
AMD, 플래시 확장 메모리로 서버 DRAM 용량 확대
요약
생성형 AI 수요 폭증으로 인한 DRAM 가격 상승과 공급 부족 문제를 해결하기 위해 AMD가 플래시 메모리를 활용한 서버 메모리 확장 방안을 모색하고 있습니다. HBM 생산 확대가 일반 DRAM 공급 감소로 이어지는 상황에서, 플래시를 통한 메모리 용량 확장은 데이터센터 비용 절감의 핵심 과제로 부상했습니다.
핵심 포인트
- AI 수요로 인한 DRAM 가격 급등 및 서버 비용 비중 증가
- HBM 생산 확대에 따른 일반 DRAM 및 플래시 공급 부족 심화
- AMD, 플래시 메모리를 활용한 서버 DRAM 용량 확장 전략 추진
- DRAM과 플래시 사이의 성능과 비용을 절충하는 기술적 필요성

AMD, 플래시 확장 메모리로 서버 DRAM 용량 확대
데이터센터에는 위기가 고조되고 있으며, 그 중심에는 DRAM 메인 메모리의 희소성과 터무니없이 높은 가격이 있습니다. 생성형 AI (GenAI) 붐으로 인해 하이퍼스케일러 (hyperscalers), 클라우드 구축업체, AI 모델 구축업체, 그리고 네오클라우드 (neoclouds) 기업들이 Micron Technology, Samsung, SK Hynix와 같은 메모리 파운드리에서 생산되는 한정된 용량을 독점하고 있으며, 이러한 수요 충격은 전례 없는 가격 상승을 초래하고 있습니다.
상황이 얼마나 심각할까요? 부품 가격을 추적하는 Counterpoint Research에 따르면, 64 GB DIMM 메모리 가격은 2025년 3분기에서 2026년 1분기 사이에 3.5배 상승했으며, 2026년 3분기까지는 5배까지 상승할 것으로 보입니다. 그리고 제가 여기서 보고했던 Micron의 가장 최근 재무 자료에 따르면, 2028년까지 수요 충격이 끝날 기미가 보이지 않으며, 이는 가격이 계속해서 높아질 것임을 의미합니다.
현재 상황을 보면, DRAM 메인 메모리는 2023년에 서버 비용의 약 50%를 차지했으며 당시 CPU는 자재 명세서 (BOM)의 약 4분의 1을 차지하고 나머지 절반은 기타 주변 장치와 플래시 및 디스크 스토리지로 구성되었습니다. 그러나 2026년 중반 현재 DRAM은 서버 비용의 60%에서 90% 사이를 차지하고 있으며, 평균적으로 약 75%에 달합니다. CPU 가격이 저렴해진 것은 아니지만, 메모리 가격이 치솟고 있기 때문에 증가하는 CPU 가격조차 그에 비하면 작아 보일 정도입니다.
무언가 변화가 필요하며, 확실히 할 수 있는 한 가지는 메인 메모리를 더 효율적으로 사용하고 플래시 (flash)를 통해 확장하는 것입니다. 이는 플래시 업계 사람들에게 10년 넘게 일종의 성배 (Holy Grail)와 같았으며, Intel과 Micron이 2015년 7월 대대적으로 출시했던 3D XPoint 스토리지의 핵심 목적이기도 했습니다.
3D XPoint의 약속은 DRAM과 플래시 (flash) 사이의 성능을 가지면서, 메인 메모리 (main memory)처럼 바이트 주소 지정 (byte addressable)이 가능하고, 비용은 플래시와 유사한 무언가를 갖는 것이었습니다. 하지만 Intel이 제조와 기술 측면 모두에서 3D XPoint를 충분히 빠르게 확장하지 못했기 때문에, 결국 DRAM만큼이나 비용이 많이 들고 플래시보다는 고작 몇 배 정도만 더 빠른 수준에 머물게 되었습니다. 만약 Intel이 3D XPoint를 자사의 Xeon 서버 프로세서 전용으로만 유지하기로 결정하지 않았더라면, 이는 주류가 되어 현재의 메모리 위기를 해결하는 데 도움을 주었을지도 모릅니다. 하지만 안타깝게도, Intel은 판단력을 조금 잃고 3D XPoint를 폐기했으며, 전형적인 "집을 따뜻하게 유지하기 위해 가구를 태우는" 식의 전략을 통해 플래시 사업부를 SK Hynix에 매각했습니다. 만약 Intel이 여전히 플래시 사업을 하고 있었다면 지금쯤 거두었을 이익을 상상해 보십시오...
그리고 이제, 3대 메모리 제조사들은 DRAM 생산량의 점점 더 많은 부분을 고가의 HBM 적층 메모리 (HBM stacked memory)에 할당하고 있으며, 이는 서버 DIMM 모듈에 사용되는 일반 DRAM 칩의 감소로 이어지고 있습니다. 또한 그들은 DRAM 생산을 늘리기 위해 플래시 생산량도 줄이고 있습니다. DRAM과 플래시 생산은 연간 약 20%에서 25% 정도 증가할 것이지만, 수요는 그보다 훨씬 더 높습니다. 따라서 3대 기업(Big Three)이 가장 높은 입찰자에게 용량을 판매하며 막대한 부를 쌓는 동안, DRAM과 플래시 가격은 계속해서 치솟고 있습니다.
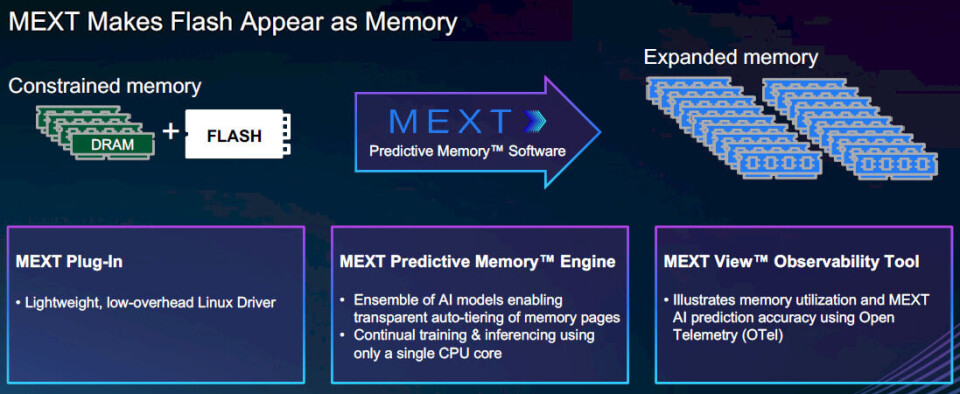
이것이 바로 AMD가 메모리 확장 (memory extension)이라는 개념을 연상시키기 위해 이름 지어진 MEXT라는 반짝이는 신생 스타트업을 인수하기 위해 미공개 금액을 지불한 이유입니다. MEXT 팀은 DRAM 메인 메모리 (DRAM main memory)를 플래시 스토리지 (flash storage)로 투명하고 보이지 않게 확장하는 방법을 고안해 냈습니다.
사람들은 Fusion-io 시절부터 이를 시도해 왔습니다. 2023년에 설립되어 올해 4월 초에야 스텔스 모드(stealth mode)에서 벗어난, 과거 독립 기업이었던 MEXT의 공동 창립자이자 최고 경영자(CEO)인 Gary Smerdon은 당시 Fusion-io의 최고 전략 및 제품 책임자(CSPO)였기에 이 사실을 누구보다 잘 알고 있습니다. (Fusion-io는 서버용 플래시 스토리지(flash storage)를 최초로 대규모 상용화한 기업으로, 10년도 더 전에 Apple과 Meta Platforms를 주요 고객사로 두고 있었습니다.)
Fusion-io에서 근무하기 전 6년 동안, Smerdon은 LSI Logic에서 솔리드 스테이트 메모리(solid state memory) 부문을 이끌었습니다. 보다 최근에 Smerdon은 TidalScale의 공동 창립자이자 최고 경영자(CEO)를 역임했습니다. TidalScale은 기업들이 더 작은 물리적 NUMA 서버들을 활용해 대규모 가상 NUMA 서버를 구축할 수 있게 해주는 HyperKernel 하이퍼바이저(hypervisor)를 개발했습니다. TidalScale은 여러 차례의 라운드를 통해 7,030만 달러를 유치했으며, 2022년 12월 Hewlett Packard Enterprise에 인수되었습니다. (HPE가 그 이후 HyperKernel을 어떻게 활용하고 있는지는 알 수 없습니다.)
인터넷상에는 MEXT가 240만 달러의 시드 펀딩(seed funding)을 유치했다는 이야기가 돌고 있지만, 저희는 그보다 더 많은 금액을 유치했을 것으로 추측합니다. Clear, DN Capital, Uncorrelated, Raptor, 그리고 FJ Labs가 모두 시드 자금 공급자였습니다.
예상할 수 있듯이 MEXT의 직원 39명 중 다수는 TidalScale 출신이지만, Smerdon은 상위 직급에 메모리 관리 (Memory Management) 및 가상화 (Virtualization) 분야의 외부 전문가들을 영입했습니다. David Reed는 공동 창립자이자 TidalScale의 수석 과학자였으며, 아주 오래전 Lotus Development의 수석 과학자이기도 했습니다. 기억하시나요? 최근 Reed는 HPE의 Fellow이자 SAP의 부사장직을 역임했으며, 인터넷 스택 (Internet Stack)의 일부를 구축하는 데 중추적인 역할을 했던 MIT의 컴퓨터 과학 교수이기도 합니다. VMware에서 ESX 하이퍼바이저 (Hypervisor)를 위한 프로세서 스케줄링 (Processor Scheduling), 메모리 관리 (Memory Management), NUMA 스케줄링 (NUMA Scheduling)을 담당했던 수석 엔지니어이자 VMware의 분산 리소스 스케줄러 (Distributed Resource Scheduler, DRS) 설계자였던 Carl Waldspurger가 MEXT의 수석 과학자로 발탁되었습니다. 중요한 점은, DRS가 가상 머신 (Virtual Machines)의 라이브 마이그레이션 (Live Migration)을 제어한다는 것인데, 이는 시스템 간에 메모리 상태 (Memory State)를 이동하는 것이 핵심입니다.
이들 MEXT의 세 명의 핵심 경영진은 1980년대 후반, 우리 PC에서 사용되고 LAN 서버에 막 도입되기 시작했던 Intel 80286 CPU가 당시 X86 아키텍처의 640 KB 메인 메모리 장벽에 부딪혔을 때 우리와 함께 있었습니다. 우리는 DOS(그리고 따라서 Windows 하위 계층)에서 기기 내 메모리를 최대 1 MB까지 활용하기 위해 HIMEM.SYS 확장 메모리 드라이버 (Extended Memory Drivers)를 가지고 씨름하곤 했습니다. 80386은 확장 메모리 (Extended Memory)가 내장되어 있었고, 32비트 프로세싱 (32-bit Processing)과 함께 우리를 4 MB의 메인 메모리로 해방시켜 주었으며, 세상은 바뀌었습니다.
따라서 메모리를 확장한다는 것은 물론 새로운 아이디어는 아니지만, 현재 DRAM 메모리가 매우 비싸다는 점을 고려하면 시의적절합니다. 그리고 플래시 (Flash)의 가격도 거의 비슷한 속도로 상승하고 있긴 하지만, 여전히 DRAM보다 50배 저렴하며 전력 소비량 또한 30배 더 낮습니다. 하지만 플래시는 DRAM보다 500배 더 느립니다. 따라서 플래시를 메모리 확장 도구로 사용하려면 영리한 방법이 필요합니다.
“우리는 이 문제들을 해결할 수만 있다면 모든 것을 바꿀 수 있는 세 가지 문제점을 찾아냈습니다,”라고 Smerdon은 The Next Platform에 전했습니다. “첫째, DRAM 활용도 (DRAM utilization)를 높여야 합니다. 이는 매우 당연한 일입니다. CXL을 통해 풀링 (pooling)을 함으로써 DRAM 활용도를 높이려는 시도는 누구나 하고 있는 일이죠. 하지만 이를 수행할 수 있는 방법은 아주 많습니다. 두 번째 문제는 메모리 확장 (memory extension)이 작동하기 위해 하드웨어나 소프트웨어의 변경이 필요 없어야 한다는 점입니다. 저는 메인보드에 이더넷 (Ethernet)을 탑재하거나 AMD와 LSI에서 근무하며 빠르게 성장하는 제품들을 경험해 왔는데, 그 제품들은 모두 소프트웨어 변경이 필요 없었습니다. 이상적인 세상에서 소프트웨어 기업이라면 하드웨어 변경 역시 원하지 않을 것입니다. 하지만 메모리 문제에 집중하는 그 누구도 이를 핵심 원칙의 일부로 삼지는 않았습니다. 그리고 세 번째 문제는 플래시 (flash)를 메모리 계층 (memory tier)으로 가져오는 것이었습니다. 우리가 시작했던 2023년에는 비트당 비용이 50배 더 저렴했는데, 지금은 아마 100배 정도 더 저렴할 것이며, 비트당 전력 소모는 30배 더 낮습니다. 이는 매우 훌륭합니다. 다만 한 가지 작은 문제가 있습니다. 플래시는 500배 더 느리며, 이는 성능이 좋지 않을 것이라는 점입니다. 우리 모두 스왑 (swap)이 최악이라는 것을 알고 있기에, 우리는 이 문제들을 해결해야만 했습니다.”
간단한 해답은 DRAM에 콜드 데이터 (cold data)를 두는 것을 중단하고, 핫 데이터 (hot data), 즉 지금으로부터 수십 나노초 (nanoseconds) 후에 핫 데이터가 될 데이터로 DRAM을 가득 채우는 것입니다. 페이지 (pages)를 핫에서 웜 (warm), 그리고 콜드로 전환하여 플래시로 밀어내는 것은 비교적 쉽습니다. 하지만 진짜 문제는 CPU에서 실행되는 단 하나의 명령어로 인해 데이터가 콜드에서 레드 핫 (red hot) 상태로 변할 수 있으며, 이는 1나노초의 아주 짧은 순간에 일어난다는 점입니다.
이를 수행하기 위해, MEXT는 이른바 예측 메모리 (Predictive Memory)를 구축했습니다. 물론 애플리케이션과 메모리 액세스 패턴 (memory access patterns)을 관찰하기 위해 AI 알고리즘을 사용하며, 애플리케이션이나 운영체제 (OS)가 데이터를 요청하기 전에 플래시에서 해당 데이터를 DRAM으로 다시 가져옵니다.
“우리는 과거에 이루어졌던 것보다 훨씬 더 나은 예측 정확도와 범위를 가진 정교한 머신러닝 (Machine Learning) 모델을 개발했습니다,”라고 Waldspurger는 설명합니다. “우리는 LSTM 및 LLM 트랜스포머 (Transformer)와 같은 신경망 (Neural Networks) 기반의 현대적인 AI 기술에서 영감을 얻었는데, 이러한 기술들은 실제로 시퀀스 예측 (Sequence Prediction)에 매우 탁월합니다. 자연어 대화에서 토큰 (Tokens)을 예측하는 대신, 우리는 유사한 아이디어를 적용하여 미래의 메모리 페이지 액세스 (Memory Page Accesses) 시퀀스를 예측합니다. 그리고 우리의 AI 모델은 비동기적 (Asynchronously)으로 실행되기 때문에, 장기적인 트렌드에 대한 더 풍부한 정보와 컨텍스트 (Context)를 활용할 수 있으며, 전통적인 방식에서는 고려되지 않는 하드웨어 카운터 (Hardware Counters), 소프트웨어 이벤트 (Software Events), 그리고 애플리케이션 기능들을 활용할 수 있습니다. 우리의 AI 엔진은 함께 작동하는 모델 제품군으로 구성되어 있으며, 따라서 경량 휴리스틱 예측기 (Heuristic Predictors)와 더 강력한 신경망 모델을 결합한 앙상블 (Ensemble) 형태를 갖추고 있습니다. 또한 우리는 다른 AI 기술들도 적극적으로 탐색하고 있으며 좋은 성과를 거두고 있습니다.”
현재 Predictive Memory Engine은 X86 또는 Arm CPU를 사용하는 Linux 시스템에서만 작동하지만, 필요하다면 RISC/Unix 또는 독자적인 (Proprietary) 시스템으로 이식하지 못할 기술적인 이유는 없습니다. 이 메모리 확장 기술은 베어 메탈 (Bare Metal) 머신뿐만 아니라 가상 머신 하이퍼바이저 (Virtual Machine Hypervisors)나 Kubernetes 컨테이너 컨트롤러 (Container Controllers)에 의해 워크로드 (Workloads)가 오케스트레이션 (Orchestrated)되는 시스템에서도 작동합니다. MEXT 메모리 확장을 위한 권장 구성은 필요한 메모리 양을 파악한 다음, 서버에 DRAM 절반과 플래시 (Flash) 카드를 절반씩 구매하는 것입니다. Smerdon은 MEXT가 DRAM 25%와 플래시 75%로 구성된 시스템을 테스트했으며, 이 또한 잘 작동한다고 말합니다. 우리는 1:1 비율과 비교했을 때 1:3 비율에서는 성능 저하가 있을 수 있다고 추정하며, 이 또한 전적으로 워크로드에 따라 달라질 것이라고 가정합니다.
워크로드 측면에서 보면, Smerdon에 따르면 이미 메모리 최적화가 내장된 인메모리 데이터베이스 (in-memory databases)는 MEXT 확장 메모리에 완벽하게 부합하지만, 전통적인 관계형 데이터베이스 (relational databases)는 그만큼 이상적이지 않습니다. Smerdon에 따르면 전자 설계 자동화 (Electronic design automation), 데이터 분석 (data analytics), 디지털 콘텐츠 제작 (digital content creation) 워크로드는 이 확장 메모리에 "매우 훌륭하게 적합 (screamingly good fits)"합니다. 또한 이미 이를 사용하여 무엇을 하고 있는지는 알 수 없으나, 대형 은행과 헤지펀드들이 이를 사용하고 있습니다. 그래프 데이터베이스 (Graph databases) 역시 MEXT가 예상하지 못했던 부분인데, 확장 메모리에서 놀라울 정도로 성능이 좋습니다.
AMD 인수 전, MEXT는 Predictive Memory Engine 구독에 대해 연간 GB당 3.99달러의 고정 수수료를 부과했습니다. AMD의 계획이 무엇인지는 알 수 없습니다. 저희가 보여드릴 수 있는 것은 MEXT가 Dell 서버 및 AWS 클라우드 인스턴스를 대상으로 수행한 비교 결과입니다.
다음은 MEXT 확장 메모리 사용 여부에 따른 Dell 서버 비교 결과입니다:

여기서 흥미로운 점은 플래시 확장 메모리를 사용할 때 서버 비용이 얼마나 저렴해지는가뿐만 아니라, Dell이 더 이상 메인 메모리 옵션으로 3 TB 및 6 TB를 탑재한 PowerEdge R6725 서버를 출하하지 않는다는 사실입니다. (이는 2월 1일 기준입니다.) 플래시와 DRAM을 1:1 비율(각각 1.5 TB)로 구성하면 3 TB까지 확보할 수 있으며, 1.5 TB의 DRAM과 4.5 TB의 플래시를 1:3 비율로 구성하면 6 TB의 유효 용량 (effective capacity)을 확보할 수 있습니다.
다음은 AWS 비교 결과입니다:
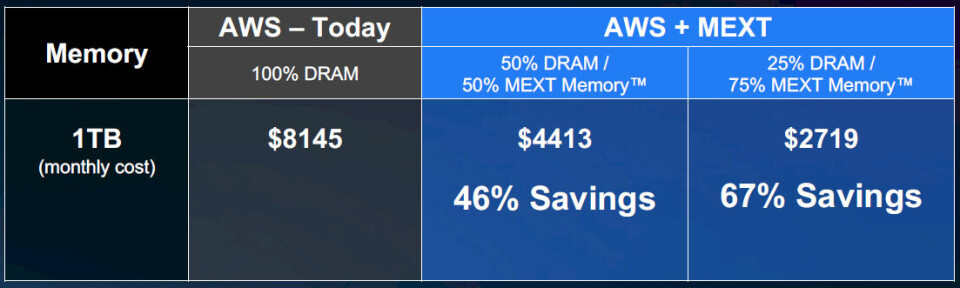
이 비교를 위해 어떤 인스턴스 유형이나 크기가 사용되었는지는 알 수 없으나, 로컬 플래시 (local flash)가 있는 인스턴스들과 비교하고 있음은 분명합니다.
MEXT는 AMD "Zen 5" 128코어 Epyc 9755, 12개의 6.3 GHz 메모리 스틱, 그리고 Kioxia NVM-Express 플래시 드라이브가 장착된 머신에서 특정 워크로드를 대상으로 성능 테스트를 수행했습니다. 해당 머신은 Linux 6.17.1 커널을 포함하는 Red Hat Enterprise Linux 8.10을 실행했습니다. 머신의 메모리는 64 GB였습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기