
온디바이스 VLM (이미지 입력 LLM) 레시피
요약
iPhone 상에서 구동되는 온디바이스 VLM(Vision Language Model) 활용법을 소개합니다. VLM의 한계인 수량 파악과 위치 인식 문제를 Apple의 Vision, ARKit, LiDAR 등 기존 이미지 처리 기능과 조합하여 해결하는 개발 레시피를 다룹니다.
핵심 포인트
- VLM의 약점인 수량 세기와 위치 파악을 Apple 프레임워크로 보완
- Vision, ARKit, LiDAR, CoreML을 활용한 하이브리드 구현
- 문서 내 라벨-값 추출 및 자연어 질의응답 구현 가능
- 온디바이스 구동을 통한 데이터 보안 및 실시간성 확보
이미지를 보여주며 "이게 뭐야?"라고 물을 수 있는 AI가 있습니다.
"나무로 된 다이닝 테이블이네요. 머그컵이 2개 있고, 하나는 홍차인 것 같습니다"라고 설명해 줍니다.
Vision Language Model (VLM)이라고 불립니다.
이미지와 언어를 다룰 수 있는 VLM은 iPhone 상에서 구동할 수 있습니다.
iOS의 기능과 조합함으로써, 다음과 같이 강력한 기능을 구현할 수 있습니다.



이러한 AI는 보통 클라우드 서버에서 작동합니다. 어딘가의 데이터 센터로 이미지가 전송되어 처리된 후 답이 돌아옵니다.
하지만 전부 iPhone 상에서만 실행할 수도 있습니다.
"이미지를 보여주면 무엇이든 대답해 줄 것 같지만", 사실 의외로 서툰 부분이 많습니다.
세는 것에 서툼. 3개 정도까지는 맞히지만, 20개가 나열되어 있으면 정확한 수를 내는 것을 어려워함.
정확한 위치를 대답하지 못함. 이미지의 어디에 물건이 있는지 정확하게 출력하는 것도 어려워함.
이것들은 VLM이 나쁘다기보다, 잘하는 것과 못하는 것의 차이입니다.
반면, iPhone에는 Apple이 아주 오래전부터 만들어온 이미지 처리 기능이 다양하게 들어있습니다.
- Vision — 사람의 얼굴을 찾고, 글자를 읽고, 물체를 탐지하는 기능. 수년간 단련되어 온 전통 있는 기능.
- ARKit — 스마트폰을 비추면 공간을 실시간으로 인식하는 메커니즘.
- LiDAR — iPhone Pro에 탑재된 레이저 센서. 거리를 정확하게 측정할 수 있음.
- CoreML — 자체 AI 모델을 iPhone 상에서 구동하는 메커니즘.
이 기능들은 "세기", "위치 반환", "거리 측정"에 특화되어 있습니다. VLM이 서툰 부분을 정확히 보완해 줍니다.
즉, VLM과 Apple의 기능을 조합하면, 어느 한쪽 단독으로는 할 수 없었던 일을 할 수 있게 됩니다.
개발자를 위해, "레시피"라는 형태로 자주 쓰이는 사용법을 패키지로 묶어 두었습니다.
코드는 단 몇 줄이면 충분합니다.
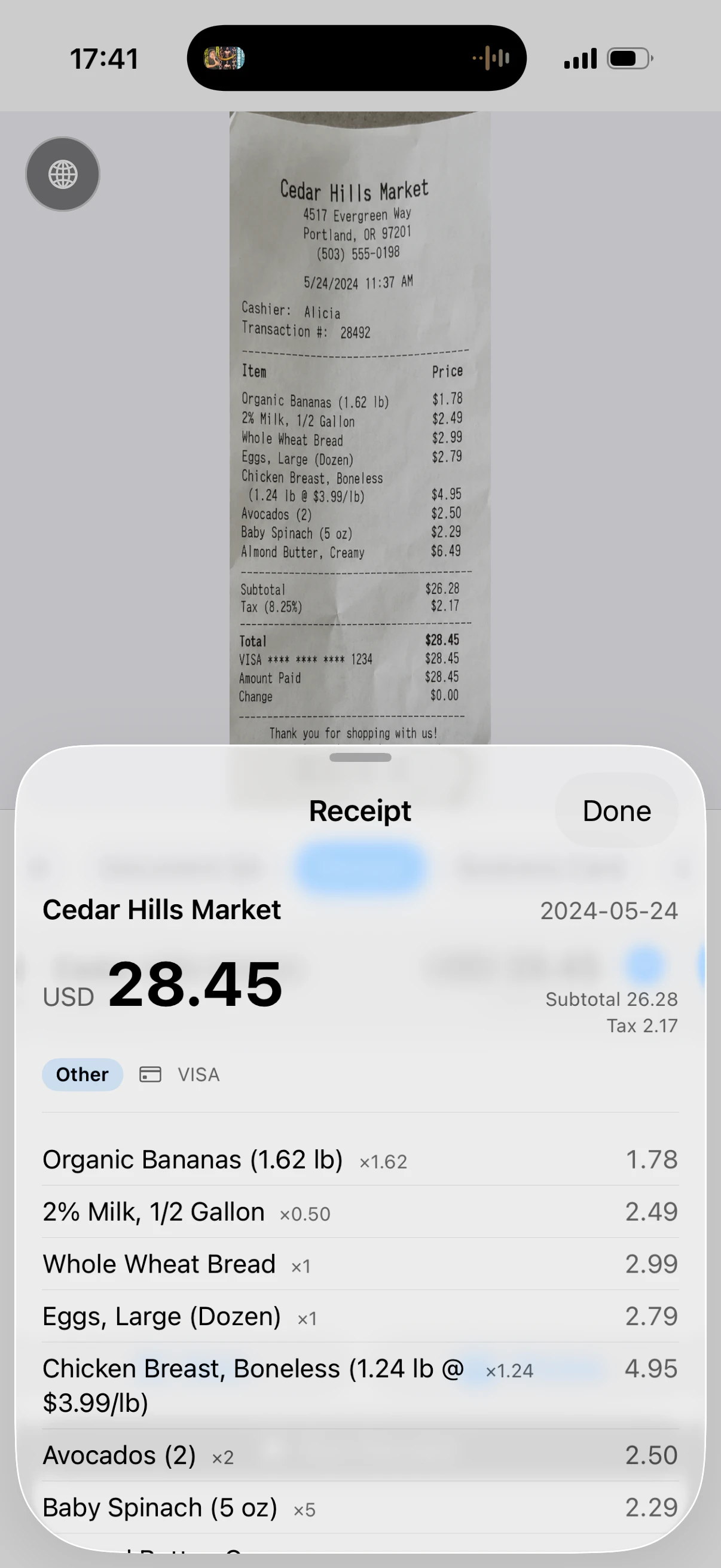
기계의 명판, 영수증, 계약서, 약 설명서, 업무 매뉴얼.
페이지 안의 "라벨: 값"을 전부 찾아냅니다. "모델명: XJ-100A", "제조일: 2026-06-01".
그 후에 자유 문장으로 질문할 수 있습니다.
질문: "보증 기간은 몇 년인가요?"
답변: "5년"
근거: "본 제품의 보증 기간은 5년으로 합니다"
AI는 은근슬쩍 거짓말을 하는 경향이 있습니다 (이를 "할루시네이션 (Hallucination)"이라고 부릅니다). VLMKit에서는 이를 피하기 위해, 답변의 근거가 된 문장을 서류 안에서 그대로(逐語的に) 가져오는 것을 필수 사항으로 하고 있습니다.
"검은 개가 빨간 공을 가지고 놀고 있다. 장소는 초록색 잔디밭"

이와 같이 설명되는 이미지에서 "검은 개", "빨간 공", "초록색 잔디밭"이 각각 사진의 어디에 있는지를 하이라이트할 수 있습니다.
먼저 Apple의 Vision으로 찍혀 있는 사람을 모두 찾습니다.
한 명씩 잘라낸 사진을 VLM에 전달하여 개별적으로 질문합니다.
그대로 CSV로 만들어 Excel이나 Numbers에 바로 붙여넣을 수 있는 형태로 반환됩니다.
VLM은 항목별로 추출할 수 있으므로, iPhone의 연락처 앱에 그대로 저장할 수 있습니다.
iPhone Pro를 비추면 ARKit과 LiDAR가 앞의 물체를 3D로 인식하여, 가로·세로·깊이·부피를 실측치로 산출합니다.
동시에 VLM이 해당 오브젝트에 설명을 붙여 3차원으로 표시합니다.
Swift Package Manager에 이것을 추가하기만 하면 됩니다.
.package(url: "https://github.com/john-rocky/VLMKit", from: "0.1.0")
모델은 최초 실행 시 Hugging Face에서 다운로드됩니다.
| 선택 가능한 모델 | 크기 | 적합한 용도 |
|---|---|---|
| Qwen3-VL-4B (기본값) | 약 3 GB | 정확도와 크기의 밸런스. 이것으로 시작하는 것이 무난함 |
| Qwen3-VL-8B | 약 6 GB | 더 높은 정확도. 16 GB의 iPad / M 시리즈 Mac |
| SmolVLM2-500M | 약 1 GB | 경량형. 8 GB iPhone에서도 구동 가능 |
Mac의 CLI에서도 실기기를 구성하지 않고 테스트할 수 있습니다.
swift run vlmkit-cli docqa plate.jpg --ask "모델명은?"
VLM을 클라우드 API로 사용하면 편리하고, 빠르고, 똑똑합니다.
하지만, 다룰 수 있는 데이터가 제한적입니다.
고객의 계약서를 OpenAI에 보낸다고 말할 수는 없습니다.
환자의 약 사진을 Google에 보낼 수도 없습니다.
경비 정산을 위한 영수증을 외부 서버에 올리는 것도 어렵습니다.
"편리한 AI를 사용하고 싶다", "하지만 데이터는 외부로 내보낼 수 없다".
이러한 딜레마가 지금까지 업무용 애플리케이션에서 AI가 확산되지 못했던 큰 이유 중 하나였습니다.
온디바이스 VLM (On-device VLM)이 해결할 수 있는 부분이 바로 여기입니다.
데이터는 스마트폰 안에. AI도 스마트폰 안에. 모든 것이 완결됩니다.
오픈 소스이며, MIT 라이선스입니다.
github.com/john-rocky/VLMKit
iPhone을 가지고 있고, VLM을 테스트해 보고 싶은 분들은 꼭 확인해 보세요.
🐣
프리랜서 엔지니어입니다.
VLM을 사용한 시스템을 개발하고 싶으신 분들은 꼭 연락해 주세요.
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기