
HPC 슈퍼컴퓨팅 분야에서 막상막하인 AMD와 Nvidia
요약
중국이 자체 개발한 CPU 기반의 'LineShine' 슈퍼컴퓨터를 통해 세계 최고 수준의 엑사스케일 컴퓨팅 성능을 달성했습니다. 이는 AMD MI300A 기반의 El Capitan보다 강력한 성능을 보여주며, 중국의 독자적인 가속기 및 컴퓨팅 엔진 설계 역량을 입증합니다.
핵심 포인트
- 중국 LineShine 슈퍼컴퓨터가 HPL 테스트에서 세계 최상위 성능 기록
- Huawei 협력 Armv9 기반 LingKun LX2 CPU 활용
- AMD MI300A 기반 El Capitan보다 약 21.5% 높은 성능 달성
- 가속기 대신 대규모 CPU 코어와 인터커넥트를 활용한 스케일 아웃 전략

HPC 슈퍼컴퓨팅 분야에서 막상막하인 AMD와 Nvidia
필요는 언제나 발명의 어머니입니다. 만약 중국이 그러하듯 독자적인 컴퓨팅 엔진 설계 및 제조 역량을 구축하려 한다면, 중국의 8개 국가 컴퓨팅 센터가 슈퍼컴퓨터를 위한 자체 가속기(accelerators)를 구축할 뿐만 아니라, 오프로드 모델(offload model)을 사용하지 않고 단순히 MPI를 사용하여 전통적인 스케일 아웃(scale out) 네트워크 전체에 계산을 분산시키는 올-CPU(all-CPU) 머신을 만드는 것도 타당한 일입니다.
이런 방식으로 중국은 실질적인 한계가 공간과 전력에 국한되는 비교적 단순한 대형 머신을 만들 수 있습니다. 무기를 설계하고 모든 과학 분야의 최첨단 기술을 발전시키기 위해, 중국은 가속 컴퓨팅 설계로 밀도를 높이는 대신 규모를 키울 수 있는 자금과 권력을 가지고 있습니다.
그리고 그것이 바로 중국이 몇 년 전 NSC Wuxi를 위해 "OceanLight" 슈퍼컴퓨팅을 구축할 때 했던 방식입니다. 이는 자체 개발한 Sunway SW26010-Pro CPU를 기반으로 하며, 약 1.5 exaflops의 이론적 최대 성능을 제공하기 위해 4,193만 개의 코어를 보유하고 있습니다. 또한 중국은 NSC Shenzhen에 설치되어 현재 세계에서 가장 빠른 슈퍼컴퓨터가 된 "LineShine" 슈퍼컴퓨터를 만들기 위해 이 방식을 다시 한번 적용했습니다.
저는 별도의 기사에서 LineShine 머신(아마도 영어로 "sunbeam"이라고 부르는 것의 직역일 것입니다)의 아키텍처를 심층 분석할 예정이지만, 일반적으로 말해서 LineShine은 NSC Shenzhen이 중국의 IT 거대 기업인 Huawei(아마도 그들의 HiSilicon 칩 부문)와 협력하여 설계한 Armv9 호환 서버 CPU를 기반으로 합니다. LingKun LX2 CPU 설계는 304개의 활성 코어를 가지고 있으며, 수율을 높이기 위해 칩에 더 많은 코어가 있을 가능성이 매우 높습니다. LineShine 머신은 독자적인 LingQi LQLink 인터커넥트(interconnect)를 갖추고 있는데, 저는 이것이 InfiniBand 기술의 변형을 기반으로 하고 있다고 확신하지만, Ethernet의 개조되고 간소화된 버전일 수도 있습니다.
결론은 — 또는 LineShine가 공식적으로 제출된 High Performance Linpack (HPL) 테스트 결과에서 슈퍼컴퓨터 중 최상위 순위를 기록했다는 점을 고려하면 '최상단(top line)'이라 할 수 있겠는데 — 이 LX2 CPU가 SVE2 벡터 유닛을 통해 충분한 FP64 성능(oomph)을 제공하여, 단 1,379만 개의 코어만으로도 2.74 엑사플롭스(exaflops, 유효 숫자 3자리 반올림)의 이론적 최대 성능을 낼 수 있다는 것입니다. HPL 테스트에서 LineShine은 2.2 엑사플롭스에 약간 못 미치는 성능을 보여주었으며, 이는 미국 로렌스 리버모어 국립연구소(Lawrence Livermore National Laboratory)에 위치한 AMD MI300A 컴퓨팅 엔진 기반의 이전 1위 머신인 "El Capitan" 슈퍼컴퓨터보다 21.5% 더 강력하다는 것을 의미합니다.
중국이 슈퍼컴퓨터 분야에서 다시 정상에 올라섰으며, 우리는 중국이 대외적으로 많이 언급하지 않는 여러 대의 엑사스케일 (exascale) 머신을 더 보유하고 있을 것이라고 강력하게 의심하고 있습니다. 우리는 NSC Wuxi의 앞서 언급한 1.5 엑사플롭스 OceanLight 시스템과 NSC Guangzhou의 2.05 엑사플롭스 Tianhe-3A 슈퍼컴퓨터를 알고 있습니다. 하지만 Nicole과 제가 수년간 모두에게 상기시켜 왔듯이, 중국은 공식적인 Top500 결과를 제출하지 않았더라도 엑사스케일 경쟁에서 앞서 있었습니다.
목록에 있는 상위 10대 머신을 모두 살펴보지는 않겠습니다. 직접 읽어보실 수 있으며, 어차피 모두가 그렇게 하니까요. 저는 제 논평에 가치를 더하고 싶으며, 2024년 6월 순위부터 시작했던 방법론을 고수할 것입니다. 즉, 이번 목록에 새로 추가된 머신들만 살펴보고, HPC 본연의 목적에서 벗어나게 만드는 클라우드 제공업체 및 통신사(주로 중국 내)의 방대한 머신들은 무시하는 방식입니다. 이 머신들은 실제 HPC 작업을 수행하고 있지 않으며, 모두가 그 사실을 알고 있습니다.
그렇긴 하지만, 우리가 2년마다 성능이 두 배로 향상되는 무어의 법칙 (Moore’s Law)의 궤도에서 여전히 벗어났으며, 적어도 슈퍼컴퓨팅 분야에서는 그 궤도에 올라타기 위한 충분한 비용을 지출하지 않고 있다는 점을 상기할 필요가 있습니다. 다음을 보십시오:
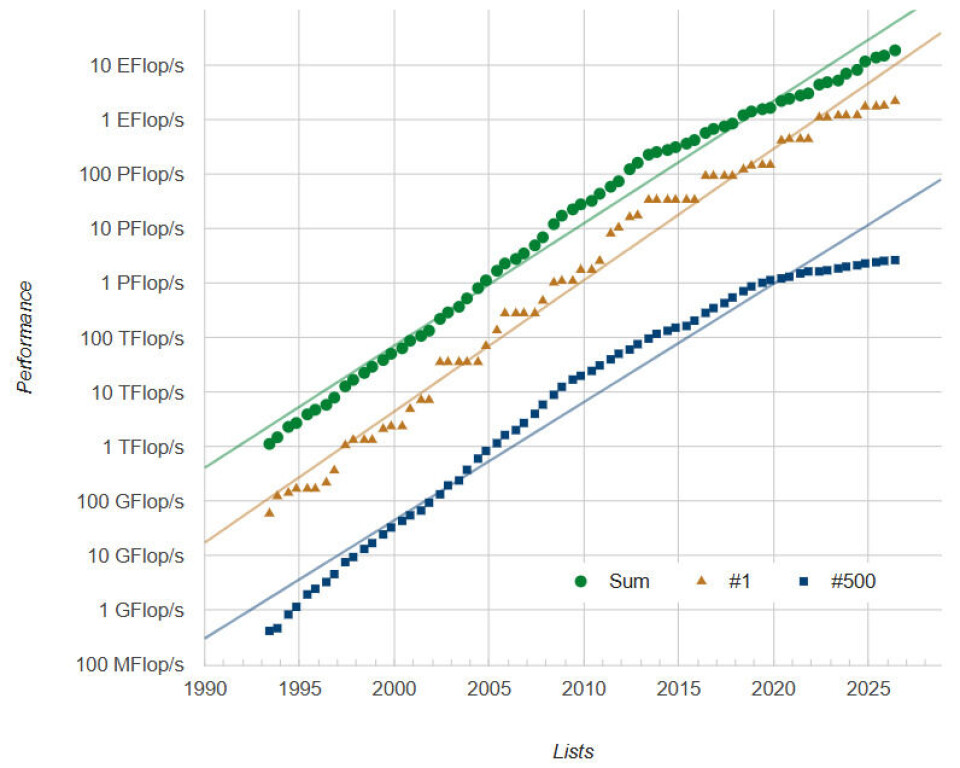
이것은 기술적인 문제라기보다는 예산의 문제입니다.
어떤 벤더가 Top500 순위에서 얼마만큼의 점유율을 차지하고 있는지 살펴보는 것도 흥미롭습니다. 여기 집계된 용량(aggregated capacity)별 점유율을 보여주는 멋진 트리맵(treemap)이 있습니다. 토큰(tokens)과 마찬가지로 플롭스(flops)가 곧 돈이기 때문에, 용량이 중요한 지표입니다.
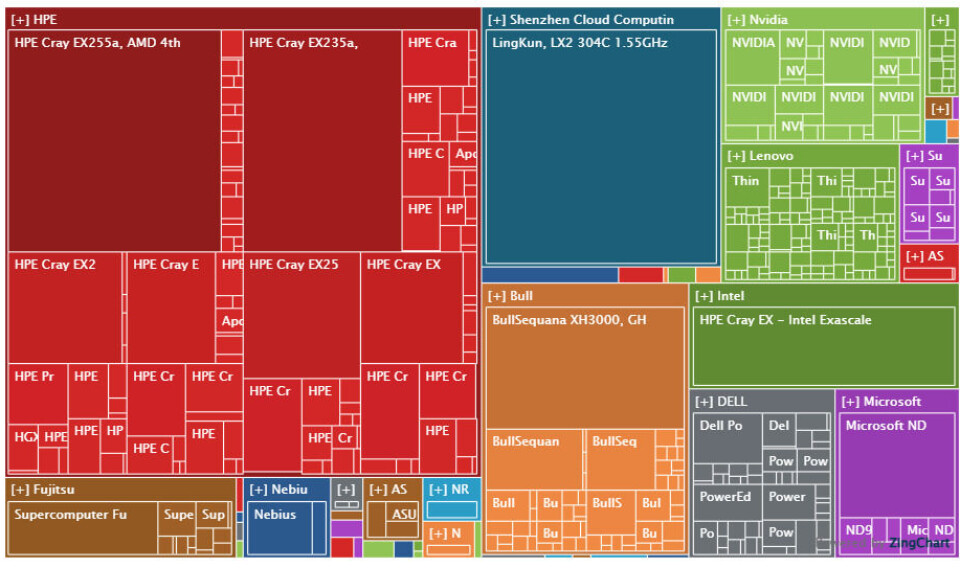
공식적인 5개의 엑사플롭스(exafloppers)급 시스템이 용량 측면을 지배하고 있으며, HPL 성능이 400 페타플롭스(petaflops)를 넘는 나머지 5대의 머신 또한 수많은 작은 머신들을 밀어내고 있습니다. 이번 리스트에 이름을 올리기 위해서는 최소 2.66 페타플롭스(petaflops)의 HPL 성능을 갖춰야 합니다. 솔직히 현대적인 CPU나 GPU에서 얻을 수 있는 성능을 고려하면 이는 그리 높은 수치는 아닙니다.
그럼 이제 2026년 6월 Top500 리스트에 새로 등장한 머신들을 살펴보겠습니다. 각 아키텍처(architecture) 내에서 아키텍처와 크기별로 정렬된 목록은 다음과 같습니다:
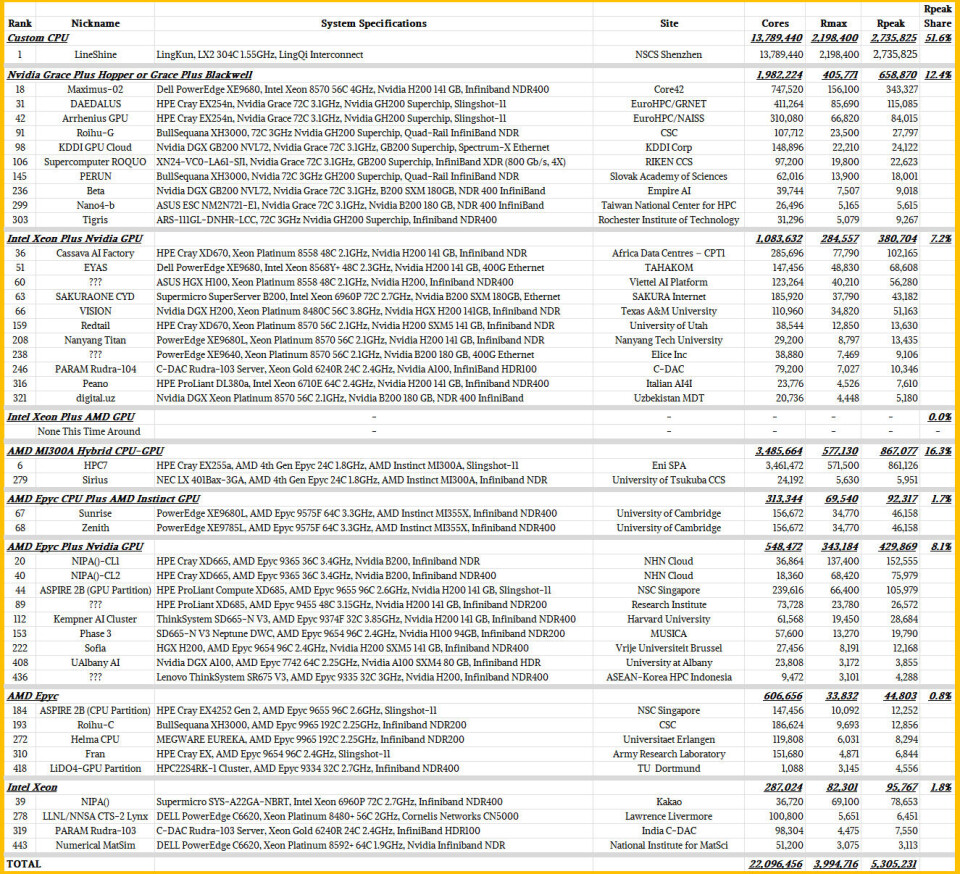
이번에는 44대의 새로운 머신이 등장했습니다. 여기서 즉각적으로 눈에 띄는 사실 한 가지는, 6월 리스트에 추가된 총 5.3 엑사플롭스(exaflops) 용량의 51.6%를 차지하는 LineShine 머신의 압도적인 점유율을 제외하면, 일부 HPC 센터들이 관망세를 유지하며 가속기(accelerators)를 사용하는 머신에 차세대 모델 대신 "Hopper" H100 및 H200 GPU를 설치하는 것을 선호하고 있다는 점입니다. 이는 분명한 이유가 있습니다. 첫째, Hopper GPU가 더 저렴하며, 후속 모델인 "Blackwell" B200 및 B300 GPU보다 FP64 플롭스(flops)가 더 많고 달러당 플롭스(flops per dollar) 효율도 더 높기 때문입니다. Nvidia 컴퓨팅 엔진만을 사용하는 가장 강력한 신규 머신들은 Hopper를 기반으로 하고 있지만, Blackwell을 사용하는 클러스터(clusters)도 3개가 존재합니다.
또 다른 주목할 점은 Intel Xeon 프로세서와 Nvidia GPU가 결합된 클러스터(clusters)가 매우 많다는 것입니다. 이는 일반적인 세상과 마찬가지로 HPC 분야에서도 CPU에 대한 선호도와 편견이 존재하기 때문에 타당한 결과입니다. 또한 GenAI(생성형 AI)로 인해 광기 어린 상황이 된 세상에서 가격과 가용성 문제도 고려해야 합니다. 6월 리스트에는 이러한 형태의 신규 머신이 11대 있었으며, AMD Epyc CPU와 Nvidia GPU가 쌍을 이룬 머신도 9대가 있었습니다. 이 하이브리드 아키텍처(hybrid architectures)들은 설치된 flops 용량의 15.3%를 차지했습니다.
또 다른 대형 신규 머신은 이탈리아의 석유 및 가스 거대 기업인 Eni의 HPC7 시스템으로, AMD의 하이브리드 CPU-GPU MI300A 가속기를 기반으로 합니다. HPC7은 본질적으로 El Capitan의 축소판이며, 리스트에서 6위를 기록했습니다. 이는 결과값을 제출한 상업용 슈퍼컴퓨터 중 가장 큰 규모입니다. (이를 가장 큰 상업용 슈퍼컴퓨터와 혼동하지 마십시오. 전 세계 석유 메이저 기업들이 보유한 더 큰 규모의 머신이 얼마나 될지는 알 수 없습니다. 그들은 자랑을 잘 하지 않습니다.) 이 두 대의 MI300A 시스템은 새로운 flops 용량의 16.3%를 차지합니다. 또한 보시는 바와 같이 개별적인 AMD CPU와 GPU를 혼합한 머신이 2대 있으며, 이는 용량의 1.7%를 추가합니다.
남은 것은 CPU 전용(CPU-only) 그룹입니다. AMD Epyc 프로세서를 유일한 연산 엔진으로 사용하는 신규 HPC 클러스터가 5개 있으며, 이는 전체 신규 flops의 0.8%를 차지합니다. 또한 4개의 신규 Intel Xeon 클러스터가 용량의 1.8%를 추가했습니다. CPU 전용 머신들이 세상을 장악하고 있지는 않지만, 사라지지도 않을 것입니다.
다음은 지난 5개의 리스트 동안 추가된 신규 머신들의 코어 수(core counts), HPL 상의 Rmax, 그리고 Rpeak 성능을 비교한 흥미로운 작은 표입니다:
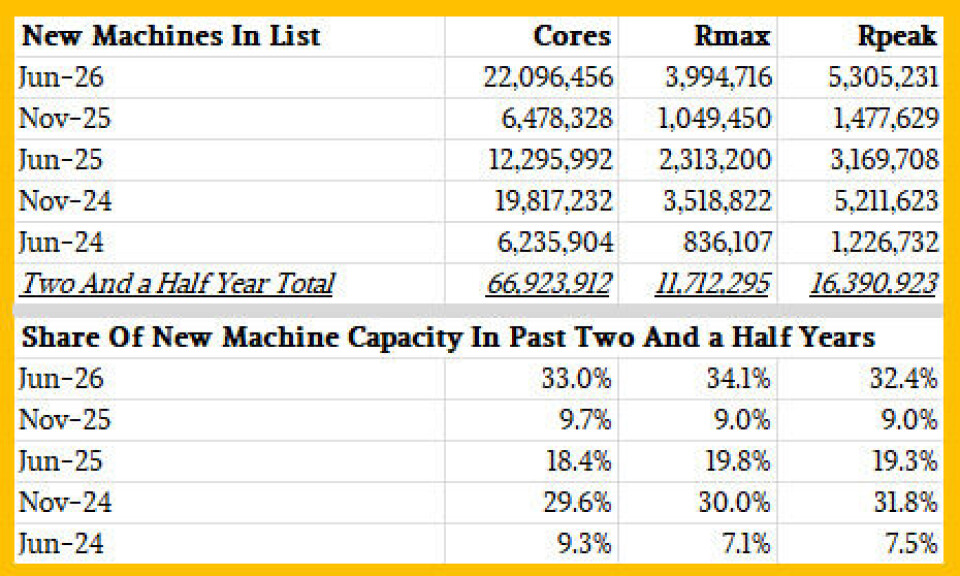
보시다시피, HPC 분야의 업그레이드는 파동(waves) 형태로 나타나며 제품 주기(product cycles)를 따릅니다. 2024년 6월과 2025년 11월은 새로 설치된 용량 측면에서 상대적으로 약세였던 반면, 2026년 6월과 2024년 11월은 특히 강력했습니다. 그리고 덧붙이자면, 이 시기들은 엑사스케일급 (exascale-class) 머신들의 설치가 주도했습니다. 다시 한번 말씀드리지만: 이것은 HPC 슈퍼컴퓨팅 전체에 대한 진술이 아니라, Top500 HPL 벤치마크 결과를 제출한 설치된 HPC 시스템들에 대한 것입니다. 하지만 더 넓고 때로는 비밀스러운 HPC 시장은 아마도 공식 리스트를 어느 정도 반영할 것이며, 이것이 바로 우리가 애초에 Top500 커버리지를 다루는 이유입니다.
이제 드디어 가속 컴퓨팅 (accelerated computing) 표로 넘어가겠습니다. Top500 사이트의 목록에 따르면, 어떤 종류의 가속 기능이 포함된 머신은 274대입니다 (비록 사이트의 텍스트에는 277대라고 적혀 있지만 말입니다). 제 계산을 세 번 확인했고, 이 정도면 충분합니다. 이 274대의 머신에 대한 아키텍처별 분류는 다음과 같습니다:
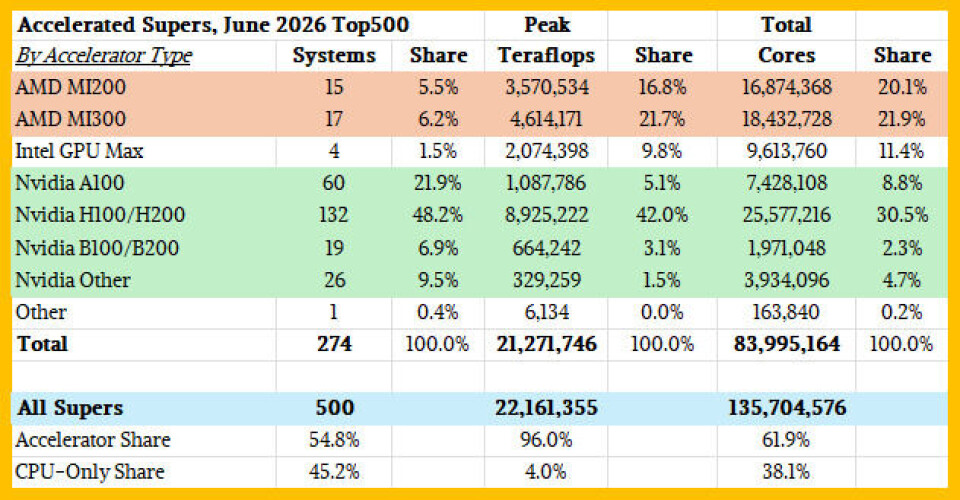
Nvidia는 머신 수 기준으로 AMD의 32대와 비교하여 237대의 시스템을 보유하며 압도하고 있습니다. 하지만 피크 플롭스 (peak flops) 기준으로 보면, AMD는 8.18 엑사플롭스 (exaflops)의 설치 용량을 보유하고 있으며, 이는 Nvidia의 11 엑사플롭스에 비해 적습니다. 또한 동시성 (concurrency) 측면에서 AMD는 CPU와 GPU를 결합한 총 3,530만 개의 코어를 가진 가속 머신을 판매했으며, 이는 Nvidia의 3,890만 개 코스와 비교됩니다. 이것은 진정한 경주이며, 어쩌면 AI 컴퓨팅의 미래를 예고하는 것일지도 모릅니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기