를 평가할 수 있는 환경 독립적인 코딩 에이전트용 패치 검증기입니다. 기존 오픈 소스 검증기 대비 뛰어난 성능을 보이며, 강화학습을 통해 SWE-bench Verified에서 62.0%의 높은 성적을 기록했습니다.

BeyondArena는 표 형식 파운데이션 모델(Tabular FMs)의 범용성을 검증하기 위해 IID, 시계열, 그룹화된 태스크를 포함한 142개 데이터셋 벤치마크를 제시합니다. 연구 결과, Tabular FMs는 소규모 동질적 데이터에서는 강점을 보이나, 복잡한 과제에서는 여전히 트리 기반 및 딥러닝 모델이 우세함을 밝혀냈습니다.
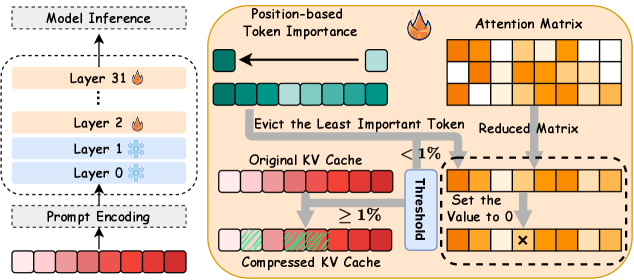
ReFreeKV는 KV 캐시 압축 시 수동 임계값 설정이 필요 없는 적응형 프루닝 기술을 제안합니다. 입력 복잡도에 따라 예산을 자동으로 조정하여 LLaMA, Mistral, Qwen 모델에서 높은 성능을 유지합니다.

Meta가 AI 에이전트의 터미널 활용 능력을 평가하기 위한 벤치마크인 TUA-Bench를 공개했습니다. 이 벤치마크는 이메일, 문서, 과학 도구 등 120개의 실제 환경 작업을 포함하며, 최신 모델인 Claude Opus조차 낮은 성능을 보였습니다.

Ai2가 지구 관측을 위한 114M 파라미터 규모의 비전 파운데이션 모델인 OlmoEarth Base를 Hugging Face에 출시했습니다. 이 모델은 Sentinel-1, Sentinel-2, Landsat 이미지를 활용하여 학습되었습니다.

LLM 에이전트가 행동을 멈춰야 할 시점을 판단하는 능력을 평가하고, 적시 기권(timely abstention)의 중요성을 다룹니다. CONVOLVE 기술을 통해 미세 조정 없이도 에이전트의 기권 비율을 크게 향상시킬 수 있음을 보여줍니다.
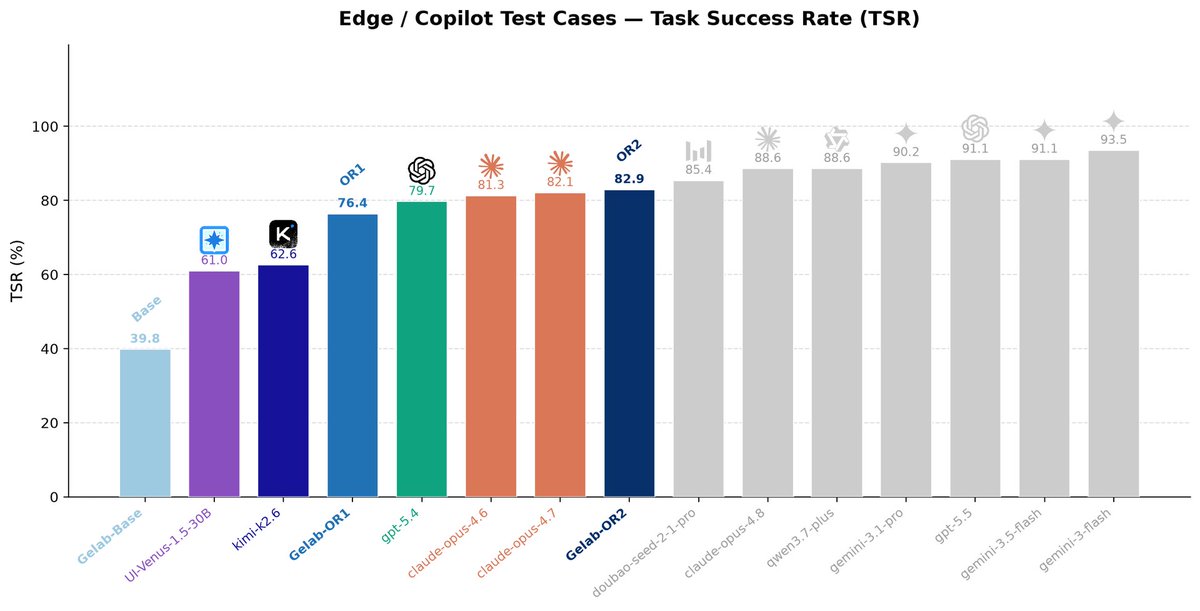
Microsoft가 Hugging Face에 새로운 GUI 에이전트를 출시했습니다. 4B 파라미터 규모의 모델임에도 불구하고 Sico-Evolution의 작업 성공률을 82.9%까지 끌어올리며 뛰어난 성능을 입증했습니다.

Agents-A1은 35B MoE 모델임에도 불구하고 에이전트 호라이즌 확장을 통해 1조 파라미터급 성능을 구현했습니다. 45K 토큰 궤적과 멀티 티처 증류 기법을 사용하여 6개의 이질적인 도메인을 통합한 것이 특징입니다.