microsoft/VibeVoice
요약
VibeVoice는 Microsoft가 공개한 Whisper 스타일의 음성 인식 모델로, 화자 구분(speaker diarization) 기능이 내장되어 있어 대화 녹음물에서 여러 화자를 정확하게 식별할 수 있습니다. 이 모델은 mlx-audio 라이브러리와 함께 Mac 환경에서 효율적으로 실행될 수 있으며, 테스트 결과 1시간 분량의 오디오를 약 8분 45초 만에 처리하는 뛰어난 성능을 보여주었습니다. 다만, 최대 1시간까지만 처리할 수 있어 긴 오디오는 분할하여 전사해야 하며, 오류 방지를 위해 분할 지점마다 일정 시간의 중복 구간을 포함하고 화자 ID를 재정렬하는 추가 작업이 필요합니다.
핵심 포인트
- VibeVoice는 Whisper 스타일의 ASR 모델로, 내장된 화자 구분(speaker diarization) 기능이 특징입니다.
- Mac 환경에서 mlx-audio와 함께 실행 시 1시간 오디오를 약 8분 45초 만에 처리하는 높은 효율성을 입증했습니다.
- 전사 결과는 JSON 형식의 객체 배열로 제공되며, 각 발화의 시작 시간과 텍스트가 포함됩니다.
- 모델은 최대 1시간까지만 전사가 가능하므로, 긴 오디오 파일은 분할하고 중복 구간을 추가하여 오류를 최소화해야 합니다.
microsoft/VibeVoice. VibeVoice 는 Microsoft 의 Whisper 스타일 음성 인식 모델로, MIT 라이선스를 따르며说话者 구분 (speaker diarization) 기능이 모델에 내장되어 있습니다.
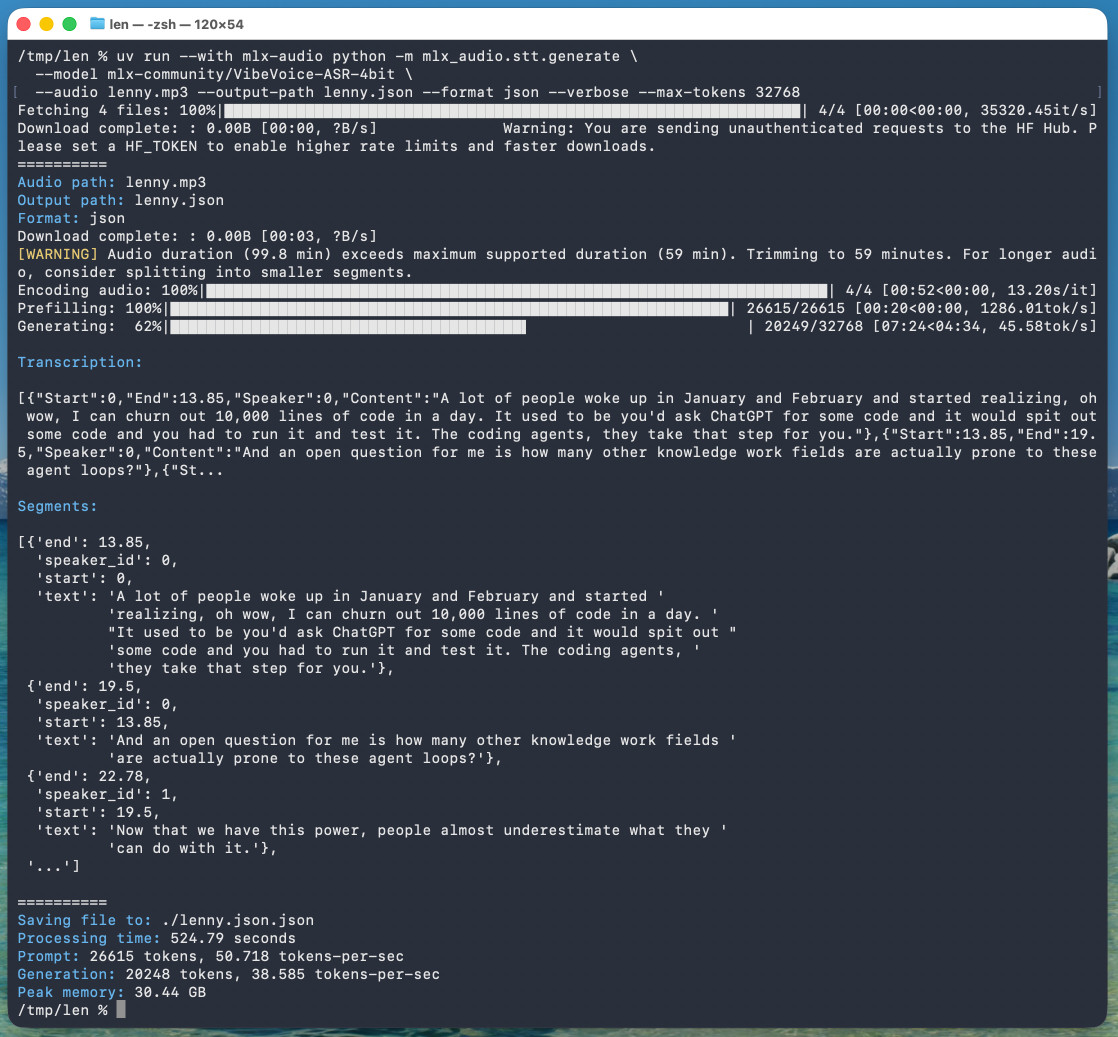
Microsoft 는 2026 년 1 월 21 일에 이를 공개했지만, 저는 오늘까지 시도하지 않았습니다. Mac 에서 실행하는 한 줄 명령어는 다음과 같습니다:
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
...
이 명령은 17.3GB 의 VibeVoice-ASR 모델을 5.71GB 로 변환한 mlx-community/VibeVoice-ASR-4bit 모델과 Prince Canuma 의 mlx-audio 를 사용하여, 제가 최근 Lenny Rachits ky 와 함께 출연한 팟캐스트 녹음물을 다운로드한 파일에 대해 실행했습니다.
도구는 다음과 같이 결과를 보고했습니다:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
...
즉, 오디오 1 시간 (128GB M5 Max MacBook Pro 에서 실행) 을 8 분 45 초에 처리했습니다.
저는 .wav 와 .mp3 파일 모두 테스트했고, 둘 다 정상 작동했습니다.
--max-tokens 를 생략하면 기본값이 8192 로 설정되며, 이는 약 25 분의 오디오에 충분합니다. 저는 시행착오를 통해 이를 발견하고, 전체 시간을 보장하기 위해 4 배로 늘렸습니다.
이 명령은 최대 RAM 사용량이 30.44GB 로 보고되었으나, Activity Monitor 에서 prefill 단계 동안 61.5GB 를 사용하고 생성 단계 동안 약 18GB 를 사용함을 관찰했습니다.
결과 JSON 은 다음과 같습니다. 키 구조는 다음과 같습니다:
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
...
}
이것은 객체 배열이기 때문에 Datasette Lite 에서 열 수 있습니다.
흥미롭게도 이 Datasette Lite 뷰는 3 명의说话者를 보여줍니다 - 대화에서 Lenny 와 저를 식별했고, 추가 인트로와 스폰서드 읽기 (sponsor reads) 를 위한 별도의 목소리를 가진 Lenny 를 식별했습니다.
VibeVoice 는 최대 1 시간의 오디오만 처리할 수 있으므로, 위의 명령은 팟캐스트의 첫 1 시간을 전사했습니다. 더 많은 오디오를 전사하려면 오디오를 분할해야 하며, 부분적으로 전사된 단어에서 발생하는 오류를 피하기 위해 분할 지점에서 약 1 분 정도의 중복을 포함하는 것이 이상적입니다. 또한 여러 세그먼트에 걸쳐 식별된说话者 ID 를 정렬해야 합니다.
최근 기사
- LLM 0.32a0 는 주요 후방 호환성 리팩토링 - 2026 년 4 월 29 일
- 이제 폐지된 OpenAI Microsoft AGI 조항의 역사 추적 - 2026 년 4 월 27 일
- DeepSeek V4 - 거의 최전선에, 가격의 일부만 - 2026 년 4 월 24 일
AI 자동 생성 콘텐츠
본 콘텐츠는 Simon Willison Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기