SkillOpt를 통해 배우는, '스킬을 증거로 키우는' 작은 실험
요약
Microsoft의 SkillOpt 논문을 바탕으로, AI 에이전트의 스킬 문서를 체계적으로 개선하기 위한 실험적 방법론을 소개합니다. 스킬 개선을 단순 프롬프트 수정이 아닌, 평가 가능한 개선 루프(improvement loop)로 구축하는 원리와 주의사항을 다룹니다.
핵심 포인트
- SkillOpt는 모델 재학습 대신 스킬 문서를 최적화 대상으로 삼음
- 스킬 개선을 평가 가능한 루프로 바라보는 관점 제시
- 학습/선정/최종 확인용 데이터 분할의 중요성 강조
- 스킬 개선 시 발생할 수 있는 데이터 오염 및 편향 방지 규칙
서론
AI 에이전트에게 작업을 요청할 때, 흔히 "이럴 때는 이렇게 해달라"는 지시문이나 작업 절차를 작성합니다.
예를 들어, 코드 수정이라면,
- 먼저 실패하고 있는 테스트를 재현한다
- 에러 문구와 입력 예시를 먼저 읽는다
- 수정 후에 동일한 테스트를 다시 실행한다
와 같은 내용입니다.
SkillOpt에서는 이러한 작업 절차나 판단 기준을 작성한 문서를 스킬 문서 (skill document)로 취급합니다.
스킬 문서는 처음부터 완벽하게 작성할 수 없습니다. 실제로 실패한 사례를 보면서 조금씩 개선하고 싶어집니다.
다만, 여기서 어려운 점은 "정말로 좋아졌는가"를 판단하는 것입니다.
본 적이 있는 문제에 대해서만 강해진 것일지도 모릅니다. 정답에 가까운 정보를 무심코 보고 있을 가능성도 있습니다. 부모 스킬(parent skill)과 후보 스킬(candidate skill)을 서로 다른 조건에서 비교하고 있을 수도 있습니다.
이 기사에서는 SkillOpt라는 논문을 읽고 궁금해졌던,
스킬 문서를 어떻게 하면 자신을 속이지 않고 키울 수 있을까
라는 질문으로부터, 작은 수동 하네스(manual harness)를 만든 이야기를 쓰고자 합니다.
이 기사를 통해 얻을 수 있는 내용은 대략 다음과 같습니다.
- SkillOpt의 핵심 아이디어를 대략적으로 이해할 수 있음
- 스킬 개선을 프롬프트 조정이 아닌, 평가 가능한 개선 루프(improvement loop)로 바라볼 수 있음
- 학습용 / 선정용 / 최종 확인용 split을 나누는 이유를 알 수 있음
- 후보 스킬을 채택할 때 어떤 실패를 피하고 싶은지 알 수 있음
- 작은 하네스로 SkillOpt적인 실험 규율을 어떻게 재현할 수 있는지 알 수 있음
구현에 관한 자세한 이야기는 마지막에 리포지토리 내의 주요 파일을 정리하여載せ겠습니다.
SkillOpt의 어떤 점이 흥미로웠는가
모태가 된 것은 Microsoft의 SkillOpt입니다.
SkillOpt의 흥미로운 점은 모델 본체를 다시 학습시키는 것이 아니라, 에이전트에게 전달할 스킬 문서를 육성 대상으로 보고 있다는 점입니다.
여기서 말하는 스킬 문서는 태스크를 해결하는 방법, 주의 사항, 판단 기준 등을 작성한 외부 텍스트입니다.
이러한 지시문은 사람이 직접 수정하거나, LLM에게 한 번 만들게 하고 끝내버리는 경우가 많습니다.
SkillOpt는 그 부분을 조금 더 기계적으로 다룹니다.
- 에이전트에게 태스크를 수행하게 함
- 실패나 성공의 기록을 확인함
- 별도의 최적화 모델 (optimizer model)이 후보 스킬을 작성함
- 후보 스킬을 시도함
- 선정용 split에서 부모 스킬보다 좋아졌을 때만 채택함
즉, 스킬 문서를 막연하게 수정하는 것이 아니라, 실패 사례, 후보 스킬, 선정용 결과를 사용하여 조금씩 키워나가려 합니다.
논문의 주인공은 물론 훨씬 더 큰 메커니즘입니다. 여러 benchmark, 여러 model, 여러 실행 환경에서 스킬을 안정적으로 개선하기 위한 방법이 설명되어 있습니다.
다만, 제가 처음에 관심을 가졌던 것은 훨씬 더 작은 부분이었습니다.
우선 작게 시도해보고 싶었던 것
논문을 읽으며 가장 먼저 든 생각은 이것이었습니다.
갑자기 최적화기(optimizer) 전체를 만들기 전에, "개선되었다고 말할 수 있는 조건"만 작게 시도해 볼 수는 없을까?
스킬 문서를 개선할 때 실패하기 쉬운 지점은 몇 가지 있습니다.
예를 들어, 학습용 문제에서만 잘 작동하도록 수정해 버리는 경우입니다. 이럴 경우 선정 시에 정말로 폭넓게 효과가 있는지 알 수 없습니다.
혹은 후보 스킬을 만들 때 선정용 split의 정보를 미리 보고 버리는 경우입니다. 이럴 경우 선정 결과를 독립적인 평가로서 다루기 어려워집니다.
또한, 부모 스킬과 후보 스킬을 서로 다른 문제로 비교하는 경우도 있습니다. 이 경우 후보 스킬이 좋았던 것인지, 단순히 문제가 쉬웠던 것인지 알 수 없습니다.
이러한 실패를 피하려면 적어도 다음과 같은 규칙이 필요해 보입니다.
- 학습용 split과 선정용 split을 분리한다
- 최종 확인용 split은 중간 과정에서 사용하지 않는다
- 부모 스킬과 후보 스킬은 동일한 선정용 task로 비교한다
- 후보 스킬은 부모 스킬보다 명확하게 좋을 때만 채택한다
- 무엇을 보고, 무엇을 바꾸었으며, 왜 채택했는지를 기록으로 남긴다
이 정도만을 아주 작게 시도해 보기로 했습니다.
작은 하네스를 만들었다
하네스가 하는 일
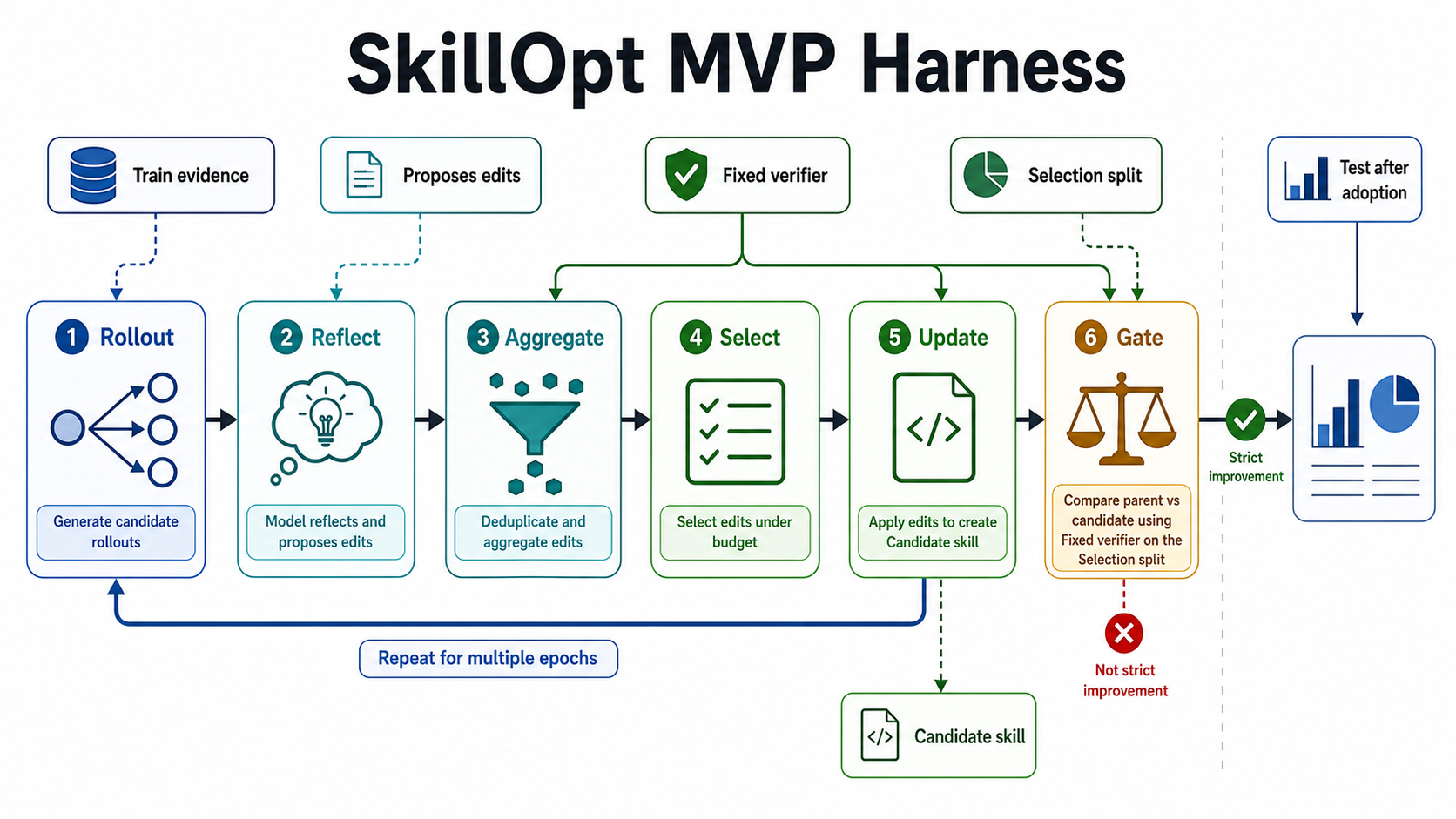
만든 것은 SkillOpt 형식의 개선 루프를 수동으로 테스트하기 위한 작은 하네스입니다.
후보 스킬을 만드는 부분과 채택을 결정하는 부분을 분리해 둔다.
이 하네스는 최적화기 (optimizer)가 아닙니다. Codex도 호출하지 않습니다. 후보를 만드는 주체와 후보를 평가하는 메커니즘을 분리해 두고 싶었기 때문입니다.
역할 분담은 대략 다음과 같이 생각하고 있습니다.
| 역할 | 무엇을 하는가 | 무엇을 하지 않는가 |
|---|---|---|
| Codex | 태스크를 해결한다. 실패 사례를 보고 후보 스킬을 생각한다 | 선정용 / 최종 확인용으로 숨겨진 정보를 본다 |
| 하네스 (Harness) | workspace를 준비한다. 채점한다. 결과와 판단을 파일로 남긴다 | 후보 스킬을 자동으로 생각한다. Codex를 호출한다 |
루프 안에서는 대략 다음과 같은 순서로 파일이 늘어납니다.
| 단계 | 무엇을 하는가 | 주요 기록 / 입력 |
|---|---|---|
| 롤아웃 (rollout) | Codex가 부모 스킬로 학습용 task를 해결한다 | train-rollouts.jsonl |
| ... | candidate-skill.md , update-report.json | |
| 게이트 (gate) | 부모 스킬과 후보 스킬을 선정용 split으로 비교하여 채택 여부를 결정한다 | parent-selection.jsonl , candidate-selection.jsonl , gate-decision.json , decision.md |
이 일련의 흐름은 샘플 run의 manifest에도 남겨두고 있습니다.
하네스 측에서 하는 일은 상당히 제한적입니다.
- 태스크용 workspace를 준비한다
- 숨겨두고 싶은 테스트를 workspace에 넣지 않는다
- 고정된 채점 계수로 결과를 기록한다
- 결과와 채택 판단에 사용한 파일을 모두 남긴다
대상으로 한 태스크도 작습니다.
code_repair: pytest 기반의 작은 코드 수정 태스크data_normalization: 데이터 정리나 변환을 수행하는 작은 태스크
설정 파일에서는 track, split, 채점 명령어만 갖도록 하고 있습니다.
이 하네스의 목적은 강력한 최적화기 (Optimizer)를 만드는 것이 아닙니다.
오히려 "최적화기를 만들기 전에, 개선되었다고 말할 수 있는 경계선을 제대로 그을 수 있는가"를 확인하기 위한 것입니다.
즉, 이 하네스는 "후보를 생각하는 도구"가 아니라, "후보를 채택해도 되는지를 나중에 확인할 수 있도록 하는 도구"입니다.
split과 채택 판정을 분리하기
가장 중요하게 여긴 것은 split을 세 가지로 나누는 것입니다.
- 학습용 split
- 선정용 split
- 최종 확인용 split
| split | 무엇에 사용하는가 | 도중에 봐도 되는가 |
|---|---|---|
| 학습용 | 후보 스킬을 생각한다 | 봐도 된다 |
| ... |
생각하는 방식 자체는 상당히 소박합니다.
학습용 split은 후보 스킬을 생각하기 위해 사용합니다. 어디서 실패했는지, 스킬 문서에 무엇이 부족했는지를 보기 위해서입니다.
선정용 split은 후보 스킬을 채택할지 말지를 결정하기 위해 사용합니다. 여기서 부모 스킬보다 나아지지 않았다면 채택하지 않습니다.
최종 확인용 split은 도중에 사용하지 않습니다. 이곳을 자꾸 들여다보면, 어느샌가 그곳에 맞춘 조정이 되어버리기 때문입니다.
fixture를 배치하는 방식도 이 세 가지를 전제로 하고 있습니다.
또 하나 중요한 것은 숨기고 싶은 테스트를 작업용 workspace에 넣지 않는 것입니다.
Codex가 작업하는 곳에는 보이는 테스트만 둡니다. 채점할 때만 일시적인 채점용 workspace에 숨겨진 테스트를 되돌려 놓습니다.
이 메커니즘은 화려하지 않지만, 상당히 중요합니다.
"답을 보지 않았다"라고 말하기 위해서는, 정말로 보이지 않는 형태로 만들어 두어야 합니다.
채택 판단도 미리 고정해 둡니다.
- 부모 스킬과 후보 스킬을 동일한 선정용 task로 비교한다
- 후보 스킬의 점수가 부모 스킬보다 높을 때만 채택한다
- 점수가 같다면 채택하지 않는다
- 작업의 독립성이나 정보 누출(Information Leakage)을 확인할 수 없을 때는 채택하지 않는다
이 "같아서는 안 된다"라는 규칙이 여기서는 중요합니다. 막연히 좋아 보인다거나, 읽기 편해진 것 같다라는 이유로는 채택하지 않습니다.
Code Repair Skill로 한 바퀴만 시도하기
가설과 학습용 split을 통해 알게 된 것
여기서부터는 위의 하네스와 실험 규율 위에서 실제로 실행한 하나의 실험입니다.
이번 글에서 다루는 샘플 run은 code_repair track의 Code Repair Skill입니다. 실험으로는 다음과 같이 설정했습니다.
학습용 split에서는 다음과 같은 실패 사례로부터 후보 스킬을 구상했습니다.
<table><thead><tr><th>학습용 task</th><th>visible test만으로는 놓치기 쉬운 것</th><th>거기서 얻은 시사점</th></tr></thead><tbody><tr><td>`addition_bug`</td><td>visible test는 덧셈의 한 예시일 뿐이다</td><td>task description만으로 본래 동작을 특정할 수 있는 경우가 있다</td></tr><tr><td>`clamp_bug`</td><td>visible test는 상한 쪽만 보여준다</td><td>하한과 상한 둘 다를 task description에서 읽어야 한다</td></tr><tr><td>`normalize_people`</td><td>필드, 기본값, 순서</td><td>데이터 정제에서는 출력 shape와 default를 명시적으로 봐야 한다</td></tr><tr><td>parse_duration</td><td>유효한 입력의 한 예시일 뿐이다</td><td>parser는 단위, 공백, invalid input까지 읽어야 한다</td></tr><tr><td>stable_frequency`</td><td>tie case가 visible test에 나오지 않는다</td><td>ranking에서는 tie의 안정성도 사양으로 다루어야 한다</td></tr></tbody></table>이 시점에서의 가설은 상당히 단순합니다.
부모 스킬는 'visible test를 읽는다', '최소 변경을 한다'고 말하고 있습니다. 이것이 나쁜 규칙은 아닙니다. 다만, 이를 'visible test의 assertion을 만족시키는 최소 변경'으로만 읽어버리면, task description에 쓰여진 사양을 놓치기 쉽습니다.
그래서 후보 스킬에서는 최소 변경이라는 방침은 유지하되, 수정 전에 task description의 계약을 짧은 체크리스트로 만든다는 문구를 추가해 보기로 했습니다.
후보 스킬에 추가한 규칙
이 샘플에서는 실제 스킬에 두 가지 규칙만 추가했습니다.
부모 스킬에는 이미 'metadata와 visible test를 읽는다', '테스트를 만족시키는 최소 변경을 한다'는 규칙이 있었습니다. 다만, 이대로라면 'visible test에 나와 있는 assertion만 만족시키면 된다'고 해석해 버릴 수 있습니다.
그래서 후보 스킬에서는 이 두 규칙 사이에 다음과 같은 주의사항을 추가했습니다.
- Read `task.json`, `.skillopt-task.json` when present, and the visible tests before editing.
+
...
다시 말해, 후보 스킬은 '더 많이 고치자'고 말하고 있는 것이 아닙니다.
오히려 반대로, 최소 수정이라는 방침은 유지한 채,
- visible test는 예시에 불과하며, 계약 전체가 아니다
- parser, normalizer, clamp, ranking 같은 함수에서는 설명에 있는 경계나 순서도 본다
- 작업 전에 기대되는 동작을 짧은 체크리스트로 만든다
라는 주의사항을 추가한 것입니다.
이 변경 사항은 학습용 split의 실패 사례에서 나왔습니다.
예를 들어 clamp의 visible test는 상한 쪽만 보고 있었지만, 태스크 설명에는 하한과 상한 둘 다가 쓰여 있었습니다. parse_duration에서는 visible test는 유효한 입력의 한 예시일 뿐이었지만, 설명에는 h, m, s 단위와 invalid token의 처리 방식이 있었습니다.
즉, 여기서 원했던 것은 '테스트를 많이 돌리자'라는 규칙이 아니었습니다.
visible test를 진입점으로 삼으면서도, 마지막은 task description에 쓰여진 계약으로 돌아간다는 해석입니다. 부모 스킬은 이 점을 암묵적으로 하고 있었고, 후보 스킬은 그 부분을 명시했습니다.
이러한 학습용 (learning) split의 기록도 나중에 읽을 수 있는 형태로 남겨두고 있습니다.
실제 before / after 스킬도 부모 스킬 (parent skill)과 후보 스킬 (candidate skill)로서 남겨두었습니다.
선정용 split으로 비교한 결과
실제 샘플 실행 (run)에서는 부모 스킬이 0.600,
후보 스킬이 1.000이 되어, 후보 스킬을 새로운 best로 채택했습니다.

부모 스킬은 0.600, 후보 스킬은 1.000. 차이가 발생한 지점은 normalize_records와 parse_duration이었다.
선정용 split에서 사용한 task와 결과는 다음과 같았습니다.
| 선정용 task | 부모 스킬 | 후보 스킬 | 확인된 차이 |
|---|---|---|---|
merge_intervals | 1.0 | 1.0 | 둘 다 통과 |
normalize_records | 0.0 | 1.0 | missing name의 default를 놓치지 않게 됨 |
parse_duration | 0.0 | 1.0 | 대문자 단위나 공백을 포함한 입력까지 읽을 수 있게 됨 |
tokenize_query | 1.0 | 1.0 | 둘 다 통과 |
top_k_frequent | 1.0 | 1.0 | 둘 다 통과 |
| 비교 대상 | 선정용 점수 | 판단 |
|---|---|---|
| 부모 스킬 | 0.600 | 계속하지 않음 |
| 후보 스킬 | 1.000 | 채택 |
이 결과는 이번의 작은 가설과 일치했습니다.
부모 스킬이 놓친 normalize_records와 parse_duration은 둘 다 가시적 테스트 (visible test)의 예시만으로는 간과하기 쉬운 사양을 포함하고 있었습니다. normalize_records에서는 missing name의 default가, parse_duration에서는 대문자 단위나 공백을 포함한 입력이 숨겨진 테스트 (hidden test) 측에서 요구되었습니다.
후보 스킬에서는 task description을 계약 (contract)으로서 다시 읽는 규칙을 추가함으로써, 이러한 조건까지 포착할 수 있었을 가능성이 있습니다. 적어도 이번 선정용 split에서는 "가시적 테스트뿐만 아니라 task description의 계약으로 돌아간다"는 변경이 효과가 있었다고 해석할 수 있습니다.
한편, 이것이 "이 규칙을 추가하면 일반적으로 코드 수정 (code repair) 능력이 강해진다"라고 말할 수 있는 결과는 아닙니다. 작은 fixture 상에서의 단 한 번의 루프 (loop)일 뿐이며, 이번에 말할 수 있는 것은 "이 split에서는 가설에 부합하는 후보 스킬이 부모 스킬을 상회했다"는 범위까지입니다.
여기서 보고 싶은 것은 점수의 크기 그 자체보다 "왜 채택했는지를 나중에 추적할 수 있는가"입니다.
채택 판단에 대해서는 감사 (audit) 기록도 남겼습니다.
이렇게 해두면 나중에 확인했을 때,
- 어떤 문제로 비교했는지
- 부모 스킬과 후보 스킬의 점수는 얼마였는지
- 정보 누락은 없었는지
- 어떤 파일이 최종 판단에 사용되었는지
를 확인할 수 있습니다.
무엇을 알게 되었나, 혹은 아직 말할 수 없는가
만들어 보길 잘했다고 생각하는 점은, "스킬을 개선한다"는 이야기를 조금이나마 평범한 실험에 가깝게 만들 수 있었다는 것입니다.
스킬 문서를 수정하다 보면 아무래도 주관이 개입됩니다.
'이 표현이 더 좋아 보인다.', '이번 실패에는 효과가 있겠다.', '왠지 똑똑해진 것 같다.'
그 자체는 나쁘지 않습니다. 오히려 후보 스킬을 구상하는 단계에서는 필요합니다.
다만, 채택하는 단계에서는 이야기가 다릅니다.
채택할 때는,
- 무엇을 보고 후보 스킬을 만들었는지
- 무엇으로 비교했는지
- 부모 스킬보다 정말로 좋았는지
- 나중에 동일한 판단을 따라갈 수 있는지
를 보고 싶습니다.
이번 하네스 (harness)는 이를 위한 최소한의 발판이 되었습니다.
한편으로 한계도 있습니다.
우선, 이것은 SkillOpt의 재구현이 아닙니다. 최적화 모델에 의한 자동 성찰 (reflection)이나, 더 큰 벤치마크 (benchmark) 상에서의 검증은 포함되어 있지 않습니다.
또한 점수도 단순합니다. pytest가 통과하면 1.0, 실패하면 0.0입니다. 세밀한 품질 차이를 측정하는 것이 아닙니다.
게다가 fixture도 작습니다. 이 하네스로 좋은 결과가 나왔다고 해서 곧바로 일반적인 스킬 개선이 가능하다고 말할 수는 없습니다.
그럼에도 불구하고, 첫 실험대로(testbed)로서는 이 정도의 작은 규모가 적당했다고 생각합니다.
큰 최적화기 (Optimizer)를 만들기 전에,
- 어떤 정보를 봐도 되는지
- 어떤 정보를 봐서는 안 되는지
- 언제 채택해도 되는지
- 무엇을 기록으로 남겨야 하는지
를 명확히 할 수 있기 때문입니다.
부록: MVP에서 실제 운영에 가깝게 만들려면
지금까지의 이야기는 어디까지나 작은 MVP (Minimum Viable Product)입니다. 실제로 스킬을 지속적으로 육성하는 운영에 가깝게 만들려면, 다음으로는 "한 번의 실험이 성공했는가"보다 "개선 루프 (Improvement loop)를 안전하게 여러 번 돌릴 수 있는가"가 중요해집니다.
예를 들어, 다음과 같은 확장이 필요할 것으로 보입니다.
- 실제 실패 사례를 우선 train용 fixture로서 격리하여 추가한다
- baseline, 그 시점의 best, 각 loop의 후보와 채택 이유를 추적할 수 있도록 한다
- 선정용 task를 늘리고, 동일한 verifier와 동일한 조건에서 안정적으로 비교한다
- 점수뿐만 아니라, 스킬 문서가 과도하게 fixture에 특화되어 있지 않은지도 확인한다
- 채택 후 성능 악화가 보일 때, 어느 후보까지 되돌릴지를 명확히 한다
특히 주의해야 할 점은, 실제 실패를 발견했을 때 곧바로 선정용 split이나 최종 확인용 split을 수정하지 않는 것입니다.
운영을 하다 보면 "이 케이스도 평가하고 싶다"는 마음이 들게 됩니다. 하지만 그것을 채택 판정에 사용하는 split에 그대로 추가해 버리면, 다음 후보 스킬을 만들 때 어떤 정보를 봐도 되었는지 모호해집니다.
따라서, 우선 실패를 train 측의 fixture로 추가하여 후보 스킬을 만드는 재료로 삼습니다. 그 상태에서 선정용 split은 채택 판정을 위해 별도로 유지합니다. 필요하다면 일정 타이밍에 split 전체를 다시 만들고, 그 세대를 기록합니다.
이 정도까지 수행하면 더 이상 "작은 실험대"가 아니라, 스킬 개선의 운영 기반에 가까워집니다. 이번 하네스 (Harness)는 거기까지는 구현하지 않았지만, 적어도 그 단계로 가기 위해 필요한 경계선은 보였습니다.
요약
SkillOpt 논문에서 제가 흥미롭다고 생각한 점은, 스킬 문서를 단순한 수기 지시문이 아니라 개선 가능한 대상으로 다루고 있다는 점이었습니다.
다만, 스킬을 육성하기 위해서는 단순히 좋아 보이는 문장을 추가하는 것만으로는 부족합니다.
봐도 되는 문제와 봐서는 안 되는 문제를 구분할 것. 상위 스킬과 후보 스킬을 동일한 조건에서 비교할 것. 정말로 좋아졌을 때만 채택할 것. 나중에 판단 과정을 추적할 수 있도록 기록을 남길 것.
이번에 만든 하네스는 이를 위한 작은 실험대입니다.
매우 똑똑한 최적화기 (Optimizer)는 아닙니다. 오히려 상당히 지루한 도구입니다.
하지만 스킬을 조금씩 키워나간다면, 이 지루함이 꽤 중요할지도 모릅니다.
참고
원전
- SkillOpt project page
- SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- microsoft/SkillOpt
구현
Discussion

AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기