단일 GPU로 수십억 개의 파라미터를 가진 LLM을 처음부터 학습시키기
요약
소비자용 단일 GPU를 활용하여 수십억 개의 파라미터를 가진 LLM을 처음부터 학습시키는 방법을 다룹니다. 토큰화부터 분산 학습 트릭, 그리고 AI 에이전트의 내부 작동 원리까지 오픈 소스로 제공합니다.
핵심 포인트
- 단일 GPU로 대규모 LLM 학습 가능성 증명
- 토큰화 및 분산 학습 기술 오픈 소스 제공
- AI 에이전트의 핵심 원리(메모리, 계획, 추론) 단계별 학습
- 프레임워크 없이 제로 베이스에서 작동 원리 구현
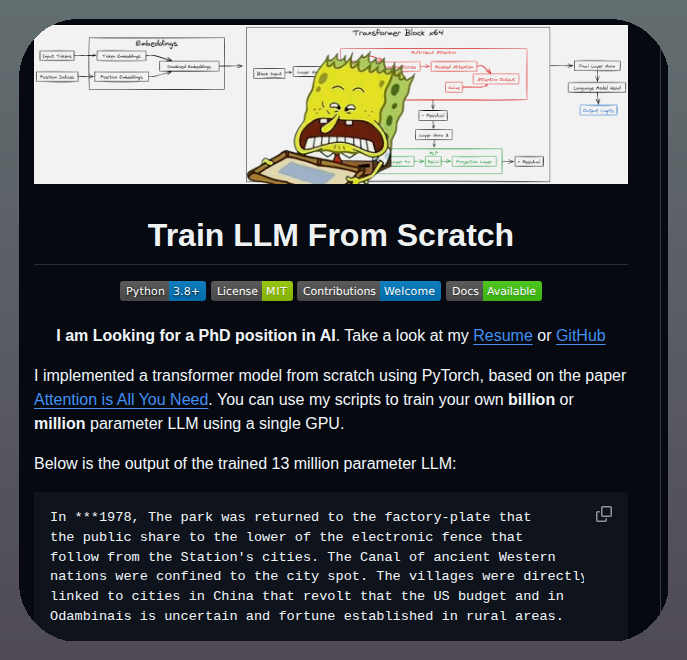
단일 GPU로 수십억 개의 파라미터(billion-parameter)를 가진 LLM을 처음부터 학습시킵니다.
대부분의 사람들은 LLM을 학습시키려면 데이터 센터(datacenter)와 수백만 달러가 필요하다고 생각합니다.
이 저장소(repo)는 그렇지 않다는 것을 증명합니다.
이 저장소는 소비자용 하드웨어에서도 대규모 학습(large-scale training)을 가능하게 하는 기술들을 사용하여, GPT 스타일의 모델을 처음부터 구축하고 학습시키는 방법을 보여줍니다.
토큰화(tokenization)부터 분산 트릭(distributed tricks)까지 — 모든 것이 오픈 소스(open-source)입니다.
https://github.com/FareedKhan-dev/train-llm-from-scratch
...
제1원리(first principles)로부터 AI 에이전트(AI agents)를 구축하는 방법을 가르칩니다.
대부분의 AI 튜토리얼은 프레임워크(frameworks)로 바로 건너뜁니다.
이 튜토리얼은 제로(zero)에서 시작하여 에이전트가 실제로 내부적으로 어떻게 작동하는지 보여줍니다.
도구 사용(Tool use), 메모리(memory), 계획(planning), 추론 루프(reasoning loops) — 모든 것이 단계별로 설명됩니다.
만약 당신이 ~하고 싶다면 완벽합니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @DAIEvolutionHub (AI 자동화)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기