EvoPolicyGym: 자율적 정책 진화를 위한 벤치마크
요약
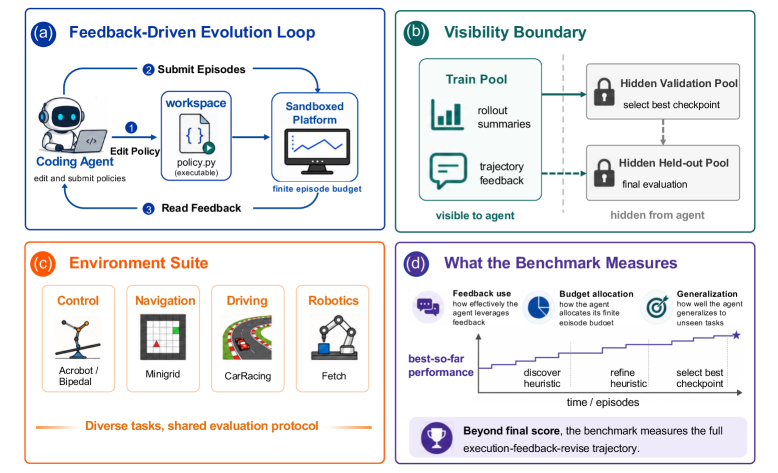
자율적 정책 진화를 평가하기 위한 새로운 벤치마크인 EvoPolicyGym을 소개합니다. 코딩 에이전트가 제한된 예산 내에서 강화학습 환경의 정책을 수정하고 개선하는 과정을 분석합니다.
핵심 포인트
- 자율적 정책 진화를 위한 벤치마크 EvoPolicyGym 공개
- 16개의 강화학습 환경에서 코딩 에이전트의 성능 평가
- 에이전트의 예산 배정, 탐색, 개선 과정을 궤적 진단으로 분석
- GPT-5.5 모델이 해당 벤치마크에서 선도적인 성능을 보임
EvoPolicyGym
자율적 정책 진화 (autonomous policy evolution)를 위한 벤치마크입니다.
코딩 에이전트 (Coding agents)들이 16개의 강화학습 (RL) 환경에서 정해진 상호작용 예산 (interaction budget) 내에서 실행 가능한 정책 (executable policies)을 수정합니다.
GPT-5.5가 이 제품군을 선도하지만, 궤적 진단 (trajectory diagnostics)을 통해 에이전트들이 어떻게 예산을 배정하고, 탐색하며, 개선하는지 밝혀냅니다. https://t.co/kNvOeGHLsu
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기0