
Deep Agents의 동적 서브에이전트 (Dynamic Subagents) 소개
요약
Deep Agents가 대규모 작업의 안정성과 컨텍스트 관리를 위해 '동적 서브에이전트' 방식을 도입했습니다. 이는 단순 도구 호출 대신 에이전트가 직접 오케스트레이션 스크립트를 작성하여 실행하는 프로그래밍 방식의 접근법입니다.
핵심 포인트
- 도구 호출 대신 코드를 통한 프로그래밍 방식의 오케스트레이션 구현
- 대규모 작업 시 루프와 병렬 처리를 통한 결정론적 커버리지 보장
- 복잡한 다단계 파이프라인 및 조건부 분기의 신뢰성 향상
- 메인 컨텍스트 창의 오염을 방지하고 효율적인 컨텍스트 격리 제공
에이전트(Agents)가 더 야심 찬 과업을 수행함에 따라, 다음과 같은 어려움을 겪고 있습니다:
- 대규모 작업의 안정적인 완료
- 자체적인 컨텍스트 (Context) 관리
우리는 이러한 과제들을 해결하기 위해 *동적 서브에이전트 (Dynamic Subagents)*라고 부르는 방식으로 실험을 진행해 왔습니다. 일반적인 도구 호출 (Tool calling)을 통해 서브에이전트 작업을 지시하는 대신, 에이전트가 서브에이전트 실행을 구동하는 짧은 스크립트를 작성하는 방식입니다. 이는 모델이 자신이 잘 작성할 수 있는 코드 패턴(루프, 분기 또는 병렬성 등)에 의존하여, 해당 작업에 적합한 오케스트레이션 (Orchestration) 로직을 작성할 수 있음을 의미합니다.
왜 동적 서브에이전트인가?
Deep Agents는 이미 서브에이전트를 지원합니다. 서브에이전트는 컨텍스트를 격리하고, 메인 에이전트가 개별적인 작업 단위를 위임할 수 있게 하며, 중간 결과물이 메인 컨텍스트 창 (Context window)에 쌓이지 않도록 유지합니다. 그렇다면 왜 동적 서브에이전트가 필요할까요?
일반적인 서브에이전트의 경우, 메인 모델이 직접 호출하는 방식으로 한 번에 하나씩 호출됩니다. 이는 소규모에서는 작동합니다. 하지만 수백 개의 서브에이전트를 생성해야 하거나, 오케스트레이션 로직이 조건부이거나 다단계(Multi-phase)인 경우에는 한계가 발생합니다.
동적 서브에이전트는 이를 **프로그래밍 방식의 오케스트레이션 (Programmatic orchestration)**으로 해결합니다. 턴 바이 턴 (Turn-by-turn)으로 도구 호출을 수행하는 대신, 에이전트는 서브에이전트를 오케스트레이션하고 호출하는 짧은 스크립트를 작성한 뒤, 이를 경량 인터프리터 (Interpreter)에서 실행합니다.
전형적인 예시: 300페이지 분량의 문서에서 페이지당 하나의 서브에이전트를 사용하는 경우입니다. 서브에이전트 도구를 300번 호출하는 대신, 에이전트는 다음과 같이 루프를 작성합니다:
const results = await Promise.all(pages.map(page =>
task({ description: `Summarize page ${page.number}`, subagentType: "summarizer" })
));
``
이는 도구 호출 기반의 오케스트레이션이 안정적으로 제공할 수 없는 두 가지를 가능하게 합니다:
대규모에서의 결정론적 커버리지 (Deterministic coverage at scale). 구조가 없다면, 에이전트는 범위에 대해 임의로 판단하여 500개 항목 중 75개만 검토하고 완료되었다고 판단할 수 있습니다. 하지만 디스패치 루프 (Dispatch loop)는 그렇지 않습니다. 커버리지는 프롬프트 엔지니어링 (Prompt engineering)의 문제가 아니라 구조적인 보증이 됩니다.
신뢰할 수 있는 복잡한 오케스트레이션 (Orchestration). 오케스트레이션을 코드로 작성하는 것은 모델이 이를 일련의 도구 호출 (Tool calls) 시퀀스로 재현하게 하는 것보다 더 신뢰할 수 있습니다. 특히 팬아웃 (Fan-out) + 합성 (Synthesis), 다단계 파이프라인 (Multi-phase pipelines), 또는 조건부 분기 (Conditional branching)의 경우 더욱 그러합니다.
이는 Claude Code와 재귀적 언어 모델 (Recursive Language Models, RLMs)의 워크플로 (Workflows)에 담긴 것과 동일한 아이디어입니다. 즉, 모델이 코드를 작성하면, 그 코드가 더 많은 에이전트들을 배정 (Dispatch)하는 방식입니다.
퀵스타트 (Quickstart)
동적 서브에이전트 (Dynamic subagents)를 사용하려면 두 가지가 필요합니다: 작업을 배정할 서브에이전트, 그리고 코드 인터프리터 (Code interpreter)입니다. 코드 인터프리터는 모델이 오케스트레이션 코드를 작성하고 실행할 수 있는 안전하고 가벼운 런타임 (Runtime)입니다. Deep Agents는 QuickJS를 기반으로 하는 선택적 코드 인터프리터를 포함하고 있습니다. 이를 사용하려면 QuickJS 미들웨어 패키지를 설치한 다음, create_deep_agent의 middleware 인자를 통해 CodeInterpreterMiddleware를 전달하세요.
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
...
Deep Agents에는 범용 서브에이전트가 내장되어 있어, 워크플로에서 즉시 사용할 수 있는 일반 서브에이전트 프로필이 이미 하나 존재합니다. 특화된 워크플로를 위해서는 고유한 이름, 설명, 시스템 프롬프트 (System prompts)를 가진 커스텀 서브에이전트를 구성하세요. 이름과 설명은 에이전트가 어떤 역할을 호출해야 하는지 파악하는 기준이 됩니다.
동적 서브에이전트를 트리거하려면, 다음과 같이 에이전트에게 "workflow"라는 단어를 포함하여 프롬프트를 입력하세요:
result = await agent.ainvoke({
"messages": [{"role": "user", "content": "src/routes/에 있는 모든 파일을 검토하고 주요 리스크를 요약하는 워크플로(workflow)를 실행해줘."}]
})
``
코딩 에이전트와 함께 사용하기
동적 서브에이전트를 가장 빠르게 체험하는 방법은 Deep Agent를 사용하여 구축된 당사의 터미널 코딩 에이전트인 dcode를 사용하는 것입니다. dcode는 코드 인터프리터가 활성화된 상태로 제공되므로 별도의 설정이 필요 없으며, 동적 서브에이전트가 즉시 작동합니다.
설치
curl -LsSf https://langch.in/dcode | bash
실행
dcode
동적 서브에이전트 (dynamic subagents)를 트리거하려면, 단순히 "workflow"를 요청하기만 하면 됩니다. 에이전트는 작업 자체를 직접 수행하거나 고유의 태스크 도구 (task tool)로 서브에이전트의 팬아웃 (fan out)을 관리하려고 애쓰는 대신, 내장된 task() 전역 함수 (global)를 호출하는 오케스트레이션 스크립트 (orchestration script)를 작성하고 이를 코드 인터프리터 (code interpreter)에서 실행합니다. 예를 들어: "src/ 디렉토리의 모든 파일을 SQL 인젝션 (SQL injection) 여부를 검토하는 workflow를 실행해줘."라고 요청할 수 있습니다.
서브에이전트가 생성됨에 따라, dcode는 이들을 디스패치 (dispatch) 단계별로 그룹화하여 동적 서브에이전트 패널에 실시간으로 보여줍니다.
.png)
이 기능은 dcode에서 가장 빠르게 체험해 볼 수 있지만, ACP (예: Zed)를 통해 원하는 도구에서 사용할 수도 있습니다.
작동 원리
에이전트에게는 eval 도구가 주어집니다. 에이전트는 인터프리터 내부에서 안전하게 실행되는 JavaScript를 작성합니다. 서브에이전트가 구성되면, 인터프리터는 코드에서 서브에이전트를 디스패치할 수 있는 내장 task() 전역 함수를 노출합니다. 당면한 작업에 따라 모델은 루프 (loop), 분기 (branch), Promise.all 등 서로 다른 코드를 작성하며, 인터프리터는 이를 결정론적 (deterministically)으로 실행합니다.

task()는 description (설명), subagentType (서브에이전트 유형), 그리고 선택 사항인 responseSchema (응답 스키마)를 인자로 받습니다. responseSchema가 제공되면 결과는 이미 타입이 지정된 객체 (typed object)로 반환되어, 필터링하거나 다음 단계로 전달할 준비가 된 상태가 됩니다.
const result = await task({
description: "src/auth/login.ts의 보안 문제를 검토하세요.",
subagentType: "reviewer",
...
더 자세한 내용은 문서의 Programmatic subagents 및 Interpreters 섹션을 참조하세요.
일반적인 오케스트레이션 패턴 (Common Orchestration Patterns)
Anthropic의 동적 워크플로우 (dynamic workflows)는 병렬 에이전트 작업을 위한 일련의 오케스트레이션 패턴들을 대중화했습니다. 이것들은 단순히 켜고 끄는 기능이 아닙니다. 작업 과정에서 자연스럽게 나타나는 형태들이며, 에이전트는 작업이 변함에 따라 그에 맞는 형태로 전환됩니다. 아래 표는 각 형태를 적합한 작업 유형에 매핑한 것입니다.
아래에서는 실시간 트레이스 (live traces)와 함께 Deep Agents에서 각 패턴이 어떻게 작동하는지 자세히 살펴보겠습니다. 또한 이 여섯 가지 패턴을 설명하는 영상도 준비했으니 [여기]에서 확인하실 수 있습니다.
분류 및 실행 (Classify and act)
항목들을 먼저 분류한 다음, 분류된 결과에 따라 각 항목을 전문화된 서브에이전트 (subagent)가 처리합니다. 이를 통해 서로 다른 전문 지식이 필요한 다양한 항목들이 섞인 입력을 처리할 수 있습니다.
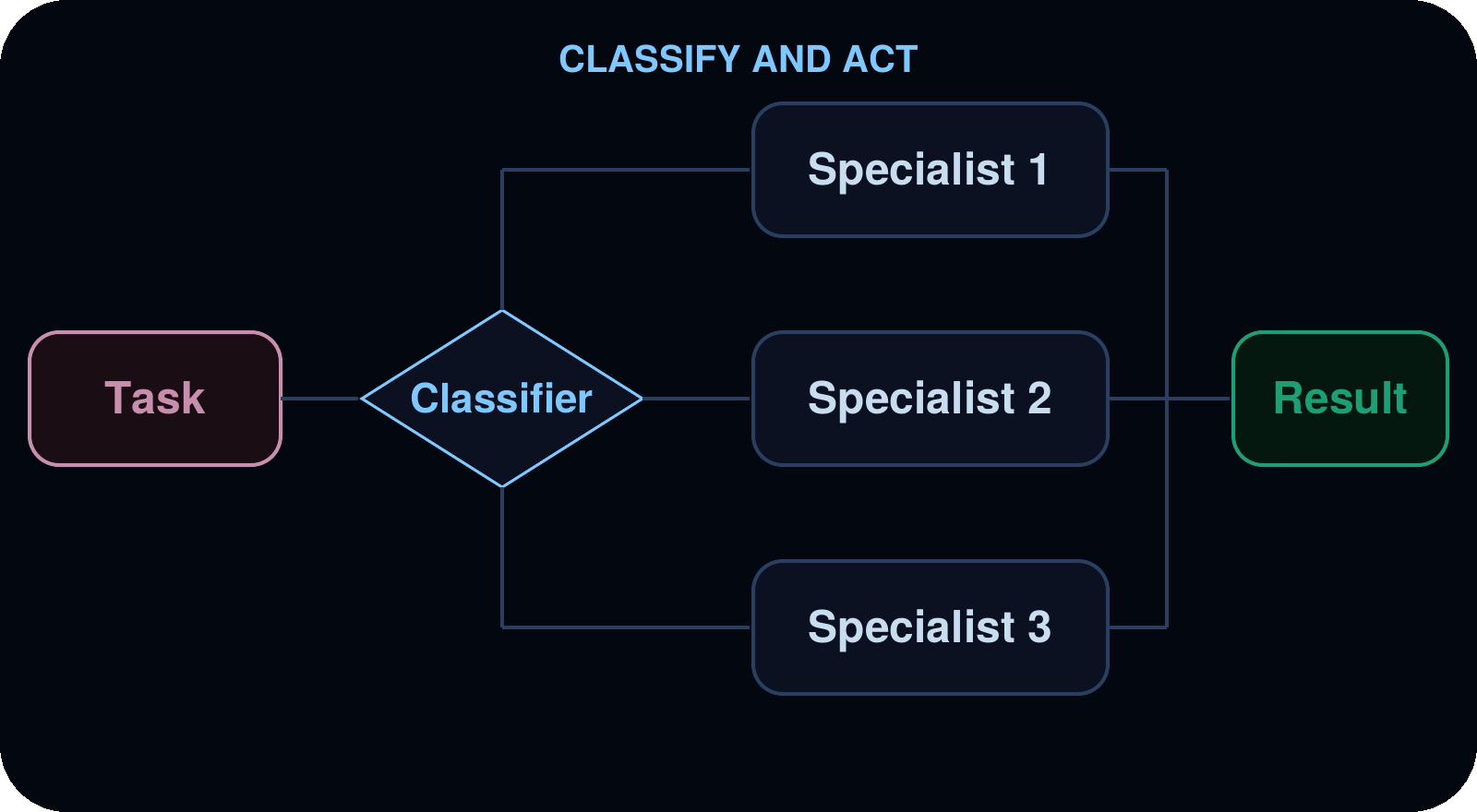
사용 사례 (Use cases): 지원 티켓 (support tickets), 에러 로그, 사용자 피드백 분류, 또는 유형에 따라 서로 다른 처리가 필요한 모든 항목의 배치 (batch) 처리.
예시 (Example): 지원 티켓 백로그 (backlog) 분류. 에이전트가 티켓을 읽고 각각을 버그 (bug), 기능 요청 (feature request), 또는 질문 (question)으로 분류합니다. 버그는 bug-investigator로, 기능 요청은 feature-analyst로, 질문은 support-responder로 보냅니다. 결과물은 카테고리별로 그룹화된 요약본입니다.
여기에서 트레이스 (trace)를 확인하세요.
팬아웃 및 합성 (Fanout and synthesize)
에이전트가 동일한 종류의 작업을 여러 항목에 대해 병렬로 배정(dispatch)한 다음, 그 결과들을 결합합니다.

사용 사례 (Use cases): 디렉토리 전체에 대한 코드 리뷰 (code review), 문서 배치 (batch) 분석, 로그 파일 처리, 여러 서비스에 걸쳐 동일한 점검 실행.
예시 (Example): 소스 트리 (source tree) 전체에 대한 파일별 보안 리뷰. 에이전트가 src/ 하위의 모든 TypeScript 파일을 찾아내고, 파일당 하나의 보안 리뷰어 (security-reviewer)를 병렬로 배정합니다. 그 후 결과들을 심각도 등급 (severity ratings)과 수정이 필요한 라인 정보가 포함된 단일 우선순위 보고서로 병합합니다.
여기에서 트레이스 (trace)를 확인하세요.
적대적 검증 (Adversarial verification)
2단계 패턴 (two-pass pattern)입니다. 첫 번째 단계에서 결과물 (findings)을 생성합니다. 두 번째 단계에서는 각 결과물을 독립적인 검증기 (verifiers)에게 보내며, 합의를 통해 살아남은 결과물만 유지합니다. 이는 속도보다 신뢰도가 더 중요할 때 오탐 (false positives)을 줄여줍니다.
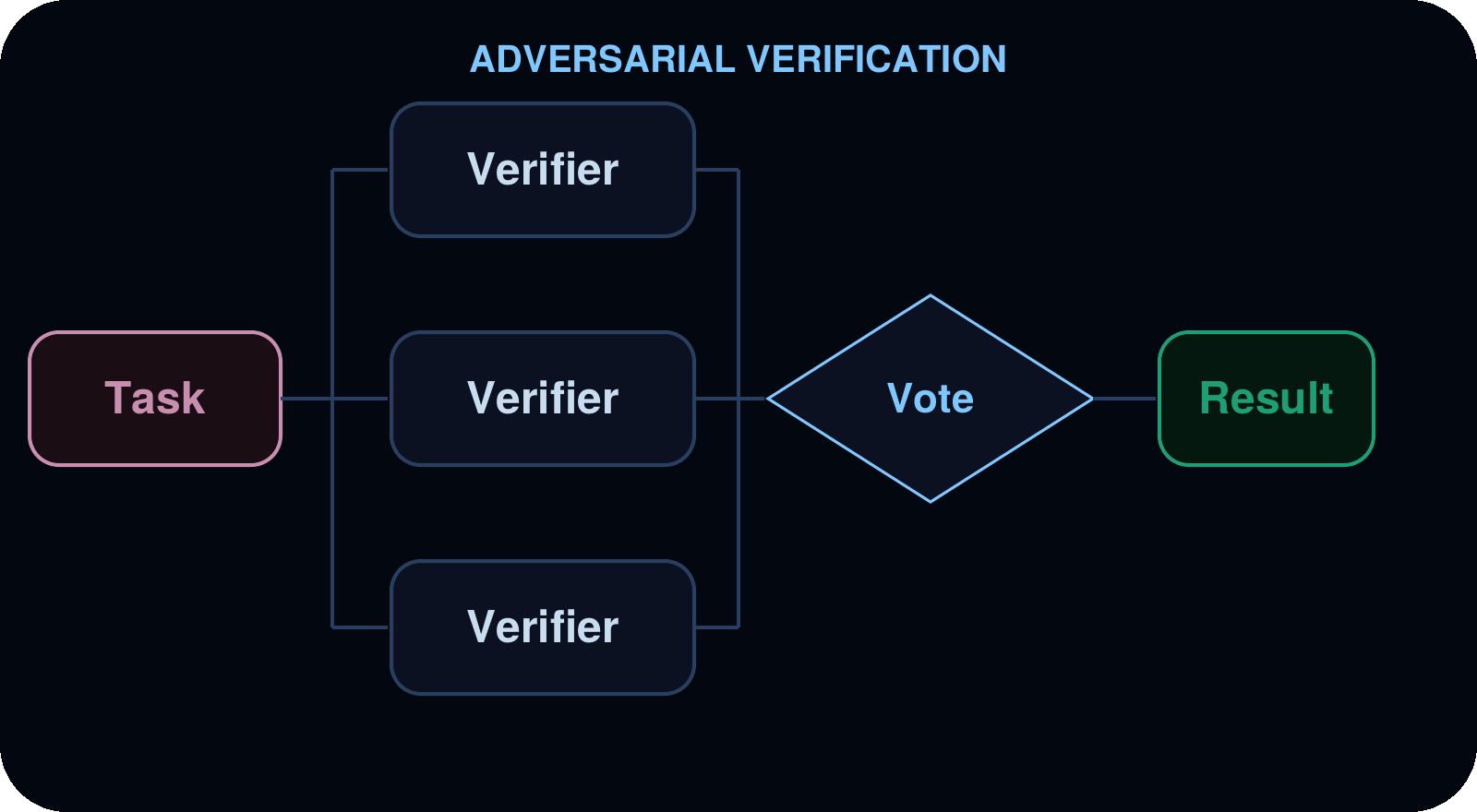
사용 사례 (Use cases): 오탐의 비용이 큰 보안 감사 (security audits), 컴플라이언스 (compliance) 체크, 결과물에 대해 높은 신뢰도가 필요한 모든 리뷰.
예시 (Example): 오탐이 허용되지 않는 보안 감사. 감사자 (auditor)가 잠재적 취약점을 찾기 위해 넓은 그물을 던지면, 각 결과물은 코드를 새로 읽는 독립적인 검증기에게 전달되어 CONFIRMED(확인됨) 또는 REFUTED(반박됨) 판정을 받습니다. 확인된 결과물만이 최종 보고서에 남게 됩니다.
여기에서 트레이스(trace)를 확인하세요.
생성 및 필터링 (Generate and filter)
여러 서브에이전트(subagents)가 동일한 문제에 대해 독립적인 솔루션을 생성합니다. 에이전트는 코드 내에서 결과물을 비교, 점수 산정 및 필터링하여 가장 우수한 결과만을 남깁니다.
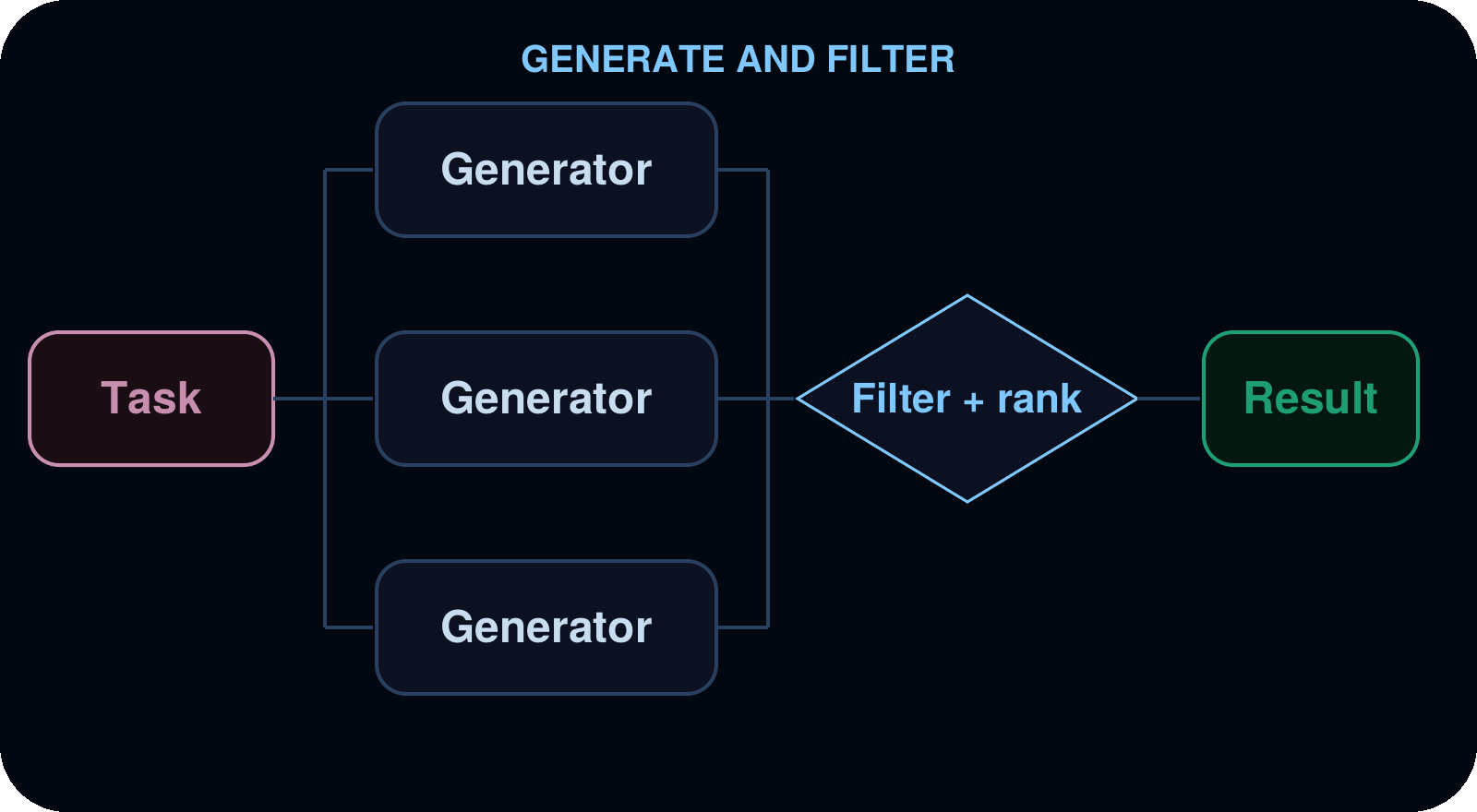
사용 사례 (Use cases): 아키텍처 제안, 리팩터링(refactoring) 전략, 콘텐츠 변형 등, 확정하기 전에 여러 옵션을 탐색함으로써 더 나은 결과를 도출할 수 있는 모든 작업.
예시: 순위가 매겨진 경쟁적인 속도 제한기(rate-limiter) 재설계. 에이전트는 architect를 사용하여 rate-limiter.ts에 대한 여러 개의 독립적인 재설계안을 생성하며, 각 안은 서로 덮어쓰지 않도록 별도의 파일에 작성됩니다. 그런 다음 버스트(burst) 상황에서의 정확성, 멀티 인스턴스(multi-instance) 지원 및 복잡성을 기준으로 점수를 매깁니다. 가장 강력한 안이 선정되며, 선정 이유에 대한 근거가 함께 제공됩니다.
여기에서 트레이스(trace)를 확인하세요.
토너먼트 (Tournament)
판단 서브에이전트(judge subagent)가 변형된 결과물들을 일대일로 비교하며, 승자가 탈락전 라운드를 거치며 진출합니다.
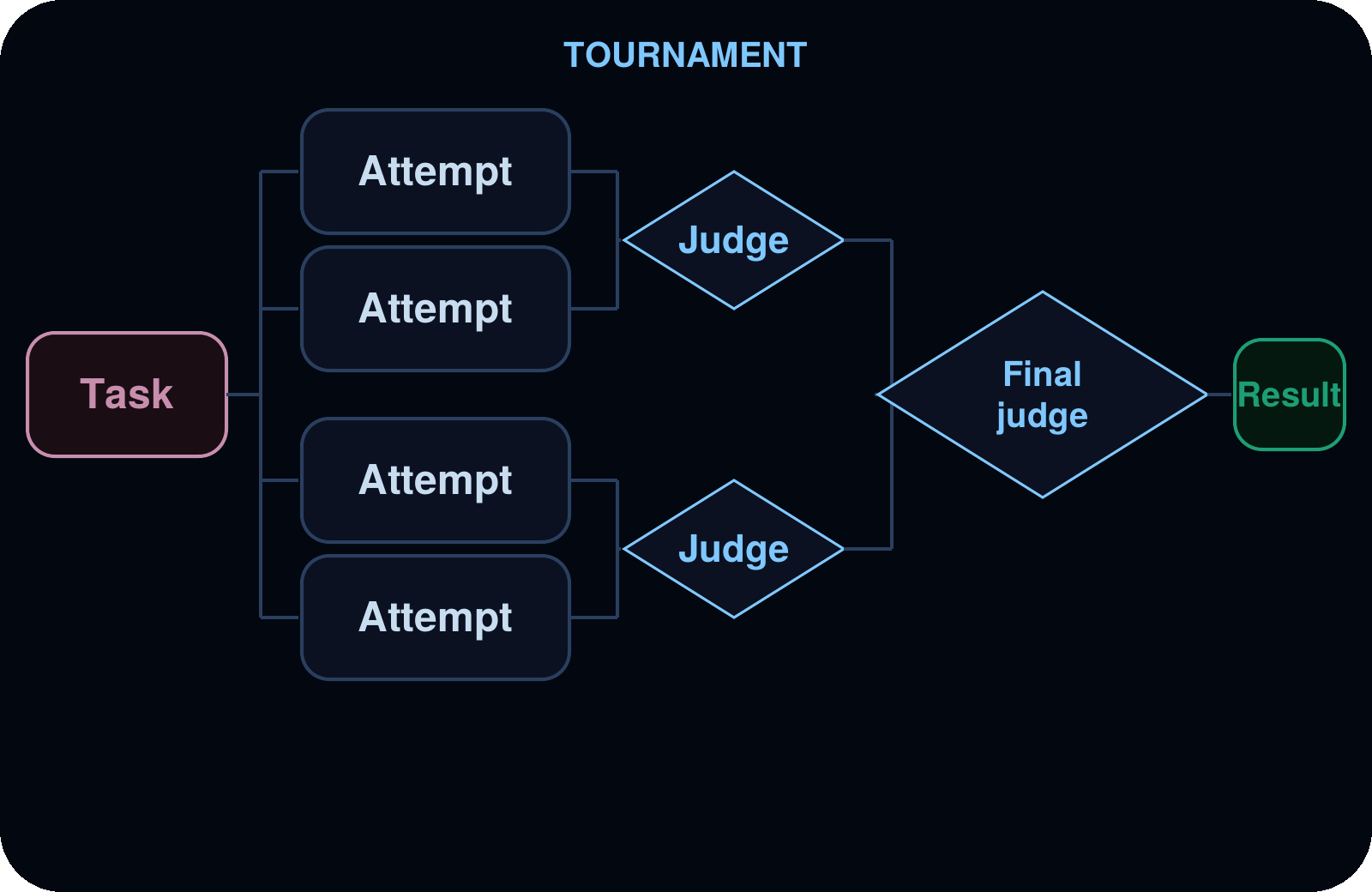
사용 사례 (Use cases): 주관적인 기준에 따른 최적화, 스타일 선택, 경쟁하는 구현 방식들 사이의 선택.
예시: 지저분한 createOrder 핸들러(handler)의 재작성(rewrites)에 대한 페어와이즈 브래킷(pairwise bracket, 쌍별 대진표). 여러 작성자가 각기 다른 우선순위를 가진 후보 재작성안을 생성하면, judge가 이들을 일대일로 비교하여 최종 챔피언이 나타날 때까지 라운드별로 승자를 진출시킵니다. 결과는 judge의 추론과 함께 반환됩니다.
여기에서 트레이스(trace)를 확인하세요.
완료될 때까지 루프 (Loop until done)
에이전트는 새로운 결과가 더 이상 나타나지 않을 때까지, 이미 발견한 내용과 중복을 제거하며 탐색 루프(discovery loop)를 실행합니다. 작업의 범위가 사전에 알려지지 않았을 때 유용합니다.
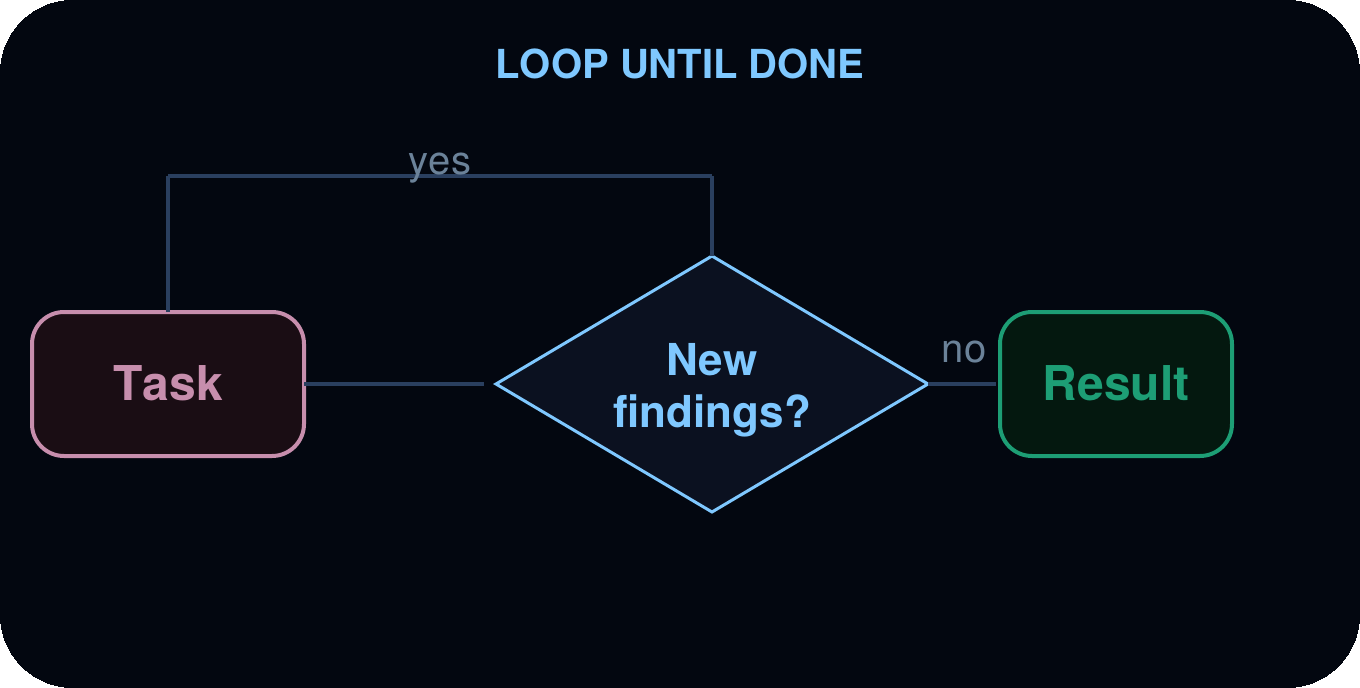
사용 사례 (Use cases): 철저한 탐색(exhaustive search), 데드 코드(dead code) 탐지, 의존성 감사(dependency audits), 고정된 결과 수보다는 완전성을 원하는 모든 스윕(sweep) 작업.
예시: 패스(pass) 기반의 보안 스윕(security sweep). 에이전트는 스캔 패스를 실행하여 코드에서 발견된 내용을 검사하고, 이전 패스에서 새로운 이슈가 발견된 경우에만 다음 패스를 시작합니다. 패스에서 새로운 내용이 발견되지 않으면 중단합니다. 에이전트는 통합된 조사 결과와 총 몇 번의 패스가 소요되었는지를 보고합니다.
여기에서 트레이스(trace)를 확인하세요.
결론
동적 서브에이전트 (Dynamic subagents)는 에이전트에게 더 많은 자율성 (autonomy)과 향상된 신뢰성 (reliability)을 부여하는 방법입니다. 코드가 커버리지 (coverage)와 중간 컨텍스트 (intermediate context)를 처리하며, 모델은 여전히 판단 중심의 핵심 작업을 수행합니다. 위에 제시된 패턴들은 시작점에 불과합니다. 실제 환경에서 에이전트들은 작업 요구 사항에 따라 이러한 패턴들을 조합하고 혼합하여 사용합니다.
이것은 재귀적 언어 모델 (Recursive Language Model) 개념의 가장 단순한 형태입니다. 코드를 작성하는 에이전트가 있고, 그 코드가 더 많은 에이전트를 파견하는 방식입니다. 이는 에이전트가 자기 자신을 재귀적으로 호출하는 것이며, 컨텍스트 윈도우 (context window)에 의해 제한되거나 고정된 워크플로 (workflow)에 갇히지 않습니다. 에이전트는 문제를 가능한 한 잘게 쪼갤 수 있으며, 조각들을 적합한 형태로 재조립할 수 있습니다. 위에서 강조된 오케스트레이션 (orchestration) 패턴들은 무엇이 가능한지에 대한 초기 엿보기일 뿐이며, 모델이 코드를 작성하는 능력이 향상됨에 따라 그 한계치는 계속해서 높아질 것입니다.
동적 서브에이전트는 Deep Agents가 이를 오늘날 여러분의 손에 전달하는 방식입니다. 에이전트에 코드 인터프리터 (code interpreter)를 추가하여 시작하거나, 동적 서브에이전트가 즉시 작동하는 dcode를 활용해 보세요.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기