NVIDIA가 LocateAnything를 출시했습니다
요약
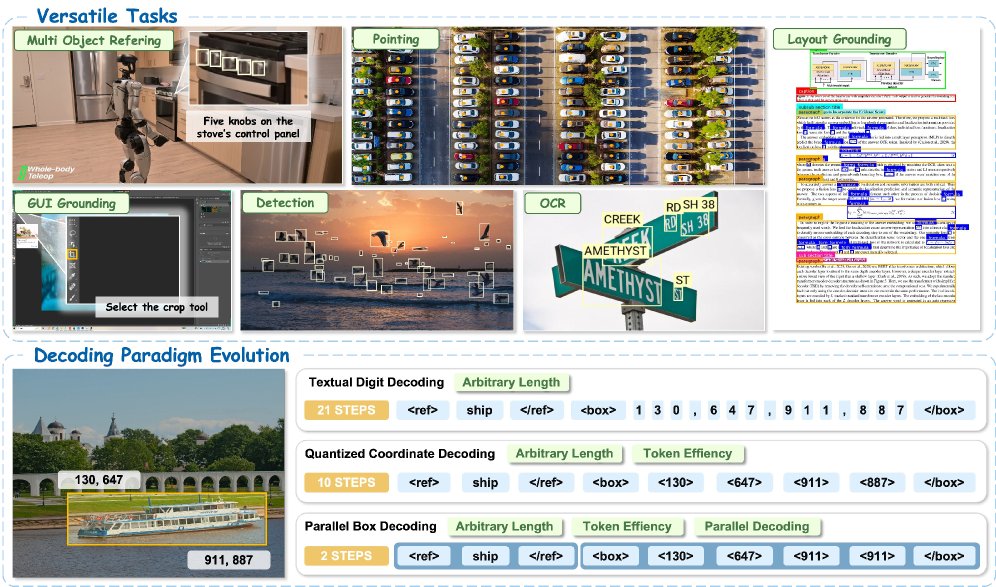
NVIDIA가 단일 단계에서 경계 상자를 디코딩하는 LocateAnything를 출시했습니다. 기존의 토큰 단위 좌표 생성 방식을 대체하여 탐지, OCR, GUI 작업의 정확도를 높이고 추론 속도를 2.5배 향상시켰습니다.
핵심 포인트
- 병렬 박스 디코딩을 통한 추론 속도 2.5배 향상
- 단일 단계 디코딩으로 위치 정확도 개선
- 탐지, OCR, GUI 작업 전반에 적용 가능
- WBench를 통한 비디오 월드 모델 벤치마킹 수행
NVIDIA가 LocateAnything를 출시했습니다.
이 모델은 느린 토큰 단위의 좌표 생성 (token-by-token coordinate generation) 방식을 대체하여, 단일 단계에서 경계 상자 (bounding boxes)를 원자 단위 (atomic units)로 디코딩합니다. 병렬 박스 디코딩 (Parallel Box Decoding)은 탐지 (detection), OCR, 그리고 GUI 작업 전반에서 위치 정확도 (localization accuracy)를 향상시키는 동시에 추론 (inference) 속도를 2.5배 더 빠르게 구현합니다.
논문 (Paper):
https://huggingface.co/papers/2605.27365
모델 (Model):
https://huggingface.co/nvidia/LocateAnything-3B
데모 (Demo):
https://huggingface.co/spaces/nvidia/LocateAnything
WBench는 20개의 비디오 월드 모델 (video world models)을 벤치마킹합니다.
289개의 사례와 1,058회의 턴으로 구성된 포괄적인 멀티 턴 (multi-turn) 평가입니다.
5개 차원에 걸친 22개의 지표 (metrics)를 통해 핵심적인 발견을 제시합니다.
품질 (quality), 제어 (control), 그리고 물리 (physics) 측면 모두에서 압도적인 단일 모델은 존재하지 않습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기