DVAO: 다중 보상 강화학습 (RL)을 위한 동적 분산 적응형 어드밴티지 최적화
요약
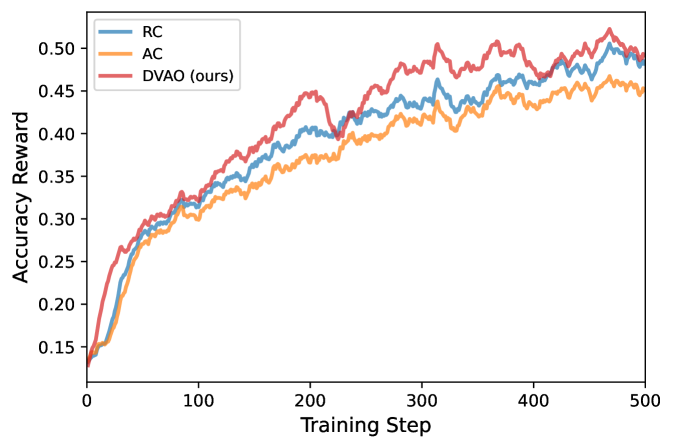
DVAO는 다중 보상 강화학습에서 보상 분산에 따라 가중치를 동적으로 조정하여 학습을 안정화하는 최적화 기법입니다. Alibaba의 Qwen 모델을 통해 수학적 추론 및 도구 사용 성능을 크게 향상시켰습니다.
핵심 포인트
- 경험적 보상 분산 기반의 동적 가중치 조정
- 노이즈가 심한 목적 함수의 영향 억제 및 학습 안정화
- Qwen3 및 Qwen2.5 기반 수학/도구 사용 벤치마크 우수성 입증
- 우수한 다중 목적 파레토 프런티어 달성
DVAO
다중 보상 강화학습 (RL)을 위한 동적 분산 적응형 어드밴티지 최적화 (Dynamic Variance-adaptive Advantage Optimization)입니다. 이는 경험적 보상 분산 (empirical reward variance)을 기반으로 결합 가중치를 동적으로 조정하여, 강력한 학습 신호의 가중치는 높이고 노이즈가 심한 목적 함수 (objectives)는 억제함으로써 학습을 안정화합니다.
DVAO는 Alibaba의 Qwen3 및 Qwen2.5를 사용하여 수학적 추론 및 도구 사용 (tool-use) 벤치마크에서 베이스라인 모델들을 크게 능가하며, 우수한 다중 목적 파레토 프런티어 (multi-objective Pareto frontier)를 달성합니다.
논문:
SciAtlas
4,300만 개의 논문, 1억 5,700만 개의 엔티티 (entities), 30억 개의 트리플렛 (triplets)을 인지 지도 (cognitive map)로 매핑한 대규모 지식 그래프입니다. 이를 통해 AI 에이전트는 단순히 키워드를 검색하는 대신 여러 학문 분야를 가로질러 추론할 수 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @huggingpapers (검증됨)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기