Claude Code를 도메인 특화 코딩 에이전트로 전환하는 방법
요약
Claude Code를 도메인 특화 코딩 에이전트로 최적화하기 위한 실험 결과를 공유합니다. 단순한 문서 접근보다 구조화된 Claude.md 가이드와 MCP 도구를 결합했을 때 가장 뛰어난 성능을 보임을 입증했습니다.
핵심 포인트
- 가공되지 않은 문서 제공보다 구조화된 Claude.md 가이드가 성능 향상에 효과적임
- Claude.md의 압축된 정보와 MCP를 통한 상세 문서 접근을 결합할 때 최적의 결과 도출
- LangGraph 및 LangChain 개발 사례를 통한 다양한 설정 및 평가 프레임워크 제시
작성자: Aliyan Ishfaq
코딩 에이전트(Coding agents)는 LLM(대규모 언어 모델)이 집중적으로 학습한 대중적인 라이브러리를 사용하는 코드를 작성하는 데 매우 뛰어납니다. 하지만 커스텀 라이브러리, 라이브러리의 새로운 버전, 내부 API 또는 니치(niche) 프레임워크를 가리키게 하면 성능이 떨어집니다. 이는 도메인 특화 라이브러리나 엔터프라이즈 코드를 다루는 팀에게는 문제입니다.
라이브러리(LangGraph, LangChain) 개발자로서 우리는 이러한 코딩 에이전트가 LangGraph 및 LangChain 코드를 정말 잘 작성하도록 만드는 방법에 깊은 관심을 가지고 있습니다. 우리는 다양한 컨텍스트 엔지니어링(context engineering) 기술을 시도했습니다. 어떤 것은 효과가 있었고, 어떤 것은 그렇지 않았습니다. 이 블로그 포스트에서는 우리가 수행한 실험과 얻은 교훈을 공유하고자 합니다. 우리의 가장 큰 결론은 다음과 같습니다:
고품질의 압축된 정보와 필요에 따라 더 자세한 정보에 접근할 수 있는 도구를 결합했을 때 가장 좋은 결과가 나왔다
에이전트에게 가공되지 않은 문서(raw documentation)에 대한 접근 권한을 주는 것은 우리가 기대했던 만큼 성능을 향상시키지 못했습니다. 사실, 컨텍스트 윈도우(context window)가 더 빨리 채워졌습니다. Claude.md 형태의 간결하고 구조화된 가이드는 단순히 문서 도구를 연결하는 것보다 항상 더 나은 성능을 보였습니다. 가장 좋은 결과는 이 두 가지를 결합했을 때 나타났는데, 즉 에이전트가 기본 지식(Claude.md를 통해)을 가지고 있으면서도 더 많은 정보가 필요할 경우 문서의 특정 부분에 접근할 수 있는 경우였습니다.
이 포스트에서는 다음 내용을 공유합니다:
- 우리가 테스트한 다양한 Claude Code 설정
- 생성된 코드를 평가하기 위해 사용한 평가 프레임워크 (여러분의 라이브러리에 재사용할 수 있는 템플릿)
- 결과 및 주요 시사점
Claude Code 설정
우리는 일관성을 위해 Claude 4 Sonnet을 모델로 사용하여 네 가지 다른 구성을 테스트했습니다:
Claude Vanilla: 수정 사항이 없는 기본 상태의 Claude Code.
Claude + MCP: 문서 접근을 위해 우리의 MCPDoc 서버에 연결된 Claude Code.
Claude + Claude.md: LangGraph 특화 가이드가 포함된 상세한 Claude.md 파일이 있는 Claude Code.
Claude + MCP + Claude.md: 상세한 Claude.md와 MCPDoc 서버에 모두 접근할 수 있는 Claude.
문서화를 위한 MCP 도구
우리는 코딩 에이전트(coding agents)가 어떤 라이브러리의 문서라도 접근할 수 있도록 제공하고자 MCPDoc 서버를 구축했습니다. 이는 list_doc_sources와 fetch_docs라는 두 가지 도구를 노출하는 오픈 소스 MCP 서버입니다. 첫 번째 도구는 사용 가능한 llms.txt 파일의 URL을 공유하며, 두 번째 도구는 특정 llms.txt 파일을 읽습니다. 우리의 설정에서는 LangGraph 및 LangChain의 Python과 JavaScript 문서에 대한 접근 권한을 제공했습니다. MCP 설정(config)에 사용 중인 라이브러리의 llms.txt 파일 URL을 전달함으로써 여러분의 사용 사례에 맞춰 쉽게 조정할 수 있습니다.

Claude.md
Claude.md를 위해 우리는 LangGraph 라이브러리 가이드를 제작했습니다. 여기에는 파일을 생성하기 전 반드시 코드베이스를 검색해야 한다는 점, 적절한 내보내기(export) 패턴, 배포 모범 사례(best practices)와 같이 일반적인 LangGraph 프로젝트 구조 요구 사항에 대한 상세한 지침이 포함되었습니다. 또한 create_react_agent, 감독자 패턴(supervisor patterns), 동적 핸드오프(dynamic handoffs)를 위한 스웜 패턴(swarm patterns) 등 단일 및 멀티 에이전트 시스템(multi-agent systems) 구축에 필요한 기본 요소(primitives)에 대한 샘플 코드도 포함되었습니다. 스트리밍(streaming)이나 사용자 대면 에이전트를 위한 인간 참여형(human-in-the-loop) 방식처럼 LLM이 어려워하던 특정 구현 사항들에 대해서는 광범위한 가이드라인을 추가했습니다.

우리는 흔히 발생하는 실수(common pitfalls)와 안티 패턴(anti-patterns)에 대한 포괄적인 섹션을 포함하는 것이 특히 가치 있다는 것을 발견했습니다. 여기에는 잘못된 interrupt() 사용, 잘못된 상태 업데이트(state update) 패턴, 타입 가정 오류(type assumption errors), 그리고 지나치게 복잡한 구현과 같은 일반적인 실수들이 포함되었습니다. 이는 라이브러리 지원 중단(deprecated)이나 다른 프레임워크의 패턴과 혼동하여 LLM이 자주 범하는 실수들이었습니다.
또한 구조화된 출력 검증(structured output validation), 적절한 메시지 처리, 기타 프레임워크 통합 디버깅 패턴과 같은 LangGraph 전용 코딩 표준도 포함했습니다. Claude는 웹 도구에 접근할 수 있으므로, 추가 참조 및 탐색 가이드를 위해 각 섹션 끝에 특정 문서 URL을 추가했습니다.
이 파일이 llms.txt와 다른 점은
전자는 URL과 함께 페이지의 모든 콘텐츠를 담은 일반 텍스트 파일인 반면, 이 파일은 처음부터 시작할 때 가장 중요한 요약된 정보를 포함하고 있다는 점입니다. 결과에서 확인하겠지만, llms.txt가 단독으로 전달될 경우, 때로는 LLM에게 더 많은 문맥을 제공하면서도 어떻게 탐색하고 무엇이 중요한지 식별하는 방법에 대한 지침을 주지 않아 혼란을 줄 수 있으므로 가장 효과적이지는 않습니다.
다양한 작업에 걸쳐 우리의 Claude Code 설정이 어떻게 성능을 발휘했는지 살펴보기 전에, 작업 수행 능력과 코드 품질을 결정하기 위해 사용한 평가 프레임워크(evaluation framework)를 공유하고자 합니다.
평가 (Evaluations)
우리의 목표는 단순히 기능성뿐만 아니라 코드 품질에 무엇이 가장 크게 기여하는지를 측정하는 것이었습니다. Pass@k와 같은 대중적인 지표는 기능성은 포착하지만, 문맥에 따라 달라지는 베스트 프랙티스 (best practices)는 포착하지 못합니다.
우리는 기술적 요구 사항과 코드 품질, 설계 선택, 선호되는 방식의 준수와 같은 주관적인 측면을 모두 확인하는 작업별 평가 하네스 (evaluation harness)를 구축했습니다.
우리는 평가를 위해 세 가지 카테고리를 정의합니다:
스모크 테스트 (Smoke Tests)
이 테스트들은 기본적인 기능성을 검증합니다. 테스트를 통해 코드가 컴파일되는지, .invoke() 메서드를 노출하는지, 예상된 입력 상태를 처리하는지, 그리고 필수 상태 속성을 가진 AIMessage 객체와 같이 예상된 출력 구조를 반환하는지 확인합니다.
우리는 가중 합산 (weighted summation)을 사용하여 점수를 계산합니다:
Score = Σᵢ wᵢ × cᵢ
여기서 wi는 테스트 i의 가중치이며, ci는 테스트의 이진 결과 (binary result)입니다.
작업 요구 사항 테스트 (Task Requirement Tests)
이 테스트들은 작업별 기능성을 검증합니다. 테스트에는 배포 설정 파일의 유효성 검사, 웹 검색 또는 LLM 제공업체와 같은 외부 API에 대한 HTTP 요청 확인, 그리고 각 코딩 작업에 특화된 단위 테스트 (unit tests)가 포함됩니다. 점수 산정은 스모크 테스트와 마찬가지로 각 테스트 결과의 가중 합산을 통해 이루어집니다.
코드 품질 및 구현 평가 (Code Quality & Implementation Evaluation)
이 카테고리에서는 이진 테스트 (binary tests)가 놓칠 수 있는 부분을 포착하기 위해 LLM-as-a-Judge 방식을 사용합니다. 더 나은 접근 방식을 따르는 구현체는 단순히 컴파일되고 실행되는 구현체보다 더 높은 점수를 받아야 합니다. 코드 품질 (Code quality), 설계 선택 (design choices), 그리고 LangGraph 추상화 (abstractions)의 사용은 모두 미묘한 평가를 필요로 합니다.
우리는 각 작업에 대해 전문가가 작성한 코드를 검토하고 작업별 루브릭 (rubrics)을 구축했습니다. Temperature 0 설정의 Claude Sonnet 4 (claude-sonnet-4-20250514)를 사용하여, 전문가가 작성한 코드를 참조(reference)로 삼고 컴파일 및 런타임 오류를 기록하기 위한 인간의 주석 (human annotations)을 활용하여 생성된 코드를 이 루브릭에 따라 평가했습니다.
우리의 루브릭에는 두 가지 유형의 기준이 있었습니다:
**객관적 점검 (Objective Checks): **이는 코드에 대한 이진적 사실입니다 (예: 특정 노드의 존재 여부, 올바른 그래프 구조, 모듈 분리, 테스트 파일의 부재 등). LLM judge는 각 점검에 대해 불리언 (boolean) 응답을 반환했으며, 우리는 스모크 테스트 (smoke tests)와 마찬가지로 가중 합산 (weighted summation)을 사용하여 객관적 점검에 대한 점수를 산출했습니다.
**주관적 평가 (Subjective Assessment): **이는 전문가가 작성한 코드를 참조로 삼고, 컴파일 및 런타임 오류 로그를 통과시키기 위한 인간의 주석을 사용하여 코드를 질적으로 평가하는 것입니다. LLM judge는 문제를 식별하고 이를 두 가지 차원인 정답 위반 (correctness violations)과 품질 우려 사항 (quality concerns)에 따라 심각도 (critical, major, minor)별로 분류했습니다.
우리는 이를 위해 페널티 기반 점수 산정 (penalty-based scoring) 방식을 사용합니다:
Score = Scoreₘₐₓ - Σₛ (nₛ × pₛ)
여기서 Scoremax는 가능한 최대 점수이고, ns는 심각도 s에서의 위반 횟수이며, ps는 해당 심각도에 대한 페널티 가중치입니다.
객관적 결과와 주관적 결과를 모두 결합한 전체 점수는 다음과 같이 주어집니다:
Score = Σᵢ wᵢ × cᵢ + Σₛ (Scoreₘₐₓ,ₛ - Σₛ (nₛ × pₛ))
여기서 첫 번째 항은 객관적 점검을 나타내고, 두 번째 항은 모든 주관적 카테고리에 걸친 평가를 나타냅니다.
우리는 분산을 고려하여 각 Claude Code 설정을 작업당 세 번씩 실행했습니다. 일관성을 위해 모든 점수는 가능한 총점 대비 백분율로 보고되었으며, 이후 작업 전체에 대해 평균을 냈습니다.
LangSmith 플랫폼을 사용하여 코딩 에이전트 (coding agent) 설정을 비교함으로써, 여러분의 자체 라이브러리에 대해서도 이 접근 방식을 재현할 수 있습니다.
결과 (Results)
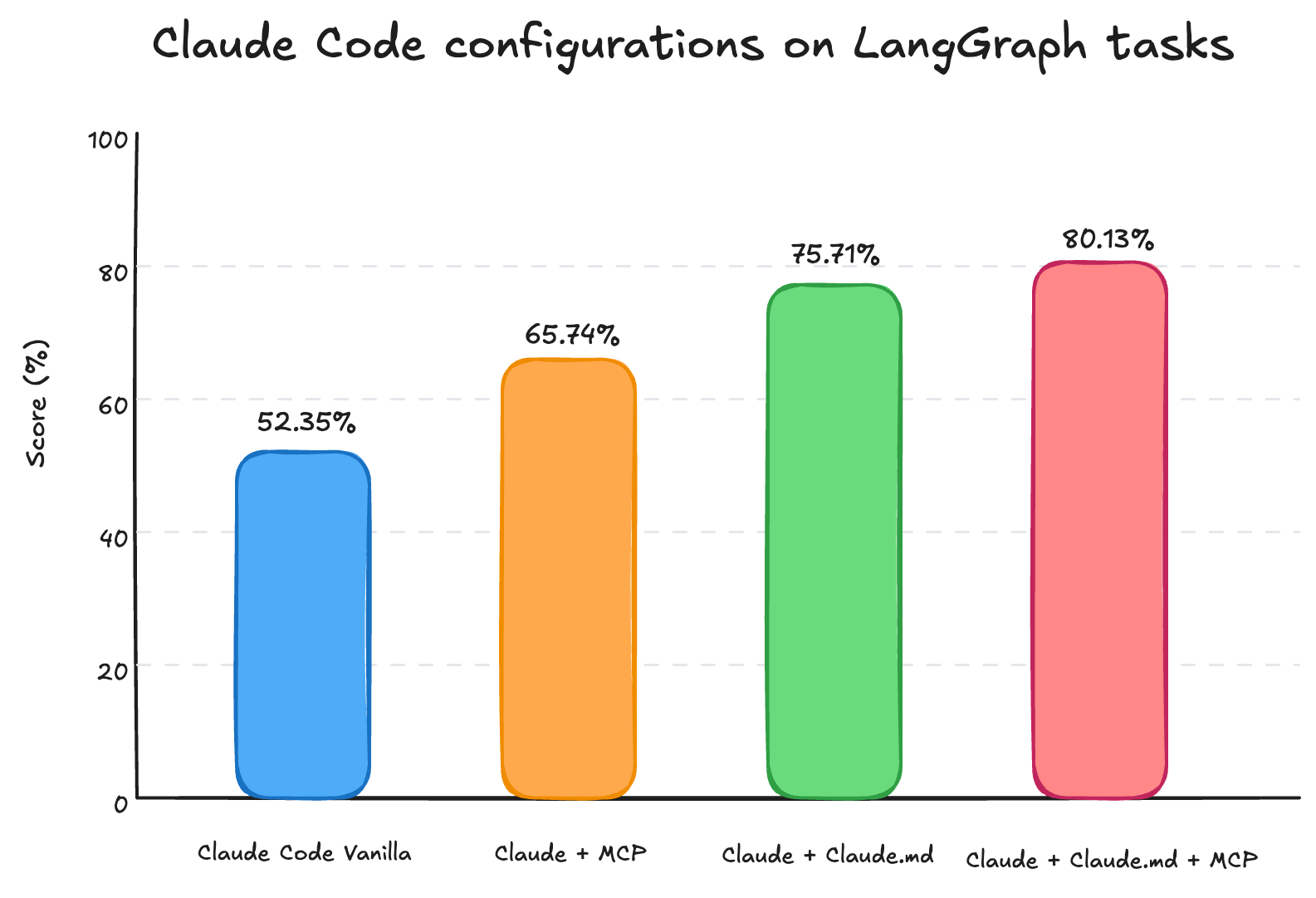
Claude Code 설정을 비교하기 위해 세 가지 서로 다른 LangGraph 작업에 걸쳐 점수를 평균 냈습니다. 아래 차트는 전체 점수를 보여줍니다:
저희에게 가장 흥미로운 발견은 Claude + Claude.md 조합이 Claude + MCP 조합보다 성능이 뛰어났다는 점입니다. 비록 Claude.md가 MCP 서버가 제공할 수 있는 기능의 일부만을 포함하고 있었음에도 말입니다. 트레이스 (Traces)를 통해 그 이유를 설명할 수 있었습니다. Claude는 저희가 예상했던 것만큼 MCP 도구 (tools)를 많이 호출하지 않았습니다. 작업 수행을 위해 두세 개의 연결된 페이지를 따라가야 하는 경우에도, 일반적으로 MCP를 한 번 호출한 뒤 메인 페이지에서 멈추는 경향을 보였습니다. 이 메인 페이지는 필요한 세부 정보가 아닌 표면적인 설명만을 제공했습니다.
반면, Claude + Claude.md + MCP 조합은 문서를 더 효과적으로 사용했습니다. 트레이스 분석 결과, 이 조합은 MCP 도구를 더 빈번하게 호출했으며 필요할 때는 웹 검색 도구 (web search tool)까지 트리거하는 것을 관찰했습니다. 이러한 동작은 각 섹션 끝에 추가 정보를 찾을 수 있는 참조 URL을 포함한 Claude.md 덕분에 가능했습니다.
이것이 MCP 도구 자체의 도움이 없었다는 뜻은 아닙니다. MCP는 주로 에이전트를 기본적인 구문 (syntax)과 개념에 접지 (grounding) 시킴으로써 점수를 약 10%포인트 향상시켰습니다. 하지만 작업 완료와 코드 품질 측면에서는 Claude.md가 더 중요했습니다. 가이드에는 피해야 할 함정과 따라야 할 원칙들이 포함되어 있었으며, 이는 Claude Code가 상위 수준의 설명에서 멈추지 않고 더 잘 사고하고 라이브러리의 다양한 부분을 탐색하도록 도왔습니다.
이러한 결과는 코딩 에이전트를 설정하려는 모든 이들에게 몇 가지 광범위한 교훈을 시사합니다.
핵심 요약 (Key Takeaways)
결과를 통해 몇 가지 시사점을 얻을 수 있습니다. 여러분의 자체 라이브러리를 위해 코딩 에이전트를 커스텀하는 것을 고려하고 있다면, 다음 내용이 유용할 수 있습니다:
**컨텍스트 과부하 (Context Overload): **대규모 llms.txt를 쏟아붓는 것...
문서에서 가져온 파일들이 컨텍스트 윈도우 (Context Window)를 가득 채울 수 있습니다. 이는 성능 저하와 비용 상승으로 이어질 수 있습니다. 저희의 MCP 서버는 페이지 콘텐츠를 통째로 가져오는 단순한 (naive) 구현 방식을 사용하고 있습니다. 단 한 번의 호출만으로도 Claude Code가 컨텍스트 윈도우가 가득 차고 있다는 경고를 보냈습니다. 만약 특정 문서를 검색하기 위한 도구가 필요할 정도로 문서 양이 방대하다면, 관련 스니펫 (snippets)만 추출하는 더 스마트한 검색 도구를 구축할 가치가 있습니다.
**Claude.md가 가장 높은 효율을 보입니다: **MCP 서버나 특정 도구를 설정하는 것보다 구축하기 쉽고 실행 비용도 저렴합니다. 작업 #2에서 Claude + Claude.md 조합은 Claude MCP 방식이나 Claude + Claude.md + MCP 조합보다 약 2.5배 저렴했습니다. 이는 Claude MCP보다 저렴하면서도 성능은 더 뛰어납니다. Claude Code를 커스텀하는 것을 고민할 때 아주 좋은 시작점이며, 일부 유스케이스 (use cases)에서는 이것만으로도 충분할 수 있습니다.
좋은 지침 (Instructions)을 작성하세요. Claude.md (또는 Agents.md)에는 라이브러리의 핵심 개념, 고유 기능, 그리고 공통 프리미티브 (primitives)를 강조해야 합니다. 실패한 실행 사례를 수동으로 검토하여 반복되는 함정을 찾아내고 이에 대한 가이드를 추가하세요. 저희의 경우, 에이전트가 asyncio 통합에서 자주 실패했던 Streamlit 환경에서의 LangGraph 비동기 작업 (async tasks)을 다루는 것이 그 작업이었습니다. 또한 개발 서버를 구동하기 위한 디버깅 단계를 추가하여, 임포트 (import) 에러를 해결하고 Claude Code가 서버에 요청을 보내 출력을 검증할 수 있도록 했습니다. 인기 있는 코드 생성 (code-gen) 도구들은 종종 긴 시스템 프롬프트 (system prompts, 7~10k 토큰)를 사용합니다. 지침을 작성하는 데 공을 들이는 것은 충분한 보상을 가져다줍니다.
Claude + Claude.md + MCP 조합이 승리합니다: Claude.md가 토큰당 가장 높은 효율을 제공하지만, 가장 강력한 결과는 문서를 상세히 읽을 수 있게 해주는 MCP 서버와 결합했을 때 나타났습니다. 가이드는 개념에 대한 방향을 제시하고, 문서는 심층적인 탐색을 도왔습니다. 이들이 결합되면 도메인 특화 라이브러리에서 최상의 결과를 만들어낼 수 있습니다.
부록 (Appendix)에는 작업별 성능을 자세히 알고 싶은 독자들을 위해 작업별 결과와 카테고리 수준의 그래프를 포함했습니다.
부록 (Appendix)
작업 #1: Text-to-SQL 에이전트 (Text-to-SQL Agent)
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기