
AI Engineering Summit Tokyo 2026(2일차) 세션 리포트 — 모델의 구분 사용부터 「구조로 지키는 운용」 「거버넌스
요약
AI Engineering Summit Tokyo 2026 2일차 세션 리포트로, 모델의 성능에만 의존하지 않고 구조적 설계와 거버넌스를 통해 AI를 실전에 활용하는 전략을 다룹니다. 태스크 특성에 따른 모델 구분 사용, 실패를 방지하는 E2E 설계, AI 거버넌스 구축 등 구체적인 운용 방안을 제시합니다.
핵심 포인트
- 모델 선정 시 성능이 아닌 태스크 특성과 비용 효율성을 고려한 적재적소 배치 강조
- 프롬프트 의존도를 낮추고 시스템 구조로 AI의 실패를 방지하는 설계 사상
- AI 거버넌스, AI Gateway, 사용자 대리 인증을 통한 통제 체계 구축
- AI 주도 개발을 조직 문화로 정착시키기 위한 학습 루프와 단계적 도입
AI Engineering Summit Tokyo 2026(Summer)의
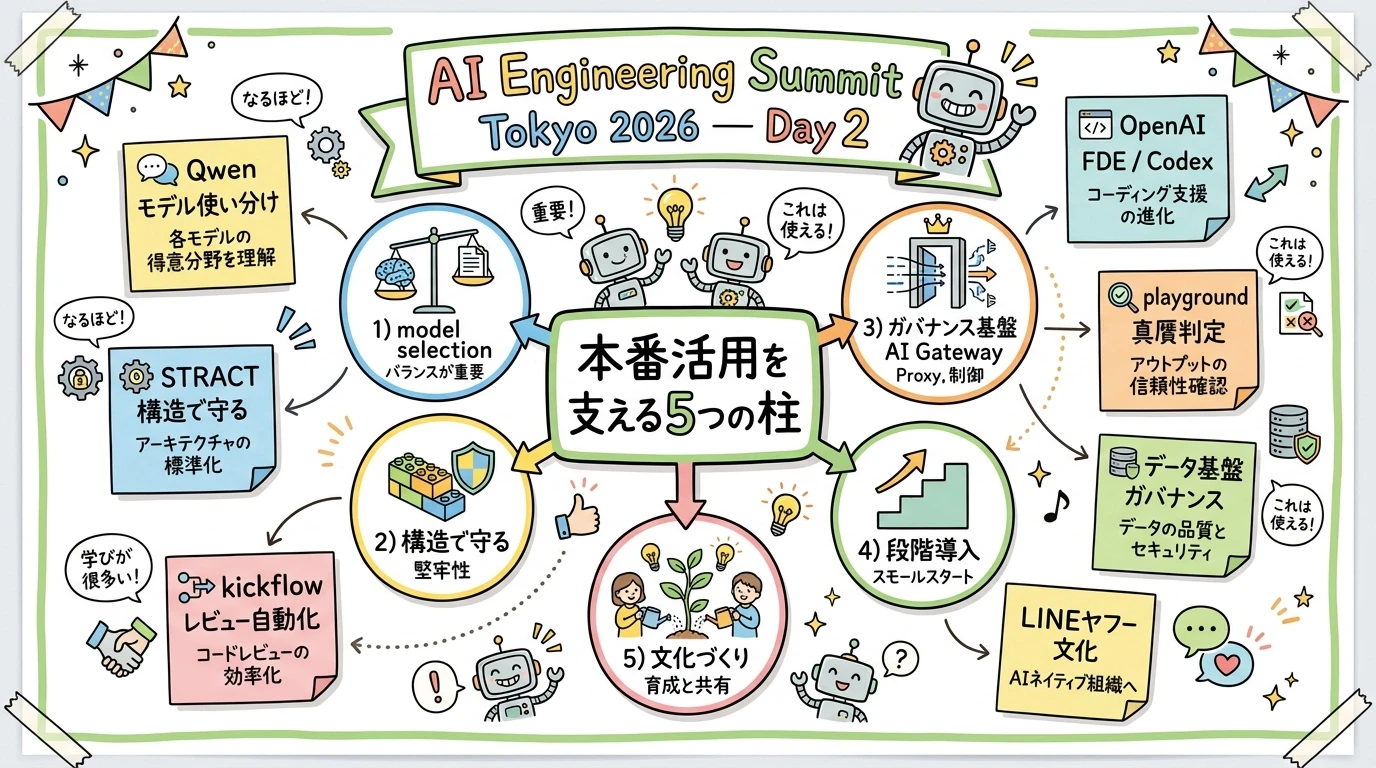
2일차(2026/06/09)에 청강한 7개 세션의 리포트입니다. 1일차가 「AI로 만들 수 있는 것은 전제가 되었고, 논점은 운용·통제로 옮겨가고 있다」는 큰 흐름이었다면, 2일차는 그 「실전 활용」을 뒷받침하는 구체적인 내용——모델의 구분 사용, 실패를 구조로 없애는 설계, 거버넌스 기반, 그리고 AI 주도 개발을 조직의 「문화」로 만드는 노력——이 각 현장에서 입체적으로 이야기되었습니다.
업종은 클라우드 벤더, 커머스 앱, 엔터테인먼트 DX, 데이터 기반, 워크플로우 SaaS, 대규모 Web 서비스, 그리고 OpenAI까지 폭넓었으며, 입장 또한 CTO·테크 리드·현장 엔지니어 등 다양했습니다. 그럼에도 공통적으로 들려온 것은 「prompt(부탁)에 의존하지 않고, 구조로 지킨다」는 설계 사상과 「AI에게 맡기는 범위를 실적 데이터를 보며 단계적으로 넓힌다」는 운용 관점이었습니다.
이 기사에서 알 수 있는 것:
- 🧭 2일차를 관통하는 공통 테마 (실전 활용을 뒷받침하는 5가지 기둥)
- 🧩 모델을 「성능」이 아닌 「태스크 특성」으로 선택하는 사고방식 (Qwen의 구분 사용)
- 🏗️ 「실패를 구조로 없애는」 E2E AI-Native 개발 기반의 실례 (20명으로 100억 엔 규모)
- 🔐 AI 거버넌스와 AI Gateway, 사용자 대리 인증이라는 통제의 핵심
- ⚙️ 코드 리뷰 자동화를 「결정론적인 가드레일」로 안전하게 돌리는 설계
- 🌱 AI 주도 개발을 「문화」로 만드는 학습 루프 (LINE야후 ODW)
- 🔄 OpenAI가 이야기한 FDE와 Codex를 중심으로 한 outer loop
개별 세션에 들어가기에 앞서, 전체상을 먼저 제시합니다. 2일차의 이야기를 나열하면, 「실전에서 사용할 수 있는 에이전트」를 뒷받침하는 요소는 다음 5가지로 정리할 수 있었습니다.
이 도표의 포인트는 어떤 세션도 「모델이 똑똑해지면 해결된다」고 말하지 않는다는 점입니다. 똑똑함의 바깥에 있는 설계——구분 사용·구조·통제·단계·문화——를 어떻게 만들 것인가에 각 사의 지견이 집중되어 있었습니다. 청강한 7개 세션은 다음과 같습니다.
| # | 세션 | 발표자 (소속) | 주제 |
|---|---|---|---|
| 21 | Qwen×Happy Horse에서 배우는 AI 선정 전략 | 후지카와 유이치 씨 (Alibaba Cloud) | 태스크 특성에 따른 모델 구분 사용 |
| ... |
2일차의 시작은 Alibaba Cloud의 후지카와 씨에 의한 모델 선정 세션이었습니다. 출발점은 명쾌했습니다. 「성능만으로 선택하지 않는다」. 단일한 클로즈드 대규모 모델에만 의존하면 비효율, API 이용료 고등, 개별 요건에 대한 파인튜닝 (Fine-tuning) 불가라는 문제가 발생합니다. 대신 다음 4개 축으로 모델 클래스를 결정해야 한다고 제시되었습니다.
이 도표의 포인트는 「모든 것에 고성능 모델은 필요하지 않다」는 단호함입니다. 적재적소의 배치야말로 비용 효율과 ROI를 최대화하는 열쇠라고 언급되었습니다.
그 맥락에서 소개된 것이 Qwen입니다. Qwen은 오픈 웨이트 모델 (Open-weight model)의 보급으로 인한 「AI의 커모디티화 (Commoditization)」를 상징하는 모델 패밀리로, 300개 이상의 오픈 웨이트 모델, 10억 다운로드, 20만 개 이상의 파생 모델이 있다고 밝혔습니다. 최신 모델의 구분 사용은 다음과 같습니다.
| 모델 | 포지션 | 특징 (발표 시점) |
|---|---|---|
| Qwen3.7-Max | 성능 최우선 | 최첨단 코딩 에이전트, 장시간 자율 실행, 복잡한 추론 |
| ... |
가격 예시로, 2026년 5월 시점의 International 리전에서 Max가 입력 $2.5 / 출력 $7.5 (per 1M), Plus가 입력 $0.4 / 출력 $1.6, Flash가 입력 $0.25 / 출력 $1.5라고 소개되었습니다. 바이브 코딩 (Vibe coding)의 비용 최적화에서는 통상적인 태스크를 Qwen으로 저비용화하고, 복잡한 추론만 타사 모델을 사용하며, 긴 문맥은 Qwen의 100만 토큰으로 대응하는 등 태스크 난이도별로 여러 LLM에 분배하는 사례가 제시되었습니다.
Alibaba Cloud는 텍스트인 Qwen에 더해, 영상·이미지 생성인 Wan, 음성 계열인 Fun, AI 에이전트가 탑재된 IDE인 Qoder까지 전 방위로 전개하고 있습니다.
| 계통 | 내용 |
|---|---|
| Qwen | LLM · 멀티모달 · 전문 모델 (VL / Omni / Image / Audio / Coder / Embedding 등) |
| ... |
동영상 생성 모델인 HappyHorse 1.0은 '세계 No.1 AI 비디오 생성 모델'로서, 1080p HD · 최대 15초 생성이 소개되었습니다. 운용 측면에서는 기반 모델 API 플랫폼인 Model Studio (미터링 · 과금, 권한 관리, 레이트 리밋(Rate Limit) 등)와, GPU를 82% 절약하고 처리 지연을 97% 감소시킨다는 GPU 최적화 기술 Aegaeon도 언급되었습니다. 데이터는 일본 국내 Alibaba Cloud 데이터 센터 내에서 완결되며, 일본 법 및 컴플라이언스(Compliance)를 준수한다는 국내 요구사항에 대한 배려도 강조되었습니다.
💡 마무리 '핵심 포인트(勘所)'는 세 가지였습니다. 성능이 아닌 태스크 특성으로 선택할 것 / 하나의 모델에 의존하지 않고 역할에 따라 조합할 것 / API 계층에서 느슨한 결합(Loose Coupling)을 통해 교체 가능하게 하고, 기존 시스템에 단계적으로 통합할 것. 첫째 날부터 이어지는 '구분 사용'에 관한 이야기가 구체적인 모델명으로 뒷받침된 세션이었습니다.
AI 쇼핑 앱 『PLUG』가 20명의 인원으로 연간 유통액 100억 엔 규모에 도달했다——그 뒷이야기를 우사미(宇佐美) 씨가 「E2E AI-Native」라는 설계 사상으로 설명했습니다. 중심에는 강렬한 한마디가 있습니다. ""주의하라"를 프롬프트(Prompt)에 쓰지 말고, 구조로 없애라".
프롬프트는 '부탁'일 뿐이며, LLM의 해석에 의존하기 때문에 비결정적(Non-deterministic)으로 깨지기 쉽습니다. 따라서 force push, direct merge, 비용 초과, 위험한 커맨드, 범위 외 변경 등은 프롬프트가 아니라 타입(Type), 스키마(Schema), 코드, 권한, 브랜치 보호, 하네스(Harness)를 통해 "할 수 없는 상태"로 만들어야 한다는 사고방식이었습니다.
개발 기반 구축도 구체적이었습니다. GitHub/Linear의 웹훅(Webhook)을 오케스트레이터(Orchestrator)가 받고, Claude Agent SDK의 워커(Worker)를 git worktree별로 기동합니다. "1 Issue = 1 worktree"이므로, 병렬 실행 · 실패 시 재개 · 간섭 방지가 용이한 설계입니다.
HITL (Human-in-the-loop)을 바라보는 관점도 배울 점이 많았습니다. HITL은 '사람에게 묻는 것'뿐만 아니라 '멋대로 진행하지 못하게 하는' 구조입니다. 에이전트가 AskUserQuestion을 발행하면, PreToolUse hook이 질문을 Linear로 전송하고 세션을 정지합니다. 최대 7일까지 대기하며, 답변이 오면 resume(재개)하기 때문에 대기 중에는 비용이 발생하지 않습니다. 승인을 받지 못했는데도 자율 모드라는 이유로 구현을 진행한 사고가 있었기에, 승인 게이트(Approval Gate)는 프롬프트가 아니라 file write · commit · run tests 등의 결정적인 하네스 계층에 두어야 한다고 말했습니다.
실제 실패 사례도 솔직하게 공유되었습니다.
Approval (승인): 계획(Plan) 후 승인을 받지 못했는데도 구현으로 진행함. 강한 프롬프트를 추가해도 재발 → 승인 없이는 다음 단계(Phase)로 진행할 수 없는 구조가 필요함.
State (상태): 에이전트가 "commit을 생성했습니다"라고 말해도 마커(Marker)가 없어 멈춤 → 말(Text)이 아니라 git state를 확인하여, 정상 종료 · commit 존재 · 저장되지 않은 변경 사항 없음 등을 확인하고 push 해야 함.
Evidence (증거): tests green(테스트 통과)이나 "확인했습니다"라는 말은 UI가 작동한다는 증거가 아님 → 빌드(Build) 후 Simulator/Chrome에서 실행하고, 녹화 클립(Clip)을 Linear에 남겨 리뷰 가능하게 해야 함.
실패 관리는 로그화하여 해결해 나갔으며, 실패 로그 86건 중 69건은 구조적으로 제거(Eliminate: 승인 게이트, git 사실 판정, 범위 외 체크 등)하고, 나머지 모호한 판단은 HITL이나 프롬프트 개선을 통해 완화(Mitigate)했다고 합니다. SDK/API는 문서를 무조건 믿지 않고, 총 36개의 종합 검증 스크립트로 docs unclear/drift를 사전에 해결하는 철저함을 보였습니다.
💡 Takeaway(시사점)는 명쾌했습니다. "프롬프트를 두껍게 만들기보다, 실패할 수 없는 구조 · 결정적인 상태 확인 · 증거 기록을 먼저 구축하라". 그리고 최종적으로는 개발뿐만 아니라, Ops(Scoped token으로 초안 작성까지만 제한하고 인간 승인 후 반영)나 슬라이드 작성까지, 모든 업무를 AI-Native로 만들어가는 방향이라고 밝혔습니다.
전자 티켓 발권 서비스 MOALA를 제공하는 playground는 엔터테인먼트 인맥 제로 상태에서 오직 기술력만으로 국내 No.1 점유율에 도달한 회사입니다. 이토(Ito) 씨와 후나구치(Funaguchi) 씨의 세션은 "AI 네이티브한 회사로 제로 베이스에서 다시 만들기"라는 조직 개혁과, 그 여백에서 도전하는 크리에이티브 엔지니어링(Creative Engineering)에 관한 이야기였습니다.
상징적인 것은 "AI 풀 활용"이 아니라 "AI가 주역인 회사"라는 표현입니다. 사람 사이의 정보 공유가 아니라 AI를 경유하여 파일을 공유하고, 인간이 설명하고 끝내는 것이 아니라 AI가 참조·재사용할 수 있는 형태로 남깁니다. 전문 분야별 분업이 아닌 혼자서 성과를 내는 체제로 전환하고, 입력 방식도 키보드에서 음성으로 이행했다고 합니다. 개발 프로세스의 변화는 수치로 제시되었습니다.
| 지표 | 상황 (등단 시점) |
|---|---|
| Figma → 프론트엔드 코드화율 | 90% |
| ... | |
| 이 문화를 상징하는 것이 안면 인식 기술의 자체 개발이었습니다. 고객 인터뷰에서는 "니즈가 없다", "절대 제안하지 않겠다", "방문객이 싫어한다"라며 혹평을 받았다고 하지만, 그럼에도 미래를 믿고 이벤트 업계 특화 안면 인식 기술인 BioQR을 자체 개발했습니다. 현재는 초대형 페스티벌이나 돔급 공연에서 연간 수백만 장 규모로 사용되며, 방문객들이 도입한 공연을 찬사하는 서비스로 성장하였고, 미국·유럽을 포함한 세계 각국에서 특허도 등록 완료되었다고 합니다. "눈앞의 고객을 기쁘게 하는 것"이 아니라 "5년 후의 시장을 놀라게 하는" 가치에 경도되는 문화가 토대가 되어 있습니다. |
후반부는 "AI가 없었다면 도전하지 않았을 기술"에 관한 이야기였습니다. 스마트폰 화면의 "겉모습"만으로는 진위 판별이 불가능하여, 스크린샷을 이용한 QR 전매나 AI를 통한 화면 위조가 과제가 되고 있습니다. 기존 견적으로는 72인월(3명 × 3년)이 소요되며 성공 여부도 불확실했기에 미뤄져 왔던 영역입니다. 현장에서는 스태프가 1초 이내에 판정해야 하며, 통신도 허용할 수 없습니다.
이에 따라 특허 출원 완료된 사양으로서 "시간 경과에 따라 완전히 랜덤하게 변화하는 기호 & 색상"을 표시하여, 통신이 필요 없음에도 모든 올바른 단말기에서 표시가 동기화되는 메커니즘을 만들었다고 합니다. 위조 방지를 위해 표시 내용을 비보유화(non-retention)하여 "훔칠 것이 없는" 상태로 만들고, Web 앱 측에서도 WebAssembly를 사용하여 전용 VM을 구축해 복원이 어렵게 만드는 등 철저한 모습을 보였습니다.
💡 인상적이었던 점은 AI 활용의 논점 정리였습니다. "현재의 AI 활용은 공수 절감이 목적이 대부분이지만, 본질적으로는 'AI가 없었다면 만들 수 없었을 기술'을 만들 수 있게 되는 것이다." 효율화 너머의 창조성으로 발을 들인 세션이었습니다.
Chura Data, Databricks, Findy 3사가 진행한 데이터 기반과 거버넌스(Governance)에 관한 세션입니다. 출발점은 "PoC(Proof of Concept)는 급속히 확산되었지만, '실전에서 사용할 수 있는' 에이전트에 도달한 기업은 아직 많지 않다"라는 현실이었습니다. 소개된 수치가 이를 뒷받침합니다.
| 지표 (등단 시 소개) | 수치 |
|---|---|
| 파일럿의 40% 이상을 실전으로 전환한 기업 | 25% |
| ... | |
| 실전 품질로 단계적으로 높일 필요가 있으며, 업무 적합성·출력 품질·거버넌스 및 안전성·운용성 및 확장성(Scalability)·비용 효율성이라는 5가지 관점이 제시되었습니다. 그리고 "똑똑해진 에이전트가 현장에서 사용되지 못하는 이유는 지능이 아니라 컨텍스트(Context) 부족"이라는 지적이 핵심이었습니다. 사내 데이터에 "지난달 매출은?"이라고 물어도, 자사만의 매출 정의·지표·규칙을 모르면 그럴듯하지만 틀린 숫자를 반환합니다. 여기서 효과적인 것이 시맨틱 레이어(Semantic Layer)(테이블·컬럼·원시 값에 의미·지표·관계성을 정의하여 에이전트에게 문맥을 공급하는 계층)였습니다. |
거버넌스 이야기도 구체적이었습니다. AI 에이전트의 데이터 액세스는 급속히 확장되는 반면 제어가 따라가지 못하고 있으며, 소개된 수치는 다음과 같습니다.
- AI 에이전트가 82% 도입되었다는 전제하에, 80%의 기업이 의도하지 않은 액션을 경험
- 내역: 미인증 시스템으로의 액세스 39% / 기밀 데이터에 대한 부적절한 액세스 33% / 기밀 데이터 다운로드 32% / 기밀 정보의 부적절한 공유 31%
- 거버넌스를 도입하고 있는 기업은 44%에 머무름
권장되는 설계는 "에이전트 + 사용자 대리 인증 (User Delegation Authentication)"입니다. 에이전트에 슈퍼 권한 (Superuser privileges)을 부여하면 사용자의 권한 범위를 벗어난 데이터에도 액세스할 수 있게 되므로, 에이전트가 사용자의 권한을 승계하는 형태로 구성하여 의도한 대로의 액세스를 보장합니다. 나아가 난립하는 "에이전트 확산 (Agent Sprawl)"에 대해서는 AI Gateway / Agent Gateway (예: Unity AI Gateway)와 같은 프록시 (Proxy) 계층이 필요하다고 언급되었습니다.
이 그림의 핵심은 에이전트를 개별적으로 방류하는 것이 아니라, 프록시 계층에서 집약하여 거버넌스 (Governance)를 적용하는 것입니다. 마무리 단계에서는 AI 거버넌스가 "있으면 좋은 것"에서 "필수"로 변화하고 있으며, AI Gateway가 표준 사양으로 탑재되는 시대가 올 것이라는 업계의 관점이 공유되었습니다.
워크플로 SaaS인 kickflow의 모리모토 님은 "코드 리뷰에 AI 에이전트를 실무에 투입한" 사례를 공유했습니다. 방침은 "인간의 판단이 불필요한 개발 업무는 AI에게 맡긴다"였습니다. 전제 조건은 GitHub, GitHub Actions, Claude Code, CodeRabbit, Renovate였으며, 당시 환경은 1개 팀 6명, 모노레포 (Monorepo), 거의 매 영업일 배포가 이루어지는 환경이었습니다.
과제는 AI 코딩으로 인해 PR (Pull Request) 수가 증가하면서, 사람이 모든 PR을 리뷰하는 운영 방식이 한계에 도달했다는 점이었습니다. 이에 따라 AI가 PR마다 영향도를 자동으로 판정하여 CI 내에서 XS/S/M/L/XL 라벨을 부여하도록 했습니다. 그리고 라벨별로 리뷰 담당자를 나누었습니다.
| 라벨 | 내용 예시 | 리뷰 방침 |
|---|---|---|
| XS | 오타 (typo), 주석, 설정값 변경 | 자동 머지 (Auto-merge) |
| ... |
과거 PR을 판정 로직으로 평가한 결과, XS+S가 65%를 차지하여 인간의 리뷰는 최대 35%까지 억제할 수 있을 것으로 전망되었다고 합니다. 중요한 점은 비결정론적인 (Non-deterministic) AI 판정을 결정론적인 (Deterministic) 토대 위에서 수용하는 설계였습니다.
이 그림의 핵심은 비결정론적인 A/B (AI 판정·AI 리뷰)를 결정론적인 C/D/E (CODEOWNERS·Branch Protection·자동 머지)로 받아내는 것입니다. AI가 영향도 판정을 실수하더라도, 모든 PR에서 반드시 실행되는 CodeRabbit이 최종 방파제 역할을 하며, 고위험 영역은 CODEOWNERS를 통해 반드시 사람에게 전달됩니다.
구현 과정에서는 예상치 못한 상황도 있었습니다. GitHub 표준 자동 머지 + 필수 상태 체크 (Required status checks) 방식으로는 정적으로 지정된 CI만 확인할 수 있어, 너무 빠른 머지나 pending 상태 고정 문제가 발생했습니다. 이를 해결하기 위해 별도의 워크플로 완료를 감지하여 실제로 실행된 모든 잡 (Job)을 가져온 뒤, 모두 성공했을 경우에만 머지하는 자체 워크플로를 구축했다고 합니다. 도입 또한 단계적으로 진행되었습니다. 우선 라벨 판정만 운영 → XS만 자동 머지 → S를 인간 리뷰 필수 대상에서 제외 → XS도 CodeRabbit을 통과시키는 순으로 맡기는 범위를 넓혀갔습니다.
💡 효과는 수치로 나타났습니다. 동일한 규모의 작은 PR (impact/XS·S, QA 단계 없음)이 머지되기까지의 중앙값은 약 5시간에서 26분으로 단축되었습니다. 배운 점은 "AI에게 맡기는 범위는 추측이 아닌 실적 데이터로 선을 그어야 한다", "폭주는 결정론적인 가드레일 (Guardrail)로 막는다", "갑자기 넓히지 말고 육안으로 확인하며 단계적으로 진행한다"였습니다.
LINE 야후의 히라노 님과 이노우에 님은 "AI 주도 개발을 문화로 만드는" 노력을 현장 관점에서 이야기했습니다. 어려운 것은 도구 도입이 아니라 **행동 변화 (Behavioral change)**입니다. 탑다운 (Top-down) 방식의 방침이 있더라도 현장에서는 "무엇이 올바른 사용법인지 모르겠다", "이 도구를 사용해도 되는지 망설여진다", "개별적으로 해결해도 지식이 공유되지 않는다"와 같은 문제가 발생합니다. 필요했던 것은 방침을 "시도할 수 있는 학습 루프 (Learning loop)"로 전환하는 것이었습니다.
그 핵심이 바로 ODW (Orchestration Development Workshop)입니다. 강의 형식이 아니라 발표자의 작업과 개발 프로세스를 직접 체험하는 워크숍 (Workshop) 형식으로, 정기 개최·전사 횡단 길드 (Guild)를 통한 테마 선정·JP/KR/EN 언어로 전사 전개되는 설계로 되어 있습니다.
이 그림의 핵심은 「보기 → 시도하기 → 회고하기 → 재사용하기」의 루프에 더해, 아카이브와 재사용을 위한 동선까지 포함하여 설계했다는 점입니다. 성과는 수치로 증명되었습니다.
| 지표 (LINE Yahoo ODW, 발표에서 소개) | 수치 |
|---|---|
| PAT 미이용률 (4개월 만에 개선 · 2026/1 시점) | 53% → 33% (약 20pt 개선) |
| ... |
문화 구축의 설계 원칙은 세 가지—Learning loop (방침을 시험할 수 있는 체험으로 바꿈), Spread, not only usage (도입률뿐만 아니라 롱테일(Long-tail) 도달을 봄), Local autonomy (정답을 고정하지 않고 각자의 역량을 늘림)였습니다. "AI 주도 개발 (AI-driven development)을 확산시킨다는 것은, 전원을 같은 방식으로 맞추는 것이 아니라, 시행착오가 계속되는 메커니즘을 만드는 것이다"라는 말이 이 세션의 핵심이었습니다.
개인에서 팀으로 확산할 때의 격차에 대해서도 솔직한 이야기가 나왔습니다. 개인 단계에서는 "AI에게 상담하기"까지는 가능하더라도, 팀 단위에서는 "하나의 작업을 완전히 맡기기 (Entrusting fully)", "PR (Pull Request)로서 완결시키기"가 침투하지 못하고 있었습니다. 허들(자신이 없음 · 시간이 부족함 · 정보를 쫓기 힘듦 · 사내 규칙)은 "보여주기"라는 하나의 수단으로 동시에 낮출 수 있다고 하여, 화면 전체를 공유하고 채팅 이력도 전달하는 활동이 소개되었습니다.
💡 이용 보급 그 너머의 숫자도 강렬했습니다. "AI만으로 작성한 PR" (직접 코드를 쓰지 않고 Agent에 대한 지시 반복만으로 만드는 PR)의 비율은 2025년 10월 1.7%에서 2026년 5월에는 79.5%까지 늘어났다고 합니다. 반면 이용량에는 상위와 하위 간에 수 배의 차이가 있어, "태스크의 목표를 멀리 두기", "완전히 맡기기"가 아직 충분하지 않다는 과제도 공유되었습니다. 이를 끌어올리는 방법은 목표 공유 · 시행착오 · 역량 늘리기라는 세 가지 기둥으로 설계하고 있다고 합니다.
2일차의 마지막은 OpenAI의 Ryan Cain 님과 Sean Saito 님에 의한 FDE 세션이었습니다. LLM의 성능은 단기간에 비약적으로 성장하고 있는 한편, 모델 성능과 기업에서 실제로 창출되는 가치 사이에는 격차가 존재합니다. OpenAI의 FDE (Forward Deployed Engineer)는 고객과 프로덕트 리서치 사이에서 이 격차를 메우는 역할을 합니다. 기업으로의 도입 · 구현과 현장에서 얻은 배움을 연구로 되돌리는 피드백—이 선순환을 만듭니다.
인상적이었던 점은 "AI 개발 도구는 '구현 지원'에 머물기 쉽다"라는 지적이었습니다. 대부분의 도구는 Build (코드 구현) 지원에 집중하고 있지만, 개발자가 실제로 코드를 작성하는 시간은 약 16%에 불과합니다. Plan · Design · Test · Review · Document · Deploy까지 포함한 개발 프로세스 전체를 AI로 다루지 않으면 기업 가치로 이어지기 어렵습니다.
그래서 제시된 것이 inner loop에서 outer loop로의 이행이었습니다. 이전에는 개발 팀이 워크플로우를 설계하고 개별적으로 전문 에이전트를組み込む (조합하여 포함할) 필요가 있었습니다 (inner loop). 현재는 Codex를 중심으로 한 루프를 정의하고, 많은 태스크를 맡기는 outer loop의 형태로 옮겨가고 있습니다. Codex를 중심으로 한 구성은 다음 4가지 요소로 정리되었습니다.
이 도표의 포인트는 "AI에게 구현시키기"뿐만 아니라, Grounding · Skill · Tool · Feedback loop를 세트로 설계하는 것입니다. 소개된 세 가지 유스케이스(Use case)도 모두 이 4가지 요소로 정리되어 있었습니다.
| 유스케이스 | Grounding | Skill | Tool | Feedback loop |
|---|---|---|---|---|
| 반도체 에이전트 | 리포지토리 / 워크플로우 | 임베디드 개발 / 평가 | 디자인 툴 / 문서 | 압축 테스트 / 최적화 루프 |
| ... |
영업 에이전트 데모에서는 상담 상대의 정보로부터 내부용 브리핑 PDF를 생성하는 Account Brief Studio가 제시되었습니다. "'AI로 무엇을 할 수 있는가'보다, 거점 횡단으로 절차를 가시화 · 표준화하여 현장 책임자가 의사결정할 수 있는 상태를 만드는 쪽으로 무게를 두는 것이 좋다"라는 시사점은 매우 현실적인 지적이었습니다.
💡 자사 에이전트 개발에 주는 시사점은 명쾌했습니다. 에이전트는 단일 기능이 아니라 Grounding · Skill · Tool · Feedback loop를 세트로 설계해야 한다. MCP나 사내 툴 연결은 중요하지만 그것만으로는 부족하며, 결과물을 평가하고 사용자 평가나 에러 검출을 다음 개선으로 되돌리는 메커니즘이 필요하다. 그리고 FDE처럼 현장에 뛰어들어 해결해야 할 과제를 선택하고, 구현한 것을 프로덕트나 표준 기능으로 되돌려 보내는—이 흐름이 중요하다며 마무리되었습니다.
1일 차와 2일 차를 나란히 살펴보면, 업종이나 입장을 초월하여 몇 가지 공통점이 더욱 뚜렷하게 부각되었습니다.
-
🔁
에이전트(Agent)는 “확장 전제”로 설계한다. 플로우(Flow)를 유연하게 교체하거나 정지시킬 수 있는 것이 중요하며, 기능은 에이전트의 “도구 (Tool)”로서 구현한다. - 🧩
최적해는 시대에 따라 변한다. 그렇기에 교체하기 쉽게 만들어 두어야 한다. 룰 베이스 (Rule-based)와 LLM 베이스 (LLM-based)의 구분 사용이 현실적이었습니다 (2일 차의 Qwen 구분 사용 및 kickflow의 판정이 바로 이 사례입니다). - ❓
AI에게 “질문”하여 범용 지식을 끌어낸다. 단순히 지시하는 것에 그치지 않고, 파운데이션 모델 (Foundation Model)로부터 지식을 끌어내는 태도가 공통적이었습니다. - 🔍
품질 보증은 복수 모델의 상호 체크. Claude나 Codex 등 여러 AI에게 상호 리뷰를 맡기는 운용 방식이 반복해서 등장했습니다. - 🛡️
중심축은 “생성”에서 “권한·감사”로. 에이전트가 프로덕트를 생성하는 것은 당연한 일이 되었으며, 시대는 에이전트의 권한 설계나 감사 방법에 집중하고 있습니다. - 🧱
그리고 2일 차의 통주저음은 “구조로 지키는 것”이다. STRACT의 “프롬프트 (Prompt)에 쓰지 마라, 구조로 없애라”, kickflow의 “결정론적인 토대에서 받아낸다”, Databricks 계열의 “AI Gateway · 사용자 대리 인증”——이 모두 “부탁”이 아닌 “메커니즘 (Mechanism)”으로 가드(Guard)한다는 사상으로 일치했습니다. - 🌱
마지막은 “문화”. LINE Yahoo의 ODW가 보여준 것처럼, 실전 활용의 열쇠는 결국 “조직이 시행착오를 계속할 수 있는 메커니즘을 어떻게 만드는가”로 귀결됩니다. OpenAI가 “OpenAI는 FDE에 주력하고 있다”라고 언급한 것도, 기술을 가치로 바꾸는 “사람과 메커니즘”에 대한 투자라는 점에서 같은 방향이었습니다. -
AI Engineering Summit Tokyo 2026 Summer (공식 사이트) — 컨퍼런스 개요 · 타임테이블.
-
본 리포트는 2026/06/09 (2일 차)에 청강한 7개 세션의 개인 메모를 바탕으로 합니다. 각 세션에서 소개된 수치 · 가격 · 사례는 발표 내용으로서 기록된 것입니다 (시점 · 조건은 발표 당시의 기준입니다).
AI 자동 생성 콘텐츠
본 콘텐츠는 Qiita AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기