Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
Hugging Face Blog 277건필터 해제

Gemma 3n이 오픈 소스 생태계에서 완전히 사용 가능해졌습니다!
Google이 온디바이스 환경에 최적화된 멀티모달 대규모 언어 모델(LLM)인 Gemma 3n을 오픈 소스 생태계에 공개했습니다. 이 모델은 이미지, 텍스트, 오디오, 비디오 입력을 모두 지원하며, 특히 메모리 효율성을 극대화하여 실제 파라미터 수보다 훨씬 적은 VRAM으로 구동할 수 있는 것이 특징입니다. Gemma 3n은 transformers, llama.cpp, ollama 등 주요 오픈 소스 라이브러리에 즉시 통합되어 사용 가능합니다.

Granite 4.1 LLMs: How They're Built
IBM의 Granite 4.1은 약 15조 토큰을 사용하여 구축된 고성능 디코더 전용 LLM 제품군(3B, 8B, 30B)입니다. 이 모델들은 일반적인 사전 학습 외에도, 고품질 데이터 정제 및 다단계 강화학습 파이프라인을 거쳐 수학, 코딩, 명령어 수행 능력을 체계적으로 향상시켰습니다. 특히, 최대 512K 토큰까지 확장된 긴 컨텍스트 처리 능력과 효율적인 아키텍처 설계를 통해 이전 세대 모델 대비 성능 및 효율성을 높였습니다.
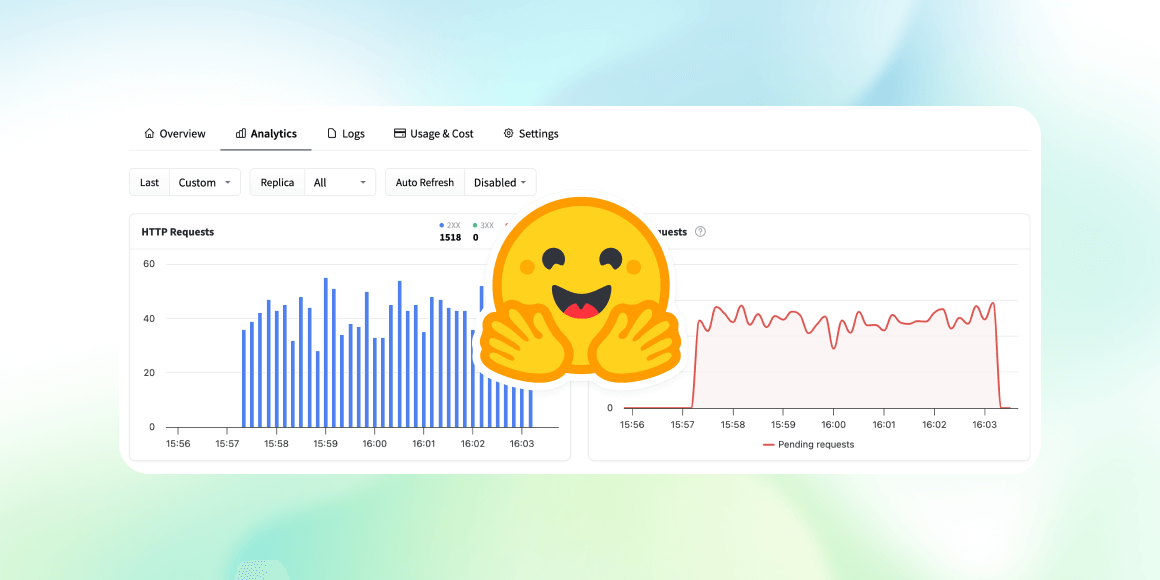
Inference Endpoints 의 새로운 분석 기능
본 기술 기사는 AI 모델의 배포 및 운영에 필수적인 'Inference Endpoints' 분석 기능 개선 사항을 소개합니다. 주요 업데이트는 실시간 지표 제공, 커스터마이징 가능한 시간 범위 설정 및 자동 새로 고침 기능 추가, 그리고 리플리카(Replica) 라이프사이클 추적 뷰 도입입니다. 이러한 개선을 통해 사용자는 엔드포인트의 성능과 상태를 더욱 빠르고 정확하게 모니터링하고 디버깅할 수 있게 되었습니다.

Welcome Gemma 3: Google's all new multimodal, multilingual, long context open
구글이 새로운 오픈 웨이트 LLM 시리즈인 Gemma 3를 출시했습니다. 이 모델은 최대 128k 토큰의 긴 컨텍스트 창을 지원하며, 이미지와 텍스트를 모두 처리할 수 있는 멀티모달 기능을 갖추고 있습니다. 또한 140개 이상의 언어를 지원하여 다국어 성능이 크게 향상되었습니다. Gemma 3는 다양한 크기(1B~27B)로 제공되며, 특히 긴 컨텍스트와 멀티모달리티를 효율적으로 구현하기 위해 RoPE 업그레이드 및 KV 캐시 최적화 등 기술적인 개선을 이루었습니다.

π0 및 π0-FAST: 범용 로봇 제어를 위한 비전-언어-액션 모델
본 기사는 로봇의 범용 지능을 구현하기 위한 Vision-Language-Action (VLA) 모델인 π0와 π0-FAST를 소개합니다. 이 모델들은 기존 LLM/VLM이 부족했던 물리적 세계와의 상호작용 능력을 보완하며, 대규모 사전 학습과 흐름 매칭 기반 액션 생성을 통해 다양한 로봇 플랫폼에서 정교한 조작 작업을 수행할 수 있도록 설계되었습니다. π0는 7개 로봇 플랫폼의 68가지 고유 작업 데이터로 훈련되어 범용적인 로봇 제어 능력을 입증했습니다.

The Open Arabic LLM Leaderboard 2
아랍어 지원 LLM의 증가에 따라, 커뮤니티는 기존의 제한적이고 불투명했던 벤치마크 방식을 개선하기 위해 오픈 아랍어 LLM 리더보드(OALL)를 구축했습니다. 이 리더보드는 읽기 이해, 감정 분석 등 다양한 과제를 포함하는 여러 벤치마크를 통합하여 모델 평가의 투명성과 접근성을 높였습니다. 이후 SDAIA와 Inception 등의 주도 하에 Balsam Index, AraGen, SEAL과 같은 전문적이고 심층적인 아랍어 LLM 리더보드들이 연이어 등장하며 아랍어 AI 커뮤니티의 핵심 플랫폼으로 자리매김했습니다.

Open-source DeepResearch – Freeing our search agents
본 기사는 OpenAI가 공개한 'DeepResearch' 시스템을 분석하고, 이를 오픈소스로 재현하려는 목표를 제시합니다. DeepResearch는 LLM과 에이전트 프레임워크를 결합하여 웹 검색 및 다단계 추론 능력을 극대화하며, 특히 GAIA와 같은 복잡한 벤치마크에서 단일 LLM보다 월등히 높은 성능을 보여줍니다. 필자들은 이 강력한 시스템의 핵심인 '에이전트 프레임워크'를 오픈소스로 공개하여 연구 커뮤니티가 이를 재현하고 발전시킬 수 있도록 하는 것을 목표로 합니다.

Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
대규모 언어 모델(LLM)의 추론 과정은 'prefill' 단계와 'decode' 단계로 나뉘며, 이 두 단계는 계산 방식과 성능 최적화 전략이 다릅니다. Prefill 단계에서는 모든 입력 프롬프트 토큰을 병렬로 처리할 수 있어 GPU 연산 집약적이며 높은 컴퓨팅 활용도를 보입니다. 반면, Decode 단계는 개별 요청 수준에서 병렬화가 어려워 메모리 대역폭에 의해 속도가 제한되며, 이 경우 여러 요청의 배치 처리를 통해 GPU 활용도를 높이는 것이 중요합니다.

Gaia2 and ARE: Empowering the community to study agents
본 기사는 에이전트 벤치마크를 한 단계 발전시킨 Gaia2와 오픈 Meta Agents Research Environments (ARE) 프레임워크를 소개합니다. Gaia2는 기존의 읽기 전용 검색 중심에서 벗어나, 쓰기 및 상호작용 행동, 모호성 처리, 시간적 추론 등 실세계에 가까운 복잡한 에이전트 능력을 평가하는 데 중점을 둡니다. 이 새로운 환경은 스마트폰 시뮬레이션과 구조화된 트레이스 기록을 통해 실제 사용자 경험을 반영하며, 다양한 최신 LLM 모델들의 성능을 비교 분석합니다.

DeepResearch Bench에서 오픈 소스 Llama Nemotron 모델 측정
NVIDIA의 AI-Q Blueprint는 Llama 3.3 기반의 오픈소스 LLM과 검색 기능을 결합하여 DeepResearch Bench에서 최고 성능을 달성했습니다. 이 아키텍처는 Llama-3.3-Nemotron-Super-49B-v1.5와 같은 최적화된 모델을 사용하여 긴 컨텍스트 이해, 복잡한 에이전트 추론, 그리고 신뢰할 수 있는 다중 출처 합성 능력을 보여줍니다. AI-Q는 투명성(추론 과정 및 근거 제시)과 효율성을 유지하면서도 폐쇄형 대안에 필적하거나 능가하는 고급 연구 워크플로우를 오픈소스 환경에서 구현할 수 있음을 입증했습니다.

LeRobot v0.4.0: Supercharging OSS Robot Learning
LeRobot v0.4.0은 오픈소스 로봇 학습 분야에 대규모 업그레이드를 제공하며, 확장성이 강화된 Datasets v3.0, 강력한 VLA 모델(LIBERO 등) 지원, 그리고 새로운 플러그인 시스템을 통해 하드웨어 통합이 용이해졌습니다. 또한, 데이터셋 편집 및 병합 기능을 추가하고, 데이터를 모델과 로봇 하드웨어 양쪽 모두에 맞게 처리하는 범용 'Processor' 파이프라인을 도입하여 전체적인 워크플로우의 효율성과 접근성을 극대화했습니다.

How to Build a Healthcare Robot from Simulation to Deployment with NVIDIA Isaac
본 기술 기사는 NVIDIA Isaac for Healthcare 프레임워크를 활용하여 의료용 로봇을 시뮬레이션 환경에서 실제 하드웨어까지 배포하는 엔드투엔드 워크플로우를 소개합니다. 이 워크플로우는 데이터 수집(LeRobot), 모델 훈련(Isaac Lab), 정책 배포(RTI DDS)의 3단계 파이프라인으로 구성되어, 시뮬레이션과 실제 세계 데이터를 결합하여 로봇 자율성을 확보하는 것이 핵심입니다. 특히, 이 접근 방식은 합성적으로 생성된 데이터가 전체 훈련 데이터의 대부분을 차지할 수 있게 함으로써, 기존 의료 로봇 개발의 주요 병목이었던 '데이터 격차' 문제를 해결하고 프로토타입 개발 시간을 혁신적으로 단축시킵니다.

DeepSeek-V4: a million-token context that agents can actually use
DeepSeek-V4는 에이전트 워크로드에 최적화된 100만 토큰 컨텍스트 창을 제공하며, 기존 모델의 긴 실행 과정에서의 불안정성 문제를 해결했습니다. 이 모델은 Compressed Sparse Attention (CSA)와 Heavily Compressed Attention (HCA) 같은 혁신적인 아키텍처를 통해 KV 캐시 메모리 사용량을 극적으로 줄이고, 단일 토큰 추론 FLOPs도 크게 절감하여 효율성을 높였습니다. 또한, V4는 도구 호출이 포함된 다중 턴 에이전트 워크플로우에서 전체 추론 역사를 일관되게 유지하는 능력을 갖추어 복잡한 장기 작업을 수행할 수 있게 합니다.

1 Billion Classifications
본 기술 기사는 대규모 분류 및 임베딩 작업(1B+ 요청 규모)의 비용과 지연 시간을 체계적으로 분석하고 최적화하는 방법을 설명합니다. 단순히 모델을 사용하는 것을 넘어, 다양한 하드웨어 옵션, 배포 방법론, 로드 테스트 도구 등 4가지 핵심 구성 요소를 통합하여 전체 시스템의 효율성을 극대화하는 프레임워크를 제시합니다. 이를 통해 사용자는 특정 규모의 작업을 가장 저렴하고 빠르게 처리할 수 있는 최적의 아키텍처 설계를 할 수 있습니다.

Fixing Open LLM Leaderboard with Math-Verify
본 기술 기사는 Open LLM Leaderboard의 MATH-Hard 평가 과정에서 발견된 여러 문제점들을 개선한 'Math-Verify'라는 새로운 파서를 소개합니다. 기존 리더보드는 모델이 답변 형식을 지키지 않거나, 복잡한 수학적 표현(예: 매개변수 방정식, 행렬)을 정확히 파싱하지 못하는 등 심각한 오류를 안고 있었습니다. Math-Verify는 이러한 형식 준수 문제와 다양한 수학적 구조의 파싱 문제를 해결하여, LLM 모델들의 실제 수학 능력을 더욱 공정하고 견고하게 평가할 수 있도록 개선했습니다.

추론 엔드포인트를 사용한 원격 VAE (Remote VAEs for decoding with Inference Endpoints 🤗)
본 기술 기사는 고해상도 이미지 및 비디오 합성을 위한 잠재 공간 확산 모델 사용 시 발생하는 VAE 디코더의 높은 메모리 소비 문제를 해결하기 위한 방법을 제시합니다. 이 문제에 대한 해결책으로, 디코딩 프로세스를 원격 엔드포인트(Remote Endpoint)로 위임하는 실험적인 기능을 소개합니다. 이를 통해 사용자들은 로컬 GPU 환경에서 발생하던 메모리 제약이나 지연 시간 오버헤드를 피하고 안정적으로 모델을 구동할 수 있습니다. 이 기능은 `diffusers` 라이브러리에 추가되었으며, `remote_decode` 헬퍼 함수를 사용하여 다양한 확산 모델(Stable Diffusion, Flux 등)의 디코딩 과정에 적용할 수 있습니다. 또한, 원격 VAE 사용의 장점 중 하나로 여러 생성 요청을 대기열화(Queueing)하여 처리할 수 있다는 점을 강조합니다.

엣지에서 LLM 추론: React Native를 이용해 휴대폰에서 LLM을 실행하는 쉽고 재미있는 가이드!
본 가이드는 React Native를 사용하여 스마트폰에서 LLM을 구동하는 방법을 안내합니다. DeepSeek R1이나 Qwen 2.5와 같은 소형 모델(1~3B 파라미터)을 활용하여, 사용자의 기기 내에서 완전히 오프라인으로 작동하는 개인 정보 보호에 초점을 맞춘 대화형 AI 앱을 구축할 수 있습니다. 핵심은 `llama.rn` 바인딩과 GGUF 파일을 효율적으로 로드하여 모바일 환경에 최적화된 LLM 추론 기능을 구현하는 것입니다.

아라비어 리더보드: 아라비어 지시 따르기 소개, AraGen 업데이트 및 더 많은 정보
본 기사는 아라비어 LLM 평가를 위한 통합 플랫폼인 '아라비어-리더보드 스페이스'의 업데이트 내용을 다룹니다. 핵심은 생성적 작업(generative tasks)을 평가하는 첫 번째 벤치마크인 AraGen과, 공개적으로 이용 가능한 아라비어 지시 따르기(Arabic Instruction Following) 리더보드의 출시입니다. 이 플랫폼은 다양한 모달리티를 포괄하며, 최신 AraGen-03-25 릴리스는 질문 답변, 추론 등 세부 영역을 확장하고 평가 프레임워크의 일관성과 신뢰성을 높이는 데 중점을 두었습니다.

Open R1: 업데이트 #2
Open R1 프로젝트는 DeepSeek R1의 누락된 부분, 특히 훈련 파이프라인과 합성 데이터 구축에 초점을 맞추고 있습니다. 이번 업데이트에서는 수학적 추론을 위한 대규모 데이터셋인 OpenR1-Math-220k를 공개했습니다. 이 데이터셋은 Numina와 협력하여 512개의 H100 클러스터에서 로컬로 생성되었으며, 자동 필터링 및 고급 평가 시스템(Math Verify)을 통해 높은 품질의 추론 트레이스를 제공합니다. 또한, 최신 LLM 기술(SGLang 등)을 활용하여 데이터 생성 속도를 획기적으로 높이는 방법론도 공유했습니다.

Chunks 에서 Blocks 으로: Hub 의 업로드 및 다운로드 가속화
Hugging Face Hub의 업로드 및 다운로드 가속화를 위해 기존의 파일 중심 접근 방식에서 '청크(Chunk)' 기반 시스템을 넘어선 '블록(Block)' 기반 아키텍처로 진화합니다. 이 새로운 시스템은 데이터를 64MB 단위의 블록으로 그룹화하고, 이를 통해 콘텐츠 주소 지정 저장소(CAS)에 기록되는 항목 수를 대폭 줄입니다. 또한, 샤드(Shards)와 키 청크(Key Chunks)를 도입하여 데이터 전송 및 메타데이터 관리의 확장성 문제를 해결하며, 궁극적으로 AI 빌더들의 협업과 실험 속도를 획기적으로 개선하는 것을 목표로 합니다.
이 피드 구독하기
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.