
Nvidia, AI 데이터센터로 영향력 확대
요약
Nvidia가 데이터센터 인프라 전반을 아우르는 플랫폼 구축을 통해 영향력을 확대하고 있습니다. 소프트웨어 중심 기업으로서 DSX 프로젝트를 통해 하드웨어와 소프트웨어 스택을 통합한 완벽한 AI 플랫폼을 지향합니다.
핵심 포인트
- Nvidia는 데이터센터를 통합 플랫폼화하여 영향력 확대 시도
- 전체 직원의 75%가 소프트웨어 분야에 종사하는 소프트웨어 중심 기업
- CUDA-X 기반의 방대한 도메인 특화 라이브러리 생태계 보유
- AI Enterprise 및 Rapids 등 수직적 소프트웨어 스택 제공

Nvidia, AI 데이터센터로 영향력 확대
Nvidia는 현대적인 AI 데이터센터 (datacenter)가 Apple 제품과 더 유사해지기를 원하며, 대만 Computex 컨퍼런스에서 방금 발표한 내용들을 통해 이 회사는 그 야심 찬 목표를 달성하는 데 한 걸음 더 다가서고 있습니다.
데이터센터 (datacenter)를 아우를 뿐만 아니라 시설 자체를 포함하고, 데이터센터에 전력을 공급하는 전력망 (power grids)과 인터페이스할 수 있는 플랫폼을 만드는 것은 결코 사소한 일이 아닙니다. 또한, 로스케일 (rowscale) 및 랙스케일 (rackscale) 시스템과 그 제어 평면 (control planes)에 맞물리고, 이것이 다시 개별 서버 노드 (server nodes)에서 실행되는 소프트웨어 스택 (software stacks) 및 더 미세한 입도 (granularity)로 각자의 라이브러리 (libraries)와 모니터 (monitors)를 가진 CPU 및 가속기 (accelerators)와 맞물리도록 만드는 것은 헤라클레스와 같은 엄청난 과업입니다. 이는 최근 몇 년 동안 하이퍼스케일러 (hyperscaler)나 클라우드 빌더 (cloud builder)가 수행할 수 있었던 일이며, 어쩌면 AI 모델 빌더 (AI model builders)들이 지금 이 순간 막후에서 만들어내고 있는 것일지도 모릅니다. 연간 수천억 달러를 창출하는 거의 완벽에 가까운 AI 플랫폼을 보유한 Nvidia 역시 이를 수행할 수 있으며, 이것이 바로 회사의 DSX 노력이 지향하는 바입니다.
DSX는 Nvidia가 이미 구축해 놓은 매우 깊은 소프트웨어 계층 구조에 또 다른 바깥쪽 마트료시카 인형을 추가하는 것입니다. 다시 한번 상기시켜 드리자면, Nvidia는 소프트웨어 기업입니다. 약 40,000명의 직원 중 75%가 소프트웨어 분야에서 근무하며, 나머지 25%의 직원들이 세계에서 가장 정교한 하드웨어 시스템을 설계하고 있습니다. 우리는 DGX 서버 브랜드가 무엇을 의미했는지 몰랐던 것과 마찬가지로, DSX가 무엇의 약자인지도 알지 못합니다. (우리는 DGX가 X86 호스트를 갖춘 데이터센터 GPU (Datacenter GPU with X86 host)의 약어였을 것이며, DSX는 모니터링 (monitoring), 관리 (management), 시뮬레이션 (simulation)을 의미하는 가변적인 X를 포함한 데이터센터 시뮬레이션 (Datacenter Simulation with X)을 의미할 것이라고 추측합니다.)
Nvidia 소프트웨어 계층 구조의 안쪽 마트료시카 인형(matryoshka doll)은 Nvidia가 CUDA-X라고 부르는, GPU 상의 컴퓨팅을 가속화하기 위한 900개 이상의 도메인 특화 라이브러리(domain-specific libraries) 및 소프트웨어 스택(software stacks)으로 구성되어 있습니다. 이는 cuBLAS, cuDNN, cuSolver, cuDF, cuOpt, cuML, cuGraph 등을 포함한 주요 라이브러리들과 AI, HPC(고성능 컴퓨팅), 데이터 분석, 유전학, 양자 물리학, 칩 설계 등을 위한 최적화가 적용된 수직적 스택(vertical stacks) 모음이 포함된 수평적 스택(horizontal stack)입니다. AI 학습 및 추론을 위한 AI Enterprise와 데이터 분석을 위한 Rapids는 CUDA-X를 기반으로 구축된 수직적 소프트웨어 스택의 두 가지 예시입니다. 이들은 별도로 라이선스가 부여됩니다. 즉, Nvidia GPU를 구매함으로써 CUDA-X를 얻게 되며, 이에 대한 기술 지원을 원한다면 스택 라이선스(대부분 AI Enterprise일 가능성이 높음)를 구매해야 합니다. HPC 분야 종사자들을 위해서는 고전적인 ModSim(모델 시뮬레이션) 작업에 필요한 모든 라이브러리와 Nvidia 컴파일러(2013년 7월 아주 오래전에 The Portland Group를 인수한 결과물)를 하나로 묶은 HPC SDK라는 것이 있습니다.
한 단계 더 높은 곳에는 Dynamo라고 불리는 마트료시카 인형 계층이 있으며, 이는 해당 기반 위에서 구축되어 AI 추론(inference)을 실행하기 위한 모델과 고도로 튜닝된 엔진을 생성합니다. (AI 학습에 대해서는 Nvidia의 대응물이 실제로 존재하지 않지만, 쉽게 만들 수도 있을 것입니다. 대부분의 대형 AI 모델 빌더들은 자신들만의 방식으로 학습 클러스터 소프트웨어를 쌓아 올립니다.) Nvidia는 Dynamo를 AI 추론을 위한 운영체제(operating system)라고 부르지만, 우리는 그것이 용어의 오용이라고 생각합니다. Dynamo는 추론을 수행하는 스택 내의 플랫폼 계층입니다. 그리고 Nvidia가 현재 DSX OS라고 불리는 것에 대해 이야기하고 있다는 사실과 별개로, 우리는 이것이 OS의 정의를 다소 확장시킨다고 생각합니다. 하지만 Dynamo에 대한 주장만큼 심하지는 않습니다. 만약 데이터센터와 시설의 모든 측면(전력, 냉각, 공간)이 소프트웨어 제어 하에 놓이게 된다면, 그때는 이것을 OS라고 부를 수 있을지도 모릅니다. 우리는 이것이 단지 관리 및 모델링 소프트웨어일 뿐이라고 생각합니다. 이에 대한 판단은 여러분의 몫입니다.
DSX OS 소프트웨어 스택의 모습은 다음과 같습니다:

그리고 훨씬 더 상세한 버전의 스택은 다음과 같습니다:
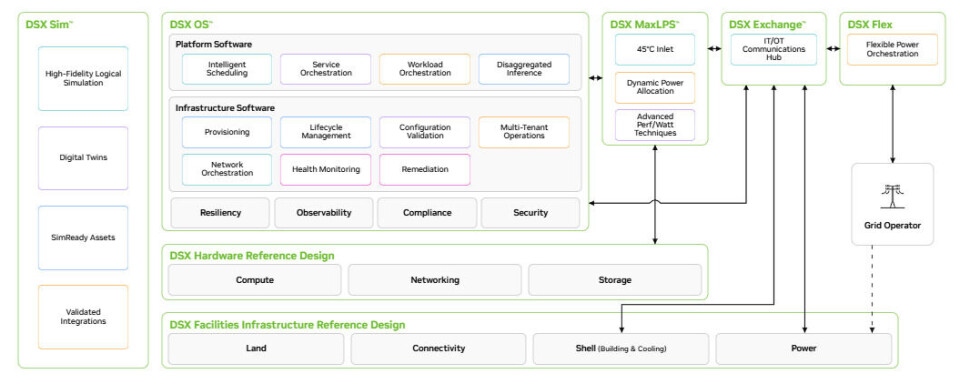
초기 DSX 소프트웨어는 여러 단계에 걸쳐 진화해 왔으며, 2025년 10월 프리뷰 당시에는 Omniverse DSX Blueprint라고 불렸습니다. 이는 기본적으로 Nvidia 장비가 탑재된 메가와트(MW) 및 기가와트(GW) 규모의 데이터센터를 설계하고 운영하기 위한 디지털 트윈 (Digital Twin)이었습니다. 현재는 DSX Sim이라고 불립니다.
잘 아시다시피, 요즘의 모든 스택은 스택의 요소들이 서로 통신할 수 있도록 공통 API (Application Programming Interface)로 시작하며, DSX OS도 예외는 아닙니다. DSX OS 스택의 두 번째 모듈인 DSX Exchange는 지난 3월에 발표되었으며, 인프라의 모든 요소가 서로 통신할 수 있게 해주는 API 허브 (API hub) 역할을 합니다. 이는 AI 데이터센터 내 서버의 GPU (Graphics Processing Unit) 효율성을 극대화하기 위해서는 데이터센터의 맥락과 매 순간 사용할 수 있는 전력 범위 내에서 작업을 수행해야 하기 때문에 매우 중요합니다. 일부 제어 텔레메트리 (Control telemetry)는 하단에서 상단으로 흐르고, 일부는 상단에서 하단으로 흐릅니다.
DSX OS 스택의 세 번째 모듈인 DSX Flex는 데이터센터 내의 해당 중앙 API를 전력망 및 운영 제어 시스템과 연결하여, AI 데이터센터가 가용할 수 없는 전력을 요구하지 않도록 합니다.
이 두 소프트웨어는 Nvidia의 현재 플랫폼과 함께 사용할 수 있습니다. 이 플랫폼은 "Grace" Arm 서버 CPU, "Blackwell" B200 및 B300 GPU 가속기, 그리고 NVSwitch 메모리 인터커넥트 (Memory interconnects), BlueField DPU (Data Processing Unit), QuantumX InfiniBand 또는 SpectrumX Ethernet 스케일 아웃 (Scale out) 네트워크의 신중한 조합, 그리고 랙 (Rack)에 통합된 새로운 STX 플래시 스토리지 레이어 (Flash storage layer)를 기반으로 합니다.
올해 말 출시 예정인 "Vera" CPU와 "Rubin" GPU, 그리고 업그레이드된 네트워크 및 스토리지를 기반으로 하는 차세대 Nvidia 플랫폼과 함께, Nvidia는 DSX OS 스택에 더 많은 모듈을 추가하고 있으며, 이 모듈들은 Vera-Rubin 플랫폼의 동적 전력 (Dynamic power) 기능과 연결됩니다.
이 네 번째 모듈은 MaxLPS라고 불리며, LPS가 무엇의 약자인지는 전혀 명확하지 않습니다. 명확한 것은 이 모듈이 무엇을 하는가입니다. Nvidia의 AI 및 HPC 부문 부사장인 Ian Buck이 이번 주 GTC Taipei 행사(대만의 연례 Computex 컨퍼런스와 시기가 겹침)에 앞서 진행된 사전 브리핑에서 설명했듯이, MaxLPS의 핵심은 데이터센터에서 소비되는 전력 대비 최대의 성능을 끌어내는 것입니다.
“DSX MaxLPS는 Vera-Rubin의 차세대 하드웨어 동적 전력 (Dynamic power) 기능과 연동하여 작동하도록 특별히 설계된 기술 스위트입니다. 이를 통해 컴퓨팅 처리량 (Compute throughput)을 조율하고 극대화하며, 전력이 제한된 환경에서 데이터센터 팩토리 GPU의 수를 최적화합니다.”라고 Buck은 설명했습니다. “MaxLPS는 운영자가 낭비되는 모든 전력 (Stranded power)을 회수할 수 있도록 돕습니다. 이는 데이터센터 전체의 모든 GPU, 모든 랙, 그리고 모든 로우 (Row)에 대해 전력을 실시간으로 모니터링하고 할당함으로써 이루어집니다. 이를 통해 데이터센터 운영자는 고정된 전력 용량을 가진 데이터센터 내에 더 많은 GPU와 CPU를 배치할 수 있으며, 이들이 전체 전력 예산 범위 내에서 안전하게 작동할 것임을 확신할 수 있습니다. MaxLPS를 사용하면 AI 팩토리는 동일한 전력 범위 (Power envelope) 내에서 최대 40% 더 많은 GPU를 안전하게 배치할 수 있습니다. 이는 이전에는 불가능했던 40% 더 많은 컴퓨팅, 40% 더 많은 토큰 (Tokens), 그리고 40% 더 많은 수익을 의미합니다.”
이러한 비교는 이전의 Grace-Blackwell 플랫폼을 기준으로 한 것이며, 이것이 Buck에 따르면 Vera-Rubin 플랫폼의 주문서가 가득 차 있는 이유 중 하나입니다. 핵심 아이디어는 대규모 추론 (Inference)을 수행하는 AI 슈퍼컴퓨터를 운영할 때 수익 창출 시간 (Time to revenue)을 단축하고 와트당 토큰 (Tokens per watt)을 높이는 것입니다.
다음은 DSX OS 스택 구성 요소들의 블록 다이어그램과 이들이 서로 어떻게 연결되는지를 보여줍니다:
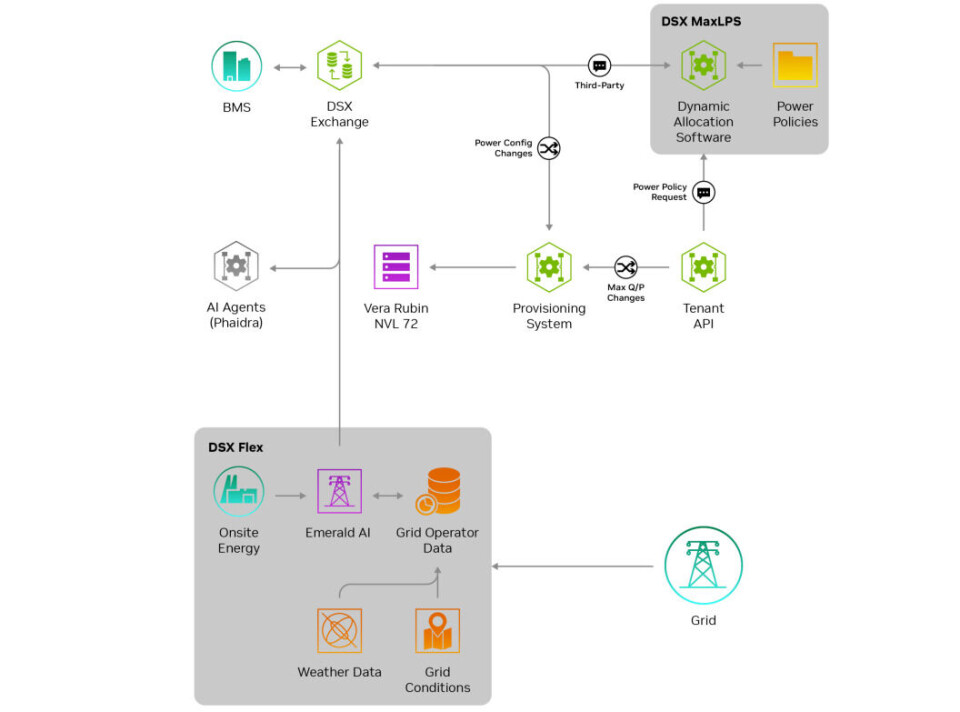
Nvidia는 DSX OS가 개방형(Open)이자 모듈형(Modular)이라고 밝히며, 데이터센터와 전력망(Power grids)의 모든 요소를 위한 다양한 관리 도구들이 DSX OS에 플러그인(Plug-in) 형태로 연결될 수 있도록 의도되었다고 말합니다. 여기서 '개방형(Open)'이 '오픈 소스(Open source)'를 의미하는 것은 아니므로, 성급하게 결론을 내리지 마십시오. 모든 기업이 자신의 도구를 DSX OS에 연결하기 위해 공개할 것은 아니며, Nvidia가 스택(Stack) 뒤에 숨겨진 모든 코드를 공개할지도 불분명합니다.
스택의 구성 요소 중 DSX OS 모듈로 명시되지는 않았지만, 거의 확실하게 오픈 소스이면서 모듈의 일부인 부분들이 있습니다. 예를 들어, GPU의 상태를 관리하고 Kubernetes 컨테이너 환경에서 실행되는 애플리케이션의 문제를 자동으로 복구(Automagically remediating)하는 도구인 NVSentinel은 오픈 소스입니다. Kubernetes에서 실행되는 AI 워크로드(Workloads)를 위한 KAI Scheduler와 AI 스택을 위한 Nvidia Cloud Functions 제어 평면(Control plane) 및 컴퓨팅 프레임워크(Compute framework) 역시 마찬가지입니다. DSX Exchange API 허브와 통합 모듈도 오픈 소스입니다. Nvidia는 시스템 소프트웨어에 대해 Apache 2.0 라이선스를 선호하는 경향이 있습니다.
개방 여부와 상관없이, 우리는 많은 네오클라우드(Neoclouds), 소버린(Sovereigns), 그리고 기업들이 바퀴를 다시 발명하려(Reinvent the wheel) 노력하지 않고, Nvidia의 하드웨어(Iron)로 구축된 AI 데이터센터를 관리하기 위해 DSX OS를 채택할 것이라고 생각합니다. 심지어 다른 기업들이 DSX Exchange를 가져가 자신들의 데이터센터 관리 평면(Management plane)의 핵심에 배치할 가능성도 있습니다. (AMD, 당신들에게 하는 말입니다.) 데이터센터에서 AI 시스템을 거쳐 전력망까지 이어지는 단일 API 메시징 통합(API messaging integration)을 갖는 것은 좋은 일일 것입니다. 하지만 이런 일이 일어나기 전에는 지옥이 차가워져야 할지도 모릅니다. 즉, Nvidia와 AMD의 주요 고객들이 소란을 피우기 시작해야 한다는 뜻입니다.
이에 대한 상용 지원(Commercial support) 비용이 얼마나 들지는 하늘만이 알겠지만, 저렴하지는 않을 것이라고 가정하십시오. Nvidia는 언젠가 자신의 손익계산서(P&L)에 소프트웨어 비즈니스를 포함시키기를 여전히 원하고 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기