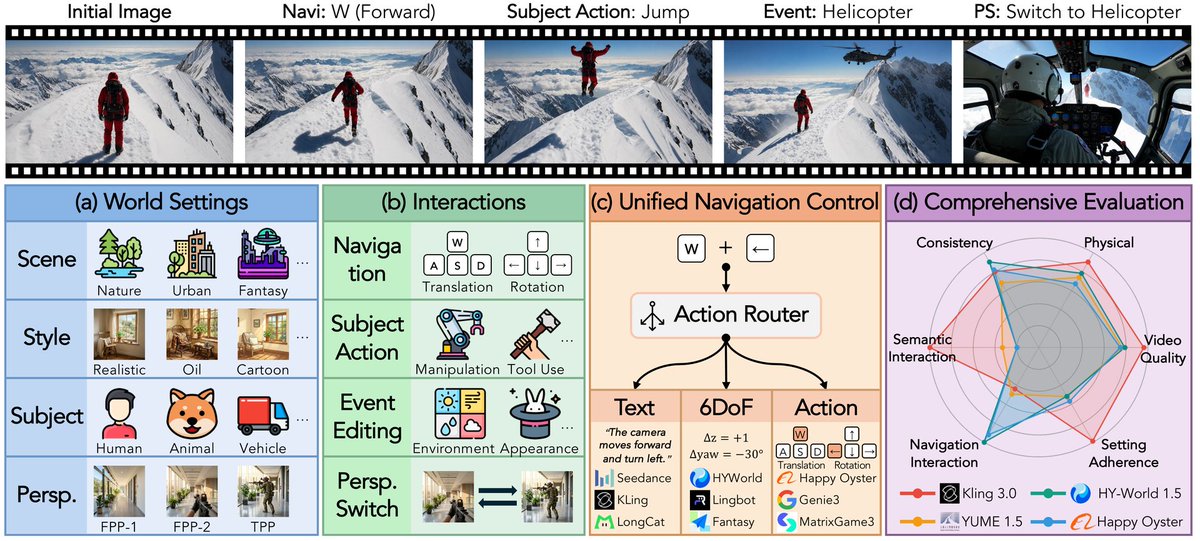
WBench, 20개의 비디오 월드 모델 (video world models) 벤치마크
요약
비디오 월드 모델의 성능을 평가하기 위한 새로운 벤치마크인 WBench를 소개합니다. 20개의 모델을 대상으로 품질, 제어력, 물리 법칙 등 5개 차원에서 다각도로 분석한 결과를 담고 있습니다.
핵심 포인트
- 289개 케이스와 1,058회 턴을 포함한 포괄적 평가
- Kling 3.0, Wan 2.7 등 20개 모델 테스트 수행
- 모든 모델이 각기 다른 사각지대를 가짐을 확인
- 품질, 제어, 물리 법칙을 모두 압도하는 단일 모델은 없음
WBench, 20개의 비디오 월드 모델 (video world models) 벤치마크
289개의 케이스와 1,058회의 턴 (turns)을 포함한 포괄적인 멀티턴 (multi-turn) 평가.
5개 차원에 걸친 22개의 지표 (metrics)를 통해 핵심적인 발견을 제시합니다.
품질 (quality), 제어 (control), 그리고 물리 법칙 (physics) 모두를 압도하는 단일 모델은 존재하지 않습니다.
Kling 3.0, Wan 2.7, Seedance 1.5, Genie 3 및 기타 16개 모델을 테스트했습니다.
모든 모델에는 사각지대 (blind spots)가 존재합니다.
논문 (Paper):
https://huggingface.co/papers/2605.25874
데이터 (Data):
https://huggingface.co/datasets/meitan-longcat/WBench
StepAudio 2.5: 음성 인식 (speech recognition), 합성 (synthesis), 그리고 실시간 대화 (live dialogue)를 위한 단일 모델
ASR (자동 음성 인식), 텍스트 음성 변환 (text-to-speech), 그리고 실시간 구어 상호작용 (real-time spoken interaction) 전반에 걸쳐 전문화된 시스템과 대등하거나 이를 능가할 수 있도록, 작업 맞춤형 RLHF (Reinforcement Learning from Human Feedback)를 사용하는 통합 오디오-언어 파운데이션 모델 (audio-language foundation model)입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기