Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
Zenn AI 1311건필터 해제

AI OCR의 출력을 그대로 믿어서는 안 된다 — 「확인 필요 UI」를 만들기 위한 설계
AI OCR 서비스 개발 시 Gemini API를 활용하여 시리얼 번호를 추출하는 파이프라인 설계 방식을 다룹니다. AI의 불확실한 출력을 그대로 노출하지 않고, 확신도(confidence) 정보를 포함한 구조화된 데이터를 UI에 반영하여 사용자의 검증을 유도하는 설계 전략을 제안합니다.

왜 Skill이 필요한가
AI 에이전트 설계 시 Skill 메커니즘을 활용하여 컨텍스트 효율, 유지보수성, 테스트 용이성을 개선하는 방법을 다룹니다. Skill은 필요한 시점에만 컨텍스트를 삽입하여 LLM의 추론 성능을 최적화합니다.
Agentforce Self-Service 설정 가이드: Help Agent를 Summer '26에 출시하기까지의 과정과 주의점
Salesforce가 Summer '26에 출시한 Agentforce Self-Service와 Help Agent의 설정 가이드를 소개합니다. AI 에이전트를 통해 고객이 스스로 문제를 해결할 수 있는 동적이고 개인화된 셀프서비스 환경 구축 방법을 다룹니다.
개인이 만든 MCP 서버를 공식 레지스트리에 공개하기까지 — npm publish와 mcp-publisher의 2단계 과정
TypeScript 기반 MCP 서버를 npm과 공식 MCP 레지스트리에 배포하는 2단계 과정을 상세히 설명합니다. npm 패키지 발행 후 mcp-publisher를 통해 메타데이터를 등록하는 절차와 주의사항을 다룹니다.
Skill.md의 description을 잘못 작성하면 스킬이 작동하지 않는 이유
AI 에이전트의 '스킬(Skill)' 작동 여부는 본문 내용보다 `description` 필드에 크게 의존합니다. 에이전트는 모든 스킬의 상세 내용을 상시 참조하지 않고, 오직 Level 1 메타데이터인 `description`만을 검색 인덱스로 활용하여 스킬을 선택하기 때문입니다. 따라서 `description`은 모호하지 않게 작성해야 하며, 영어로 작성하는 것이 매칭 정확도 측면에서 가장 안정적입니다.
freee의 전표를 Claude Code로 모두 처리해봤습니다 [반두 플러그인으로 10분 설정]
일본 회계 시스템(freee) 전표 처리를 자동화하는 과정에서 발생하는 API 오류 및 반복적인 설정 문제를 해결하기 위해 '반두'라는 플러그인을 개발했습니다. 이 플러그인은 사업소 선택 누락 방지, 수정 패턴 기억 등 사용자 경험을 개선하여 월말 전표 작업 시간을 획기적으로 단축시킵니다.

LeRobot — 학습된 정책을 실기에서 구동하기 (평가)
본 기사는 LeRobot 프레임워크를 사용하여 학습된 정책을 실제 로봇 하드웨어(SO-101)에 구동하고 평가하는 방법을 다룹니다. 자율 추론 모드를 통해 정책의 성능을 확인하며, 성공적인 평가를 위해 데이터셋 녹화 및 실행 시 주의해야 할 여러 기술적 사항들을 안내합니다.
AI 시대 사내 자료는 '리치 HTML'로 남겨야 강력하다: AWS Amplify를 활용한 인증형 내부 문서 공개
AI 시대에는 기획 결과물을 Markdown 대신 리치 HTML로 남기는 것이 전달력 측면에서 훨씬 유리합니다. 특히 Tailwind가 포함된 단일 HTML은 AI 요청에 의해 쉽게 생성되며, CSS와 JS를 인라인으로 포함하여 운영의 편리성을 극대화할 수 있습니다. AWS Amplify 빌드 기능을 활용하면 모크업을 푸시할 때마다 자동으로 최신 목차 페이지를 유지할 수 있어 관리 효율성이 높습니다.
완전 무료 로컬 AI로 '이모티콘으로 웃는' 자작 걸(Gal) 목소리를 흔들림 없이 양산하는 이야기
본 글은 상상하는 대로 목소리를 만들고 제어할 수 있는 로컬 TTS 시스템 구축 과정을 다룹니다. 기존의 음성 선택 방식의 한계를 극복하기 위해, Irodori-TTS로 '목소리 설계'를 하고 GPT-SoVITS로 이를 안정적으로 복제하여 비언어적 표현까지 구현하는 방법을 제시합니다.
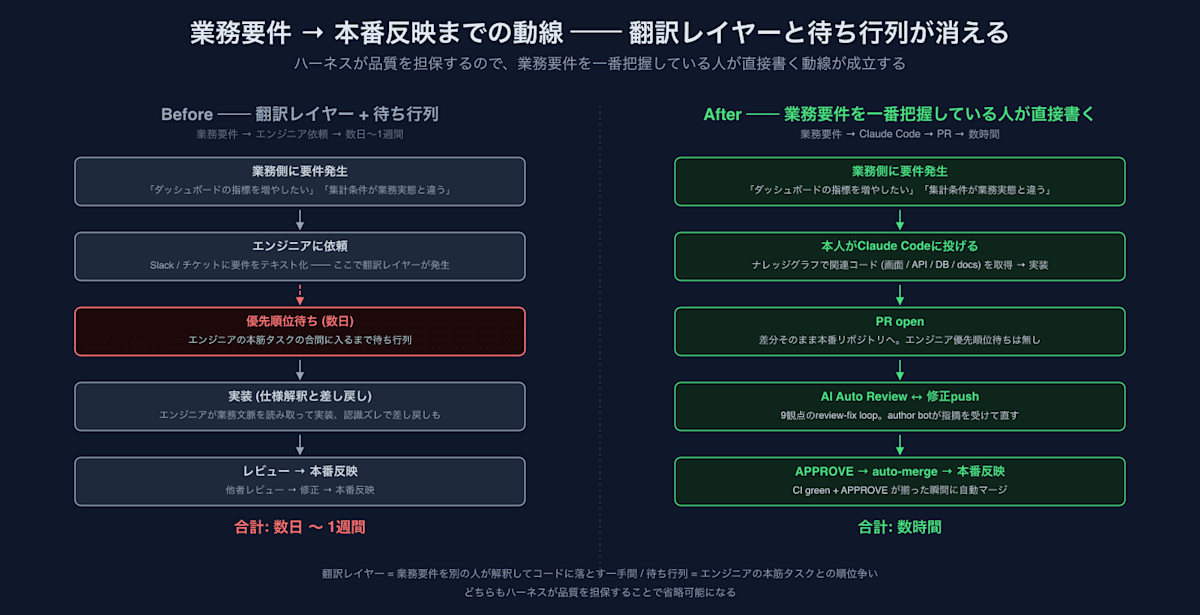
비엔지니어가 운영 환경에 PR을 제출하고, 하네스(Harness)가 품질을 담보한다 ── 개수(改修) 단계의 민주화 (연재 Part 5)
비엔지니어가 운영 환경에 직접 PR을 제출할 수 있도록 지원하는 AI 하네스(Harness) 시스템의 사례를 소개합니다. 지식 그래프, Auto Review, Self-Healing 메커니즘을 통해 품질을 담보하며, 단순 수정을 넘어 복잡한 기능 추가까지 가능한 개발 민주화 과정을 다룹니다.
형태를 외우지 말고 의도를 외워라——Cross-Embodiment Training이란 무엇인가: 마인크래프트의 Mob이 알려주는
Cross-Embodiment Training은 서로 다른 형태의 로봇 데이터를 통합 학습하여 범용적인 움직임을 획득하는 기술입니다. 신체의 형태가 아닌 '태스크의 의도'와 '어포던스(Affordance)'를 학습함으로써 미지의 환경과 신체로의 전이를 실현합니다.

[Google Workspace에서의 AI 운용] 「마이드라이브의 비극」을 통해 생각하는 Gem·NotebookLM의 인수인계 설계
Google Workspace의 Gem과 NotebookLM 활용 시 발생할 수 있는 인수인계 문제를 다룹니다. 개인의 AI 활용이 팀의 업무 프로세스로 편입될 때, 작성자의 퇴직이나 이동에 대비한 관리 체계와 공유 드라이브 방식의 설계가 필요함을 강조합니다.
Claude Opus 4.8 / Gemini 3.5 Pro 시대의 「장문 컨텍스트 활용」 구현 패턴
Claude Opus 4.8 및 Gemini 3.5 Pro와 같은 초장문 컨텍스트 모델 시대에 대응하는 효율적인 구현 패턴을 다룹니다. 비용, 레이턴시, 정보 손실 문제를 해결하기 위해 RAG와 장문 컨텍스트를 혼합하여 사용하는 하이브리드 전략을 제안합니다.
Docker로 구동하는 Claude Code: 자택 서버로 테스트한 견고한 로컬 개발 환경 구축 방법
보안과 기밀 유지가 중요한 환경을 위해 Docker와 Claude Code를 활용하여 자택 서버에 견고한 로컬 AI 개발 환경을 구축하는 방법을 소개합니다. Docker Compose를 통해 의존성 문제를 해결하고, 네트워크 분리를 통해 보안 리스크를 최소화하는 실무적인 구성 방안을 다룹니다.
1년 차 엔지니어의 '학습 누락'을 AI 에이전트에게 관리하게 해 보았다
신입 엔지니어가 AI에 대한 과도한 의존을 방지하고 학습 효과를 극대화하기 위해 Claude Code를 활용해 구축한 자기 주도적 학습 체계를 소개합니다. Claude Code의 대화 규칙 설정과 Skill 기능을 통해 학습 내용을 기록하고 리뷰하는 프로세스를 구현했습니다.
Claude Code 분류기를 운영하며 정밀도를 높이는 방법 — 오분류 로그를 다음 프롬프트에 환원하는 설계
Claude Code를 활용한 Terraform plan 분류기의 정밀도를 높이기 위해 오분류 로그를 피드백 루프로 환원하는 설계 방식을 제안합니다. 완벽한 프롬프트 대신 인간의 정정 데이터를 구조화된 로그로 축적하여 지속적으로 개선하는 메커니즘에 집중합니다.
superpowers와 mattpocock/skills를 모두 사용해보고 알게 된 철학의 차이와 선택 방법
Claude Code의 두 가지 스킬 세트인 superpowers와 mattpocock/skills의 설계 철학 및 사용 방식을 비교 분석합니다. 자동화된 규율 강제와 엔지니어링 지식 축적이라는 서로 다른 접근 방식을 다룹니다.

토큰을 압축하여 LLM 비용 절감 - Headroom 핸즈온
Headroom은 LLM에 전달되는 컨텍스트를 사전에 압축하여 입력 토큰 양과 API 비용을 절감하는 도구입니다. Docker Compose를 활용해 로컬 프록시로 구축하고, Codex와 같은 코딩 에이전트와 연동하여 토큰 절감 효과를 확인하는 방법을 소개합니다.
RAG의 정밀도 향상: 모든 법률을 넣었더니 기본 문제를 틀린 사례와 チャンキング(Chunking)을 통한 재정비
일본의 모든 법률 데이터를 RAG 시스템에 투입했을 때 발생하는 정밀도 저하 문제를 분석하고, 이를 해결하기 위한 실험 과정을 다룹니다. 데이터 양이 늘어남에 따라 발생하는 검색 방해 요인을 파악하고, 구조 기반 チャンキング(Chunking)을 통한 개선 방안을 제시합니다.
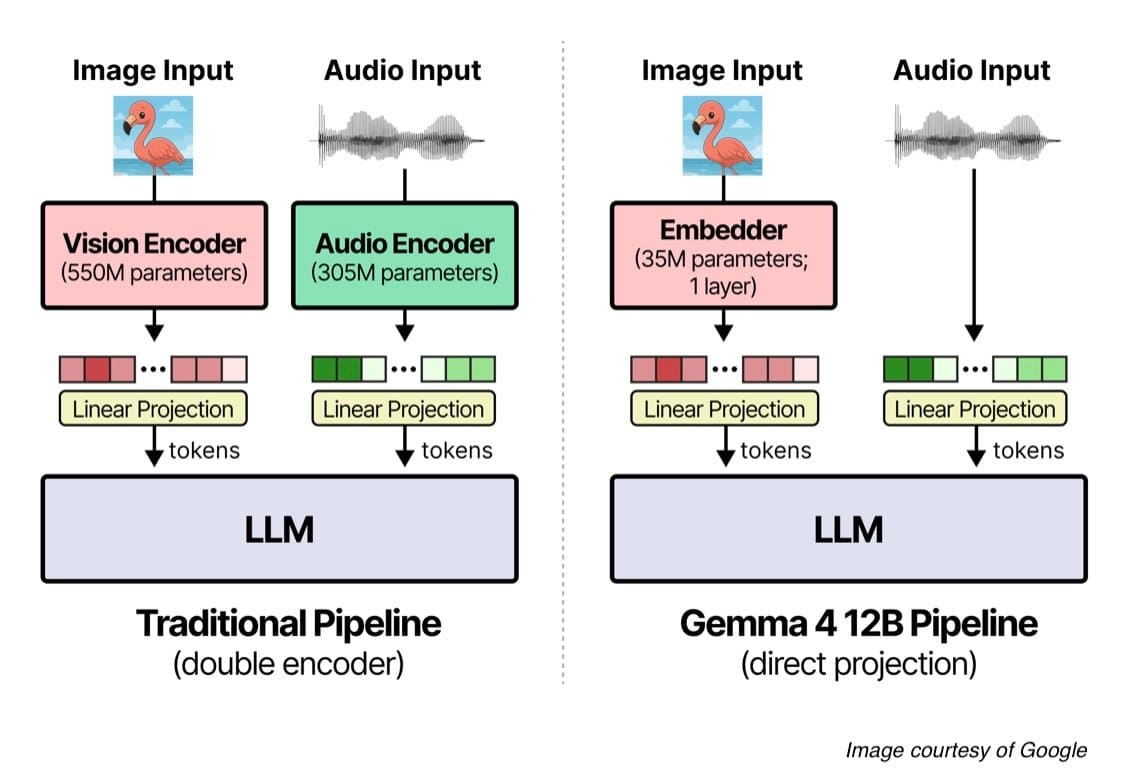
Gemma 4 12B — 인코더 프리(Encoder-free) 아키텍처로 구현하는 온디바이스 멀티모달 AI
Google이 온디바이스 멀티모달 에이전트 워크플로를 위해 설계한 Gemma 4 12B를 공개했습니다. 별도의 인코더 없이 단일 디코더 구조를 사용하는 Encoder-free 아키텍처를 통해 레이턴시를 줄이고 효율성을 극대화했습니다.
이 피드 구독하기
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.