Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
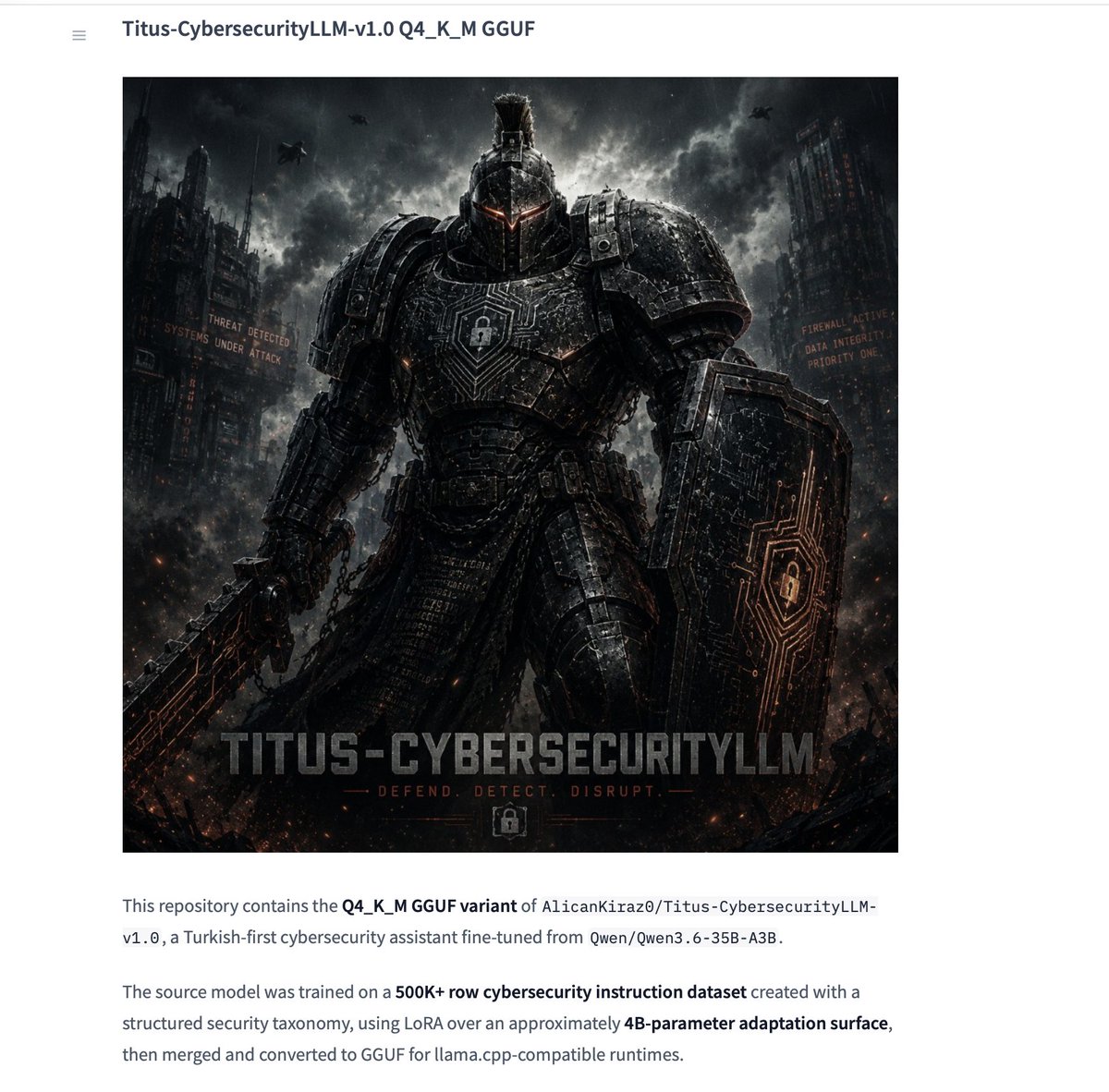
사이버 보안에 특화된 Agentic LLM인 TitusLLM-35B-A3B-v1의 GGUF 버전이 출시되었습니다. Qwen3.6-35B-A3B MoE 모델을 기반으로 50만 개의 보안 데이터셋을 사용하여 미세 조정되었습니다.
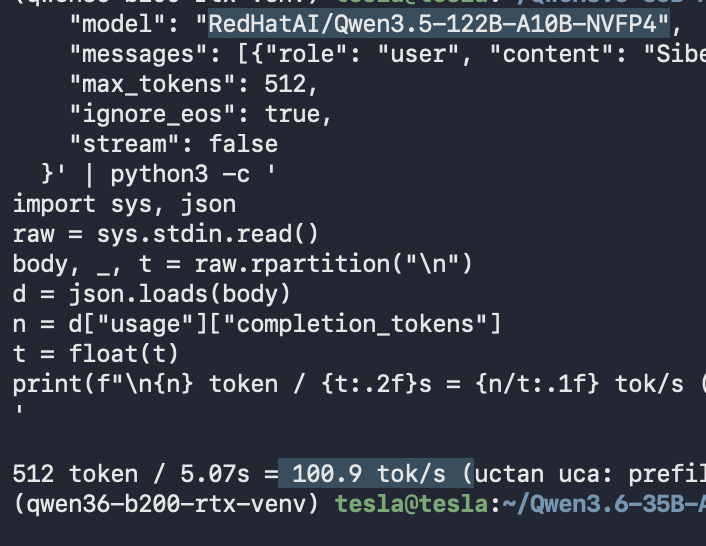
RedHatAI의 Qwen3.5-122B-A10B-NVFP4 모델을 RTX Pro 6000 환경에서 구동하여 초당 100 토큰의 속도를 달성했습니다.
Vibecoding을 위해 Opus와 GPT-5.5 모델을 교차 활용하는 최적의 워크플로우를 제안합니다. Opus는 창의적인 아키텍처 설계와 구현에, GPT-5.5는 요구사항 검토와 코드 가독성 및 지속 가능성 검증에 특화하여 배치합니다.
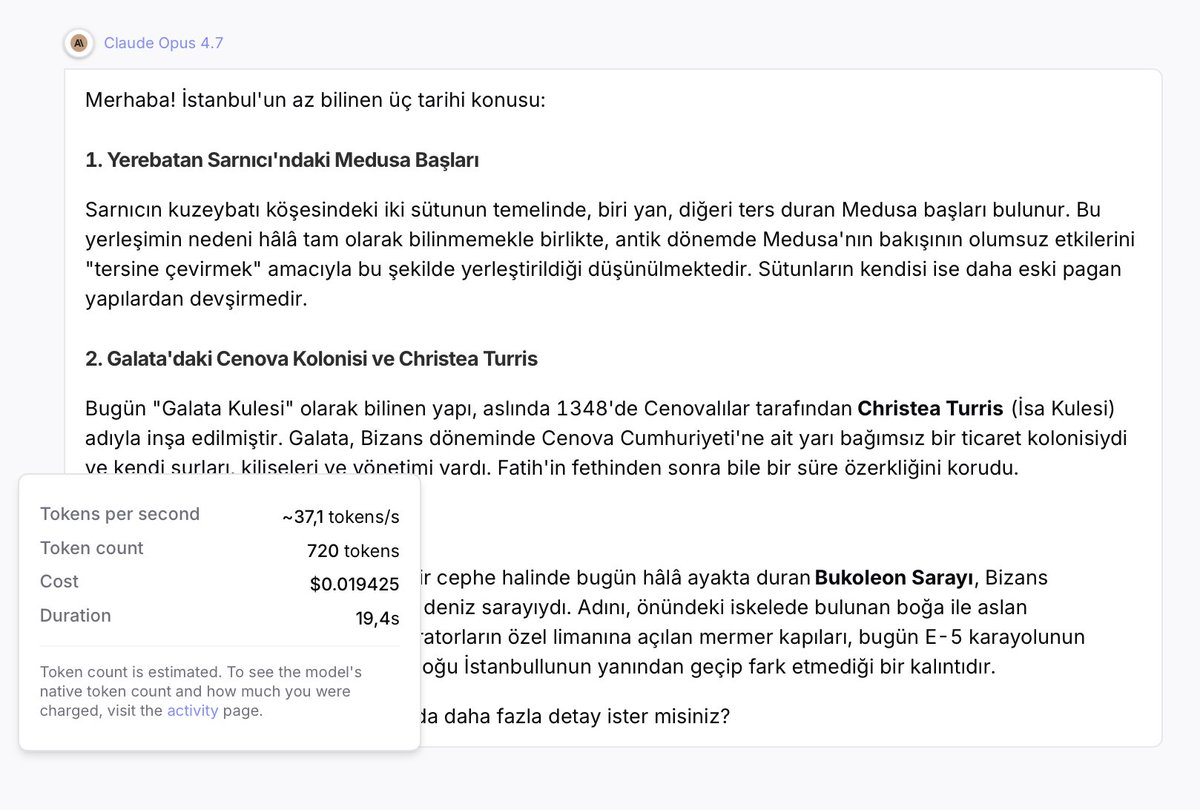
Opus 4.8 High 모델과 Opus 4.7 High 모델의 성능 및 비용 지표를 비교합니다. Opus 4.8 High가 속도와 토큰 생성량 측면에서 우위를 보임을 보여줍니다.

Opus 4.8 High와 Opus 4.7 High 모델의 성능을 벤치마크한 결과입니다. 데이터 스트림 내 고유 사용자 ID 계산을 위한 확률적 자료구조 알고리즘 설계 능력을 평가했습니다.

Opus 4.8 High 모델과 Opus 4.7 High 모델의 성능을 비교한 벤치마크 결과입니다. 복잡한 분산 시스템 설계 문제를 해결하는 능력과 토큰 생성 속도, 비용, 처리량 등을 정량적으로 비교했습니다.
Qwen3.6-35B-A3B 모델을 기반으로 아첨(Sycophancy) 현상을 억제하기 위한 전체 미세 조정(Full Finetune) 모델을 개발했습니다. 군사 지휘 통제 센터와 같이 객관적이고 냉철한 판단이 필요한 환경을 위해 설계되었습니다.
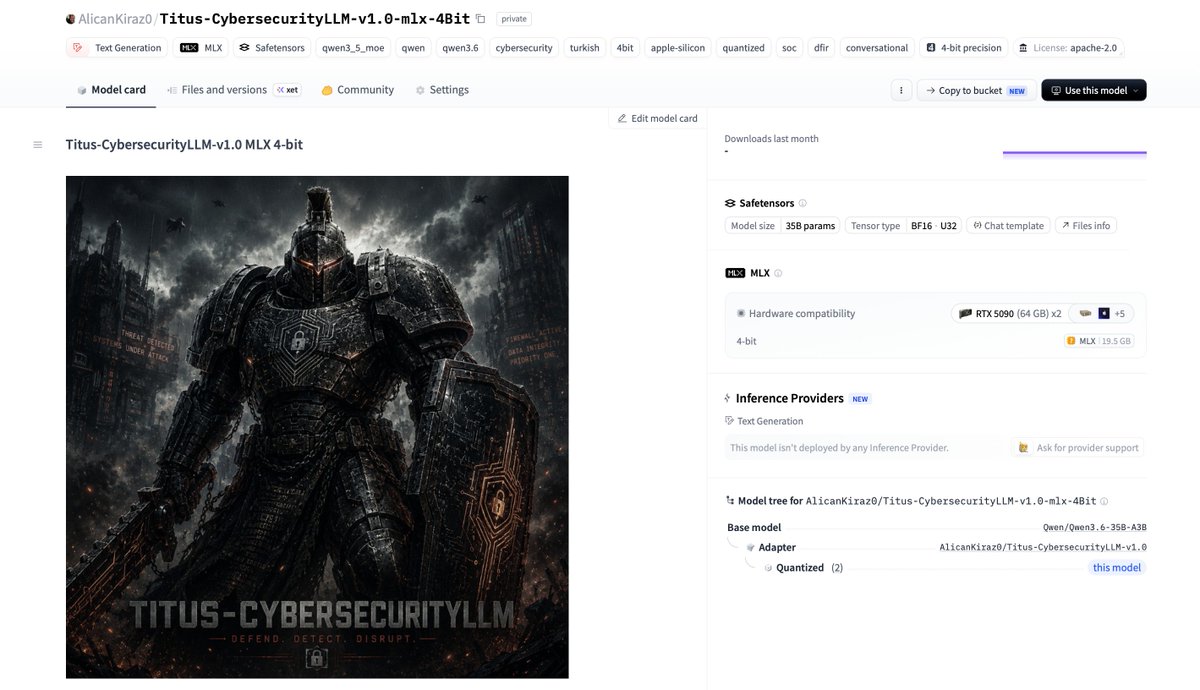
Qwen3.6-35B-A3B MoE 모델을 기반으로 구축된 사이버 보안 특화 에이전트 모델 TitusLLM-v1을 공개합니다. 50만 개 이상의 데이터셋과 LoRA 미세 조정을 통해 SOC 운영 및 탐지 엔지니어링 등 보안 시나리오에 최적화된 성능을 제공합니다.

새로운 사이버 보안 특화 모델인 Titus-CybersecurityLLM이 mlx 및 gguf 형식으로 출시됩니다. 이 모델은 Qwen3.6-35B-A3B를 기반으로 약 4B 파라미터를 파인튜닝하여 설계되었습니다.
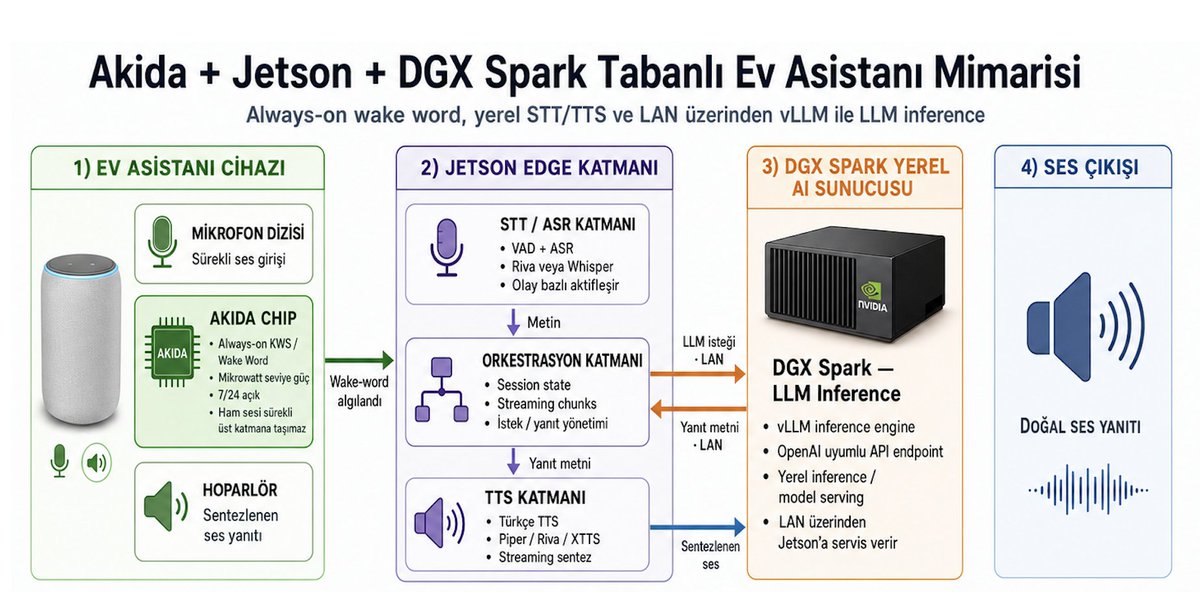
AKD1000 Brain Chip을 활용한 뉴로모픽 프로세서 연구와 JarvisX 홈 어시스턴트 적용 사례를 소개합니다. TSMC 28nm 공정 기반의 이 칩은 SNN과 CNN을 모두 지원하며, 초저전력 웨이크 워드 인식(KWS) 구현에 최적화되어 있습니다.

TSMC 28nm 공정으로 제작된 AKD1000 뉴로모픽 프로세서에 대한 소개입니다. Cortex-M4 호스트와 80개의 NPU를 탑재하여 SNN과 CNN을 모두 지원합니다.
Qwen 3.7-max가 Opus 4.7 및 GPT-5.5를 상대로 진행된 에이전트 작업 테스트에서 우수한 성능을 기록했습니다. 테트리스 봇 작성 및 자기 개선 능력을 평가하는 벤치마크를 통해 모델의 성능을 비교했습니다.
Zhipu AI의 플래그십 모델인 GLM-5.1-HighSpeed가 출시되었습니다. 이 모델은 모델 크기를 줄이지 않고도 초당 400 토큰이라는 압도적인 추론 속도를 구현하여 LLM API의 새로운 성능 기준을 제시합니다.
Qwen3.5-LiveTranslate는 3,500개 이상의 언어 쌍을 지원하는 차세대 실시간 통역 모델입니다. 초저지연 성능과 시각적 문맥 파악, 실시간 음성 복제 기능을 통해 언어 장벽을 혁신적으로 해소하는 것을 목표로 합니다.
AI 기술의 다음 단계로 오케스트레이션(Orchestration)과 모니터링의 중요성이 강조될 것이라고 전망합니다. 특히 비용 최적화를 위해 마스터-서브 에이전트(master-sub agent) 구조가 널리 도입될 것이며, 이는 기업들의 AI 전환 전략에 핵심적인 변화를 가져올 것입니다.
Composer 2.5 및 Opus 4.7 모델의 최적 사용 사례와 보고서 품질 출력에 대한 벤치마크 결과를 다룹니다. 해당 데이터는 AlicanKiraz0의 보고서를 인용하여 모델의 성능을 비교합니다.
Atlas 로봇이 50파운드 무게의 미니 냉장고를 운반하는 데 성공했습니다. 이 과정에서 가상 환경을 통해 수백만 시간 동안 동작을 연습했으며, 단순한 손 동작을 넘어 전신을 활용하는 훈련 정책을 적용했습니다.
GPT-5.5 Extended Pro를 활용하여 프로젝트 분석 보고서와 액션 플랜을 생성한 실험 결과입니다. Composer 2.5 Fast 모델을 사용했을 때 66K의 컨텍스트를 소모하며 약 0.5~1.5달러의 비용과 3~4분의 시간이 소요되었습니다.
Composer 2.5와 Opus 4.7 Max의 디버깅 및 코드 리뷰 성능을 비교한 벤치마크 결과입니다. Opus 4.7 Max는 더 큰 컨텍스트와 높은 비용 및 시간이 소요되지만, Composer 2.5는 상대적으로 저렴하고 빠른 작업 속도를 보여줍니다.
Composer 2.5와 Opus 4.7 Max의 디버깅 및 코드 리뷰 성능을 비교한 벤치마크 결과입니다. Opus 4.7 Max는 더 높은 비용과 시간이 소요되지만, Composer 2.5는 상대적으로 저렴하고 빠른 작업 속도를 보여줍니다.