
AWS, 에이전틱 AI(Agentic AI)를 위해 Graviton5 최적화 및 가성비 대폭 향상
요약
AWS가 에이전틱 AI 워크로드에 최적화된 Graviton5 CPU를 탑재한 M9g 및 M9gd 인스턴스를 출시했습니다. Graviton5는 4개의 칩렛 구조와 3nm 공정을 채택하여 높은 수율과 메모리 확장성을 확보했습니다.
핵심 포인트
- 4개의 칩렛 구조를 통해 제조 수율을 높이고 비용 효율성 극대화
- 3nm 공정 전환으로 트랜지스터 밀도 및 전력 효율 향상
- CXL 3.0 및 PCIe 6.0 지원으로 대규모 메모리 확장성 제공
- 에이전틱 AI 및 인메모리 데이터베이스 워크로드 최적화

AWS, 에이전틱 AI(Agentic AI)를 위해 Graviton5 최적화 및 가성비 대폭 향상
지난 12월, Amazon Web Services의 Annapurna Labs 칩 부문은 Graviton5 Arm 서버 CPU의 프리뷰를 선보였으며, 우리는 이 칩이 어떤 모습일지에 대한 몇 가지 힌트를 얻었습니다. 이번 주, Graviton5가 새로운 M9g 및 M9gd 인스턴스에 탑재되어 출하되기 시작했으며, AWS는 Graviton5에 대한 더 자세한 세부 정보를 제공하며 공백을 채워주었습니다.
우선, 7개월 전 re:Invent 컨퍼런스 기간 동안 AWS가 보여주었던 블록 다이어그램(block diagram)은 정확하지 않았습니다. 해당 다이어그램은 96쌍의 “Poseidon” Neoverse V3 코어를 가진 모놀리식 다이(monolithic die)를 보여주었습니다. 결과적으로 확인된 바로는, Graviton5 칩은 각각 48개의 V3 코어와 관련 메모리 및 I/O 컨트롤러를 갖춘 4개의 CPU 블록으로 구성되어 있습니다. 이는 AWS가 Arm Holdings가 제작하여 자체 AGI CPU에 사용 중인 Poseidon Compute Subsystem 칩 블록을 가져와, 코어 수를 64개에서 48개로 줄이고, Arm의 다이 간 상호 연결(die-to-die interconnect) 기술을 사용하여 192개의 V3 코어, 12개의 DDR5 메모리 컨트롤러, 그리고 96개의 레인을 보유하고 CXL 3.0 메모리 확장 프로토콜을 지원하는 것으로 보이는 8개의 PCI-Express 6.0 컨트롤러를 갖춘 Graviton5 소켓을 만든 것으로 보입니다.
이 마지막 부분은 인메모리 데이터베이스(in-memory databases)나 AWS가 Graviton5 소켓에 경제적으로 배치할 수 있는 것보다 더 많은 메모리 용량이 필요한 워크로드에 중요할 것입니다. (DIMM의 용량을 늘릴수록 더 두꺼운 메모리 스틱의 비용은 점점 더 많이 발생합니다. 이는 선형적이 아니라 기하급수적으로 증가합니다. 따라서 용량 요구 사항을 충족하는 가장 얇은 메모리를 선택하고, 해당 용량 대비 최대 메모리 대역폭을 확보하기 위해 항상 모든 메모리 슬롯을 채우게 됩니다.)
여기서 4개의 개별 Graviton5 칩렛(chiplets)을 확인할 수 있습니다:

4개의 칩렛(chiplets)을 하나의 가상 프로세서로 연결하는 4개의 D2D 상호 연결(interconnects)이 있으며, 이 링크들은 420 GB/sec의 속도로 작동합니다. 이러한 상호 연결은 많은 에너지를 소비하지만, 4개의 칩렛을 사용함으로써 각 칩렛의 비용을 낮출 수 있습니다. 이는 Taiwan Semiconductor Manufacturing Co.의 레티클 한계(reticle limits)에 다다르는 단일 칩(monolithic) 설계보다 더 작은 칩의 수율(yield)이 훨씬 높기 때문입니다. 이러한 칩렛당 낮은 비용은 Graviton4 칩에 사용된 4나노미터(nanometer) 공정에서, 훨씬 더 비싸지만 트랜지스터 밀도가 높고 전력 효율이 더 좋은 3나노미터 공정으로 전환됨으로써 상쇄됩니다.
저는 96개의 코어를 가진 Graviton4가 730억 개의 트랜지스터를 가졌던 것으로 추정하며, AWS는 2023년 11월 Graviton4가 공개되었을 당시 2년 뒤의 미래였던 Graviton5와 유사한 싱글 노드 성능을 얻기 위해 처음으로 2소켓 NUMA 머신을 만들었습니다.
Graviton4는 기본적으로 Graviton3와 동일한 아키텍처를 가졌으며, 중앙의 단일 칩(monolithic) 코어 칩렛을 별도의 메모리 및 I/O 컨트롤러 칩들이 둘러싸고 연결된 구조였습니다. Graviton3는 64개의 “Zeus” V1 코어를 가졌고, Graviton4는 96개의 “Demeter” V2 코어를 가졌습니다.
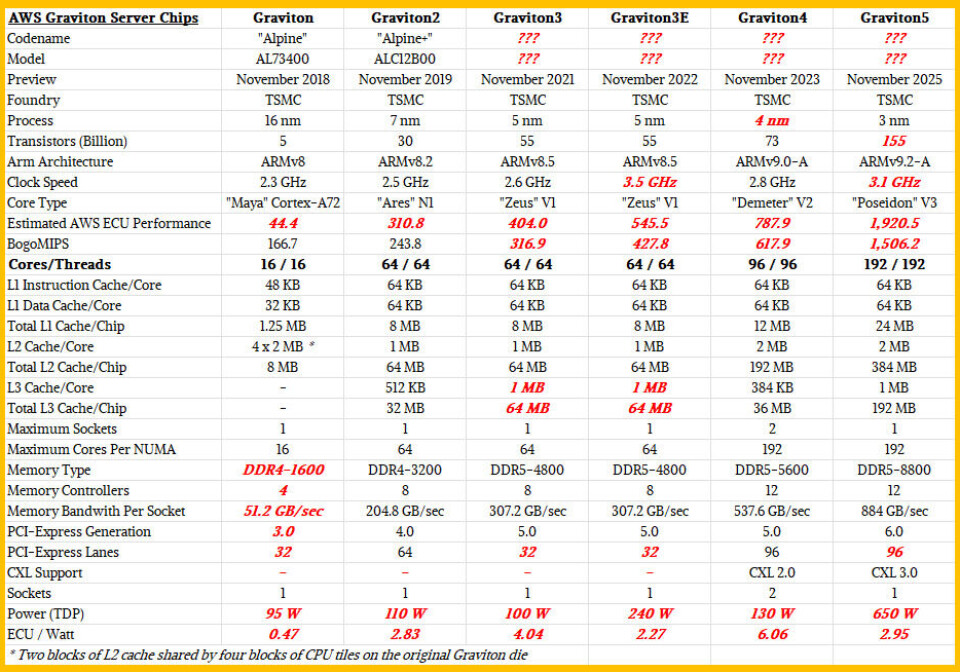
위 표에서 볼 수 있듯이, L1 캐시(L1 cache)와 L2 캐시(L2 cache)는 코어 수에 따라 선형적으로 증가했지만, AWS는 L3 캐시(L3 cache)를 코어 수보다 더 빠르게 증가시켰습니다. Graviton5는 코어당 2 MB의 L2 캐시를 가져 192개 코어 전체에 걸쳐 총 384 MB의 L2 캐시를 보유하지만, 코어당 L3 캐시는 384 MB로 Graviton4의 두 배에 달합니다.
증가된 L3 캐시, V3 코어의 더 빠른 클럭 속도와 DDR5 메모리, 그리고 Graviton5 소켓 내 4개의 칩렛(chiplet) 사이의 D2d 인터커넥트(interconnect)를 고려할 때, Graviton5의 소비 전력(wattage)은 급격히 증가합니다. 제 생각에 약 650와트(W) 정도 나가는 것 같은데, 이는 와트당 성능(performance per watt)이 Graviton4의 절반 수준임을 의미합니다. 하지만 Graviton5를 사용하면 소켓당 2.4배 더 높은 성능을 얻을 수 있으며, NUMA 공유 메모리 구성(shared memory configuration)으로 칩 2개를 사용하는 Graviton4 노드와 비교하더라도, 단일 Graviton5가 단 하나의 칩만으로 25% 더 높은 원시 처리량(raw throughput)을 제공합니다.
이는 데이터베이스와 에이전틱 AI(agentic AI)를 지원하기 위해 반응성이 뛰어난 시스템이 필요하다는 점을 고려할 때 모두 타당한 트레이드오프(tradeoff)입니다. 이러한 시스템들은 낮은 발열보다 낮은 지연 시간(low latency)을 더 필요로 하기 때문입니다.
로컬 플래시 스토리지(local flash storage)가 없는 Graviton5 기반의 M9g 인스턴스가, 마찬가지로 노드 내에 로컬 플래시가 없는 Graviton4 기반의 이전 세대인 R8g 및 X8g와 비교했을 때의 성능은 다음과 같습니다:

그리고 1년 기준 온디맨드(on demand) 가격 대비 인스턴스 가격과 성능을 비교하면 다음과 같습니다:
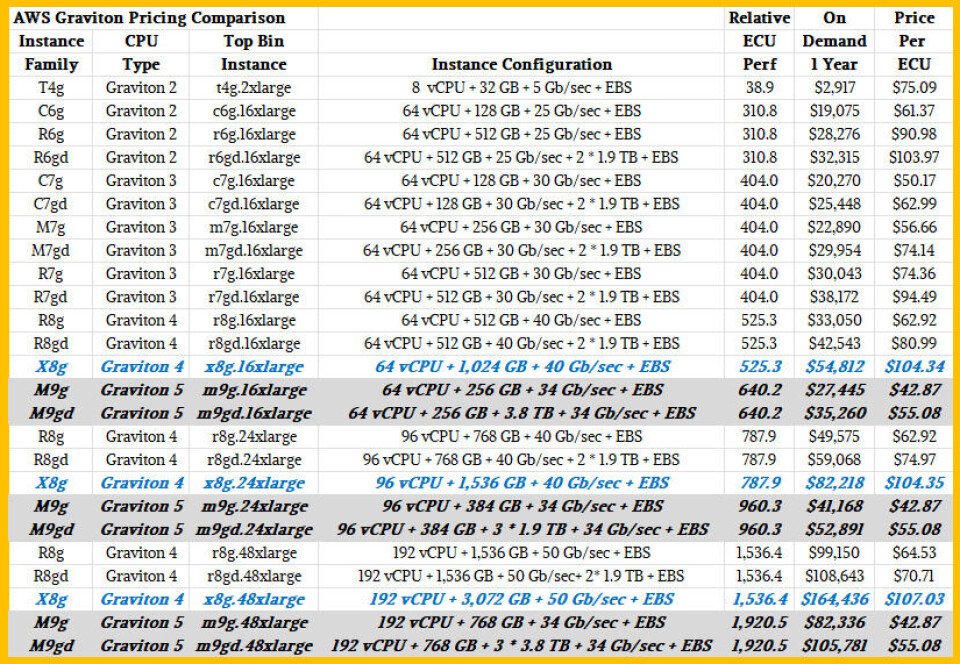
M9g 및 M9gd 인스턴스(후자는 로컬 플래시 추가)와 X8g 인스턴스의 인스턴스 절약 플랜(instance savings plan) 가격은 어떤 이유에서인지 공개적으로 발표되지 않았습니다. 하지만 컴퓨트 인스턴스(compute instance) 가격이 있으며, 이는 가격 인하 폭은 다소 덜 공격적이지만 데이터 센터 내 및 리전(region) 간의 다른 인스턴스로 전환하는 데 있어 더 유연합니다. 온디맨드 가격은 위에 표시되어 있습니다.
즉각적으로 눈에 띄는 점은 AWS가 M9g 인스턴스에 대해 X8g 인스턴스의 약 절반 가격을 책정하고 있다는 것이며, 이는 M9g 인스턴스의 메모리 용량이 4분의 1 또는 절반 수준이기 때문에 타당한 결과입니다. (이는 각 패밀리 내의 인스턴스마다 다릅니다.) 이것이 DRAM 및 플래시 메모리 부족(crunch)의 즉각적인 영향입니다. AWS는 로컬 스토리지를 갖춘 변형 모델에서도 플래시 용량을 덜 관대하게 제공할 수밖에 없습니다. 컴퓨트는 저렴하지만, 메모리는 그렇지 않습니다.
다음은 초기 Graviton2 및 Graviton3 인스턴스의 가성비(price/performance) 표입니다. 이들은 강력한 성능을 자랑하는 Graviton4 및 Graviton5 인스턴스와 비교하면 그리 인상적이지 않았습니다. M9g 인스턴스는 동일한 vCPU 수를 가진 가장 유사한 R8g 인스턴스보다 31.9%에서 33.6% 더 높은 가성비를 제공하며, 로컬 플래시를 갖춘 M9gd 인스턴스는 R8gd 인스턴스보다 22.1%에서 32% 더 나은 가성비를 제공합니다. 고용량 메모리를 갖춘 X8g 인스턴스는 매우 비쌉니다. 이 인스턴스를 선택하려면 정말로 그만큼 큰 메모리 풋프린트(memory footprint)가 필요해야 합니다.
여러분은 Graviton5 기반의 새로운 M9g 및 M9gd 인스턴스가 Graviton4 CPU를 사용하는 이전 세대인 R8g 및 R8gd에 비해 메모리가 다소 부족하다고 생각할 수도 있습니다. Graviton5 인스턴스의 용량은 Graviton4 인스턴스의 4분의 1에서 절반 수준이지만, 대역폭 민감형 워크로드(bandwidth sensitive workloads)의 경우 이 용량 차이가 그리 중요하지 않을 수 있습니다. 저희는 머지않은 미래에 메모리를 더 추가한 더 큰 메모리 용량의 X9g 인스턴스가 출시될 것이라고 강력하게 추측하지만, 최근 DRAM 비용을 고려할 때 해당 추가 메모리에 대해 상당한 프리미엄을 지불해야 할 것으로 예상합니다. 더욱이, AWS는 DDR5 폼 팩터에서 사용 가능한 가장 빠른 DRAM인 8.8 GHz 속도를 사용하고 있습니다. 이러한 Graviton5 인스턴스는 용량에서 부족할 수 있는 부분을 대역폭으로 보완합니다.
이러한 추가 메모리 비용의 일부는 CXL 3.0 메모리 확장기(memory extenders)를 통해 완화될 수 있으며, AWS가 이 기능을 제공하기 위해 Graviton5 랙에 공유 메모리 어플라이언스(shared memory appliance)를 구축했을 가능성도 충분합니다. PCI-Express 6.0 슬롯을 갖춘 노드에서는 CXL 3.0 메모리 확장기가 사용되지 않을 것이라고 생각하지만, 이는 단지 DRAM을 확장하고 공유하기 위한 랙 스케일 메모리 어플라이언스(rackscale memory appliance)보다 덜 흥미로운 주제이기 때문입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기