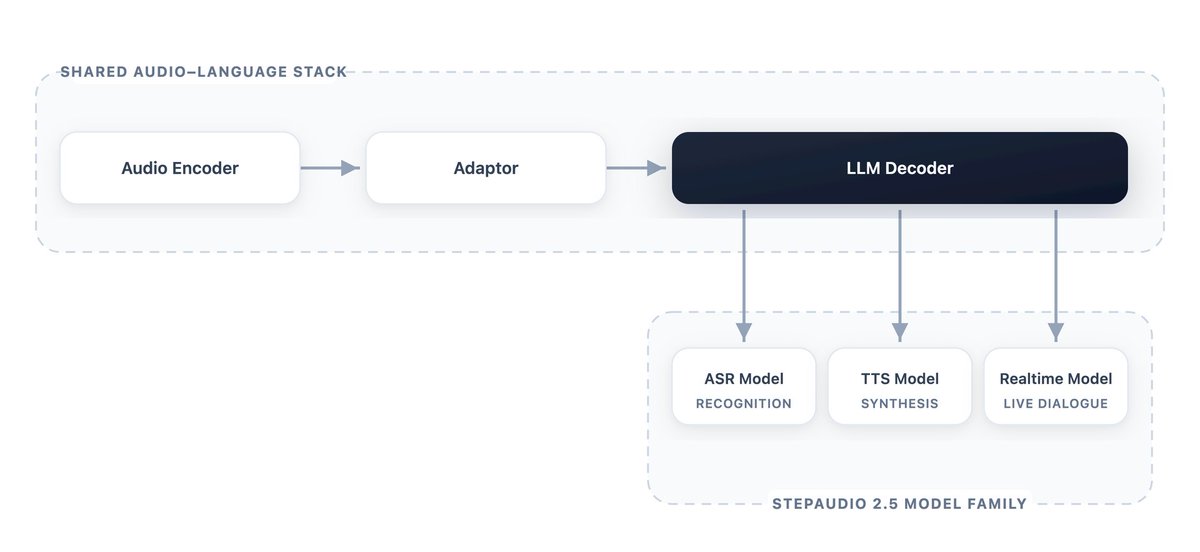
StepAudio 2.5: 음성 인식, 합성 및 실시간 대화를 위한 단일 모델
요약
StepAudio 2.5는 음성 인식(ASR), 합성(TTS), 실시간 대화를 하나의 모델로 통합한 오디오-언어 파운데이션 모델입니다. 작업 맞춤형 RLHF를 적용하여 기존 전문화된 시스템과 대등하거나 이를 능가하는 성능을 보여줍니다.
핵심 포인트
- ASR, TTS, 실시간 대화 기능을 통합한 단일 모델
- 작업 맞춤형 RLHF를 통한 성능 최적화
- 기존 전문화된 개별 시스템 수준의 성능 구현
StepAudio 2.5: 음성 인식 (ASR), 합성 (Synthesis), 그리고 실시간 대화 (Live dialogue)를 위한 단일 모델
ASR, 텍스트 음성 변환 (TTS), 그리고 실시간 구어 상호작용 (Real-time spoken interaction) 전반에 걸쳐 전문화된 시스템과 대등하거나 이를 능가할 수 있도록, 작업 맞춤형 RLHF (Reinforcement Learning from Human Feedback)를 사용하는 통합 오디오-언어 파운데이션 모델 (Audio-language foundation model)입니다. https://t.co/YywHtuOAjc
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기0