중국의 'LineShine' 올-CPU(All-CPU), 엑사플롭스(Exaflops)급 슈퍼컴퓨터 심층 분석
요약
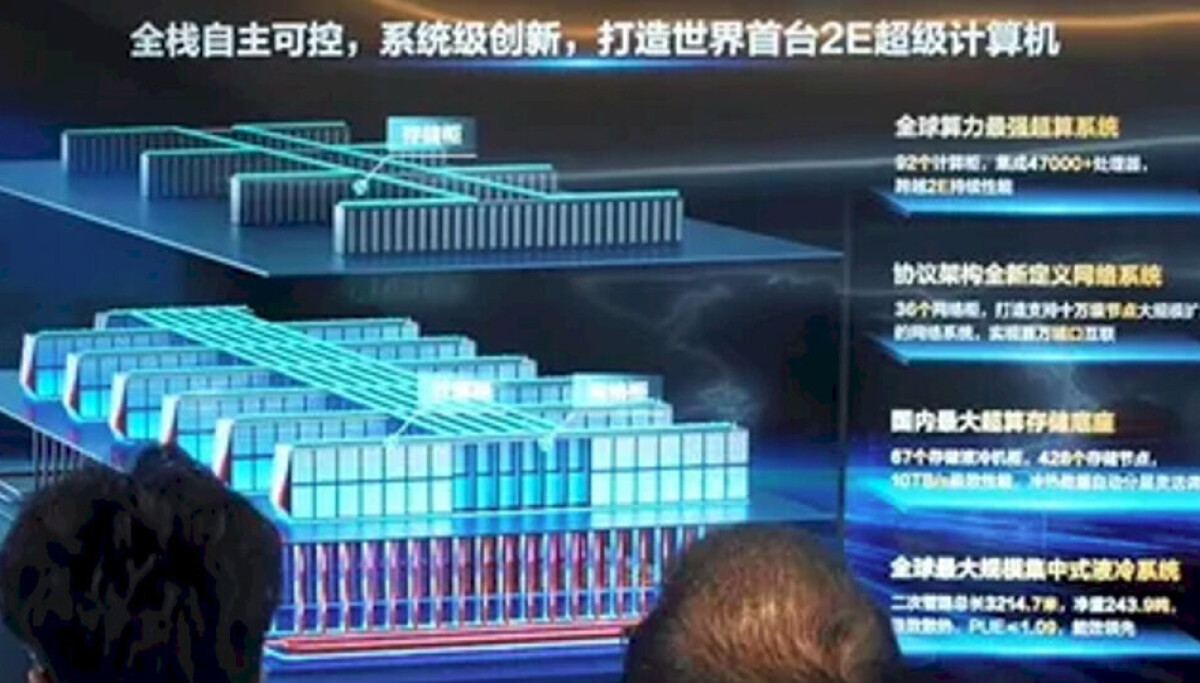
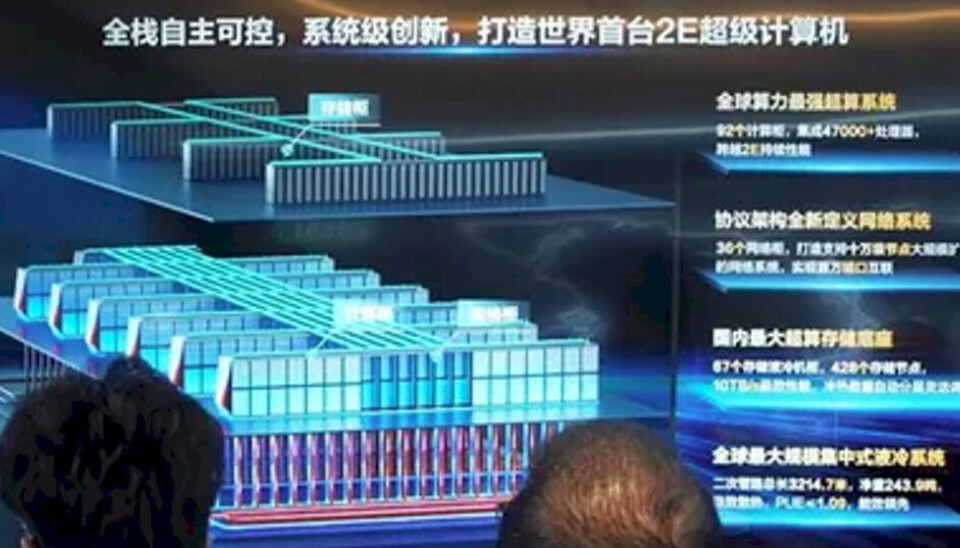
중국이 GPU 없이 CPU만으로 구성된 엑사플롭스급 슈퍼컴퓨터 'LineShine'을 구축하며 기술 자립을 가속화하고 있습니다. 미국의 반도체 수출 규제에 대응하여 SMIC 파운드리를 활용한 독자적인 HPC 아키텍처를 확보하려는 전략으로 분석됩니다.
핵심 포인트
- 중국의 'LineShine' 슈퍼컴퓨터는 올-CPU 기반의 엑사플롭스급 성능을 목표로 함
- 미국의 GPU 수출 규제에 대응하기 위한 중국의 하드웨어 자립 전략 반영
- Sunway, Phytium 등 자국산 프로세서를 활용한 독자적 HPC 생태계 구축
- 공정 기술의 열세에도 불구하고 대규모 코어 집적을 통해 성능 한계 돌파 시도
중국의 'LineShine' 올-CPU(All-CPU), 엑사플롭스(Exaflops)급 슈퍼컴퓨터 심층 분석
중국의 HPC(고성능 컴퓨팅) 슈퍼컴퓨터가 High Performance Linpack (HPL) 성능 순위 최상단에 오른 지 9년이 지났습니다. 하지만 우리 모두가 알다시피, 중국은 미국보다 먼저 64비트 정밀도에서 엑사스케일(exascale) 플롭스(flops) 장벽을 돌파했으며, 이를 두 개의 서로 다른 시스템을 통해 달성했습니다. 중국은 이를 과시하지는 않았지만, 미국 전문가들에게 충분한 정보가 유출되도록 하여 소문이 퍼지게 했습니다.
구체적으로 살펴보면, NSC Qingdao에 설치된 Sunway OceanLight 머신이 1위를 차지했습니다. 우리는 이 머신에 대해 2021년 2월에 처음 언급했고, 2022년 3월에 시스템 아키텍처(architecture)에 대해 심층 분석을 진행한 바 있습니다. Sunway SW26010-Pro CPU를 기반으로 하며 4,193만 개의 코어(core)를 보유한 전체 OceanLight 시스템은 이론적 최대 성능(peak theoretical performance)을 갖추고 HPL에서 1.22 페타플롭스(petaflops)를 기록했으며, 2021년 3월에 가동을 시작한 것으로 알려져 있습니다.
Phytium 2000 Arm 프로세서와 Matrix 3000 DSP 코프로세서(co-processor)의 하이브리드 구성을 기반으로 하는 Tianhe-3 슈퍼컴퓨터는 약 2.05 엑사플롭스(exaflops)의 이론적 최대 성능을 보유하고 있으며, HPL에서 약 1.57 엑사플롭스를 달성했습니다. 이 시스템은 2021년 10월 NSC Guangzhou에서 더 낮은 성능 수치로 처음 가동되었습니다. 이는 전체 시스템이 아니었으며, 우리가 인용하는 수치대로 2023년 12월에 완전히 구축된 것으로 보입니다. 하지만 2021년 말, 구형 Matrix 2000+ DSP 코프로세서를 사용한 Tianhe-3 프로토타입은 1.7 엑사플롭스의 피크(peak) 성능 대비 HPL에서 1.3 엑사플롭스를 기록했습니다.
이는 Oak Ridge의 'Frontier' 시스템을 앞질렀습니다. Frontier는 하이브리드 방식의 AMD 'Trento' Epyc CPU와 4개의 AMD 'Aldebaran' MI250X GPU 가속기(accelerator)를 결합한 시스템으로, 해당 컴퓨팅 엔진 전체에 걸쳐 870만 개 미만의 코어를 보유하고 있으며 HPL에서 1.19 엑사플롭스, 피크 성능 1.68 엑사플롭스로 평가되었습니다. Frontier 시스템은 2022년 5월에 승인되어 운영에 들어갔습니다.
중국은 이 날짜와 성능을 1년 이상 앞당겼으며, 더 오래된 공정 기술을 사용하고, 발열이 심하며, 많은 공간을 차지하고, 아마도 높은 비용이 들 것입니다. 컴퓨팅 엔진(compute engines)이 칩 제조 공정에서 뒤처져 있더라도, 중국이 자국의 Semiconductor Manufacturing International Corp (SMIC) 파운드리를 사용해야만 하는 상황이라면 비용은 불가피할 것입니다. 이러한 기계들은 비쌌지만, 항공기나 전쟁용 장비, 그리고 핵무기를 설계하고자 한다면 미국이 Nvidia 및 AMD GPU나 기타 컴퓨팅 엔진, 그리고 아마도 네트워킹(networking)에 대한 금수 조치를 중단하기를 기다릴 수는 없습니다. 중국은 스스로 자립하기를 원하며, 그럴 여유가 충분하고 그럴 의지도 가지고 있습니다.
Top500 슈퍼컴퓨터 순위에서 새로운 1위를 차지한 기계인 중국 NSC Shenzhen에 설치된 “LineShine” 슈퍼컴퓨터에도 동일한 접근 방식이 취해졌습니다. 하지만 LineShine을 만드는 데 사용된 모든 기술은 5년 동안 발전했으며, 이것이 바로 이 시스템이 단순히 더 클 뿐만 아니라, 이전 모델인 OceanLight 및 Tianhe-3보다 단연 더 나은 이유입니다.
LineShine은 SVE2 벡터 유닛(vector units)과 비교적 새로운 SME 행렬 연산 유닛(matrix math units), 그리고 정수 처리 유닛(integer processing units)을 갖춘 Armv9.2 CPU 코어를 기반으로 합니다. 이런 의미에서 이는 정수 처리 기능과 AVX 벡터 유닛(vector units), 그리고 AMX 행렬 유닛(matrix units)을 갖춘 Intel P-Core Xeon 프로세서와 유사합니다. 한 가지 관점에서 보면, LX2와 현대적인 Xeon P-core 컴퓨팅 엔진은 그래픽 기능이 제거된 일종의 하이브리드 CPU-GPU 복합체라고 볼 수 있습니다.
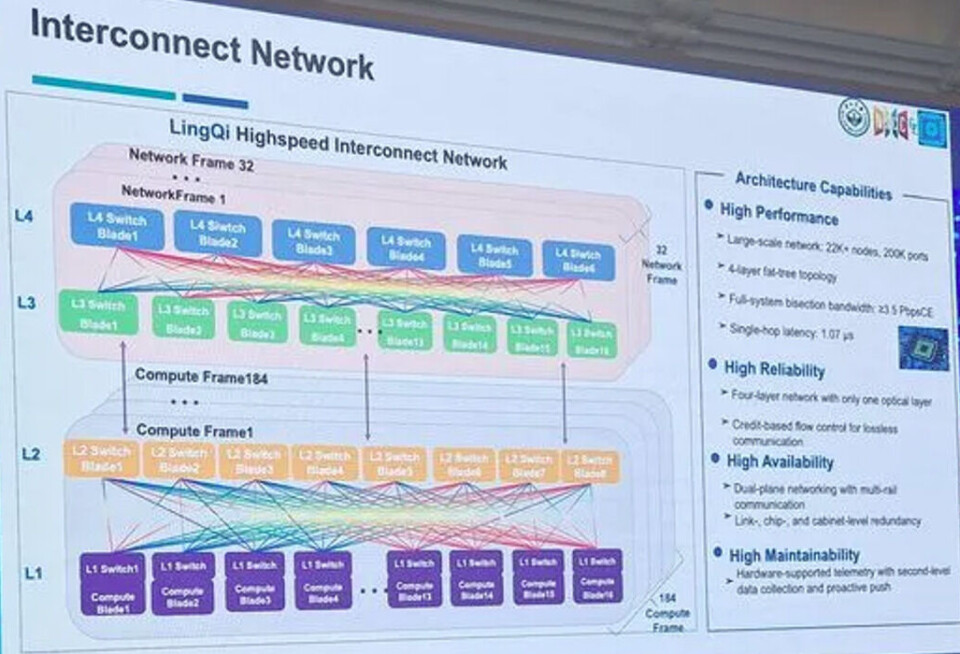
LX2 칩은 NSC Shenzhen이 중국의 IT 거대 기업인 Huawei(아마도 HiSilicon 칩 부문일 것으로 추정됨)와 협력하여 설계했습니다. LingKun LX2 CPU 설계는 소켓당 304개의 활성 코어(active cores)를 보유하고 있으며, 수율(yield)을 높이기 위해 칩에 더 많은 코어가 포함되어 있을 가능성이 매우 높습니다. LineShine 머신은 독자적인 LingQi LQLink 인터커넥트(interconnect)를 사용하는데, 이는 InfiniBand 기술의 변형을 기반으로 하고 있을 것이라 확신하지만, Ethernet의 기능을 축소하고 개조한 버전일 수도 있습니다.
이 LX2 CPU는 SVE2 및 SME 수학 유닛(math units)을 통해 충분한 FP64 성능을 제공하므로, 단 1,379만 개의 코어만으로도 2.74 엑사플롭스(exaflops, 유효 숫자 3자리 반올림)의 이론적 최대 성능(peak theoretical performance)을 낼 수 있습니다. 이는 동일하게 하이브리드 CPU-벡터-행렬(CPU-vector-matrix) 설계를 채택했던 OceanLight CPU보다 코어 수는 32.9% 적으면서도, 성능은 46.7% 더 높습니다. HPL 테스트에서 LineShine은 2.2 엑사플롭스에 약간 못 미치는 성능을 보여주는데, 이는 미국 로렌스 리버모어 국립 연구소(Lawrence Livermore National Laboratory)에 위치한 AMD MI300A 컴퓨팅 엔진 기반의 이전 1위 머신인 "El Capitan" 슈퍼컴퓨터보다 21.5% 더 강력합니다. 중국은 의심할 여지 없이 El Capitan을 넘어서길 원했으며, 더 중요한 것은 OceanLight과 Tianhe-3 머신을 능가하기를 원했다는 점입니다.
이제 이 LineShine 머신에 대해 더 깊이 파헤쳐 보겠습니다. 발음이 비슷하니 "Sunbeam"이라는 별명이 붙었더라면 좋았을 텐데 말이죠.
NSC Shenzhen은 4월 17일에 Breaking the Training Barrier of Billion-Parameter Universal Machine Learning Interatomic Potentials라는 논문을 발표했는데, 여기에는 위에서 우리가 가볍게 다루었던 LineShine 머신에 대한 몇 가지 기본적인 설명이 포함되어 있었습니다. 이 슈퍼컴퓨터의 수석 설계자인 Yutong Lu가 5월 22일부터 5월 25일까지 선전(Shenzhen)에서 개최된 제2회 연례 HPC 및 AI 공동 혁신 국제 포럼(HACI 2026)에서 진행한 발표를 통해 더 자세한 세부 정보가 공개되었습니다. LineShine에 대한 발표 내용은 공개되지 않았지만, 스위스 CSCS의 AI 및 머신러닝(Machine Learning) 수석 설계자이자 ETH Zurich의 교수인 Torsten Hoefler가 해당 행사에서 사용된 슬라이드 몇 장을 게시했습니다. 일본의 여러 연구소에서 연구원으로 활동하다가 현재는 일본 지역의 Panasas 기술 영업 매니저로 재직 중인 Ogawa Tadashi 또한 관련 내용을 게시했습니다.
이러한 게시물들은 해당 논문보다 LineShine에 대해 훨씬 더 많은 통찰력을 제공합니다. 해당 논문은 또한 China New-generation Intelligent Supercomputer (CNIS)라고 불리는 또 다른 엑사스케일(Exascale)급 슈퍼컴퓨터에 대해서도 언급했는데, 이 시스템은 공개되지 않은 한 쌍의 64비트 CPU와 출처를 알 수 없는 8개의 GPU를 사용하는 노드들을 기반으로 합니다. 아마도 이 역시 독자적인 컴퓨팅 엔진(Compute Engine)을 기반으로 하고 있을 것으로 추정됩니다. 5,632개의 노드를 보유한 이 CNIS 머신에 대해 논문은 다음과 같이 기술하고 있습니다:
“호스트 프로세서는 NUMA 아키텍처 기반의 64코어로 2.4 GHz에서 동작하며, 8채널 DDR5-6400 메모리 및 PCIe Gen5 인터페이스와 연결되어 64 GB/s의 호스트-투-디바이스(Host-to-device) 대역폭을 제공합니다. 각 GPGPU는 32.7 TFLOPS (FP64), 65.5 TFLOPS (FP32), 470 TFLOPS (FP16)의 피크 성능(Peak Performance)을 제공하며, 64 GB HBM (1.8 TB/sec 대역폭), 320개의 SIMD 유닛, 768 KB 레지스터(Register), 64 KB LDS, 8 MB L2 캐시(Cache)를 갖추고 있습니다. 가속기들은 고속 칩 간 링크(Chip-to-chip links)를 통해 상호 연결되며, 노드들은 3계층 Clos 듀얼 플레인 토폴로지(Three-layer Clos dual-plane topology)를 갖춘 독자적인 InfiniBand 유사 RDMA 네트워크를 통해 연결되어 노드당 4×400 Gb/sec의 대역폭을 제공합니다.”
하지만 우리는 여기서 LineShine에 집중하고자 합니다. 다음은 LX2 컴퓨팅 엔진 (compute engine)의 블록 다이어그램 (block diagram)과 사양 (specs)입니다:

보시다시피, LX2 설계에는 서로 연결된 두 개의 칩렛 (chiplets)이 있습니다. 각 칩렛에는 48개의 코어 블록 (core blocks)이 있으며, 각 블록에는 4개의 코어가 들어있는 것으로 보입니다. 이는 칩렛당 192개의 물리 코어 (raw cores)와 소켓당 384개의 코어를 산출하며, 이는 매우 많은 수치이지만 완전히 비정상적인 수준은 아닙니다. 노출된 304개의 코어는 수율 (yield) 때문이며, 79.2%의 코어 수율을 고려하면 이는 SMIC 파운드리 (foundry)에서 기대할 수 있는 수준입니다. 우리는 이 LX2 칩렛들이 SMIC 7나노미터 (7 nanometer) 공정의 N+3 개선 공정을 사용하여 식각 (etched)되었을 가능성이 매우 높다고 판단하며, 이는 칩이 1.55 GHz로만 작동한다는 사실에 근거합니다.
이는 SMIC가 해당 공정으로 밀어붙일 수 있는 3 GHz에는 훨씬 못 미치는 수준이지만, 메모리와 코어 속도의 균형을 맞추기 위해 의도적으로 낮춘 것으로 보입니다. 메모리는 코어보다 훨씬 빠르게 작동해야 하며, 이는 제가 지속적으로 주장해 온 바입니다. 특히 코어 클록 (core clocks)을 높이면 전력 소비 (power consumption)가 기하급수적으로 증가하기 때문입니다. 현재 상대적으로 느린 1.55 GHz(많은 GPU보다는 느리지만 큰 차이는 아님)에서 LX2 컴플렉스 (complex)는 690와트 (watts)를 소모하고 있는데, 이는 상당히 높은 수치입니다. NSC Shenzhen은 열적 스윗 스팟 (thermal sweet spot)에 진입하기 위해 명확히 칩의 속도를 늦추었으며, 이를 슈퍼컴퓨터의 규모(volume)로 만회하여 대규모로 확장된 HPC 및 AI 워크로드에서 와트당 성능 (performance per watt)을 높였습니다.
이는 GPU 진영에서 뭐라고 말하든 간에 훌륭한 절충안 (tradeoff)입니다. 또한 7나노미터 공정에 머물러 있다면 반드시 선택해야 하는 방식이기도 합니다.
논문에는 LX2가 8개의 HBM 스택 (stacks)을 갖추고 있다고 되어 있지만, 분명히 16개를 가지고 있으며 칩렛당 8개의 스택을 의미했을 것입니다. 각 HBM 스택은 각 칩렛의 24개 LX2 코어 블록에 할당됩니다. 논문의 내용과는 달리, 칩렛당 32 GB의 메모리와 4 TB/sec의 대역폭 (bandwidth)을 가져야 하며, 결과적으로 소켓당 총 64 GB의 HBM과 8 TB/sec의 대역폭을 갖게 됩니다. 만약 이것이 사실이라면, 이는 아마도 약간 개량된 변형 버전의 HBM2E 메모리일 것입니다.
LX2가 지원하는 DRAM 메모리의 경우, 용량은 알 수 없으나 NSC Shenzhen이 커스텀 DRAM 로직 웨이퍼를 사용한 3D 적층 (3D stacking) 기술을 통해 이를 LX2 패키지에 배치하고 있다는 점은 확인되었습니다. 구체적인 위치나 방식은 명확하지 않지만, 저는 이 DRAM이 작년 말 ChangXin Memory Technologies가 10.7 GHz로 구동하며 선보였던 LPDDR5X 메모리를 사용하여 제작되었을 것이라고 강력하게 추측합니다. 하지만 이는 단지 추측일 뿐입니다. 확실한 것은 각 소켓이 64 GB의 HBM 메모리 외에도 256 GB의 DRAM을 보유하고 있다는 점입니다. 이 DRAM 메모리는 두 개의 컴퓨팅 칩렛 (compute chiplets)에 걸쳐 8개의 NUMA 도메인으로 구성되며, SDMA 엔진이 두 종류의 메모리 간 데이터 이동을 자동으로 관리합니다.
위 차트의 오른쪽을 보면, 코어 타일 (core tiles) 위에 8개의 DRAM 타일과 4개의 I/O 다이 (I/O dies)가 적층되어 있으며, 진한 파란색 IP 블록으로 표시된 인터커넥트 (interconnect)가 이들을 서로 연결하고 왼쪽과 오른쪽의 코어 패키지와 연결합니다.
위 차트의 분해도를 보면 SME 및 SVE2 유닛을 볼 수 있는데, 보시다시피 SME 유닛은 우리가 FP32 레지스터라고 추정하는 것으로 누적되는 2D 매트릭스 그리드 (2D matrix grid) 형태입니다. 이는 Huawei가 SME 설계를 커스텀 구현한 것으로 보입니다. SVE2 유닛은 Neoverse IP를 블록 복사한 것으로 보입니다.
다음은 SME 유닛의 사양과 HBM/LPDDR5X 메모리의 조정 사항입니다:

포괄적으로 — 사실 너무 포괄적이지만 — LX2 칩을 설명하는 AI 논문에 따르면, 이 칩은 SME 및 SVE 유닛을 통해 FP64/FP32/FP16/INT8을 지원하며, FP64 정밀도에서 최대 60.3 teraflops, FP32 정밀도에서 최대 120.6 teraflops를 제공한다고 합니다. 이것이 SME 유닛에서 나오는 것인지 아니면 SVE 유닛에서 나오는 것인지는 알려주지 않으며, 이를 파악하는 데 도움이 될 수 있는 더 낮은 정밀도인 FP16 및 INT8 성능에 대해서도 명시하지 않았습니다.
LineShine 시스템의 구성은 다음과 같습니다:

각 LineShine 노드는 2소켓 (two-socket) LX2 서버로 구성되어 있는데, 이는 흥미로운 선택입니다. 하나의 LineShine 블레이드 (blade)에는 이러한 2소켓 노드가 8개 탑재되며, LineShine 프레임 (frame)은 16개의 블레이드를 하나의 박스에 집약합니다. 이 프레임은 PCI-Express 5.0 연결을 사용하여 블레이드 내의 노드들을 서로 결합하고, 스위치 (switches)를 사용하여 프레임 내부의 16개 블레이드를 서로 연결합니다. (이는 비용 효율적인 방식입니다.) 이렇게 하면 256개의 LX2 CPU로 구성된 연산 도메인 (compute domain)을 확보할 수 있습니다.
LineShine 캐비닛 (cabinet)은 NSC Shenzhen이 프레임이라 부르는 이러한 블레이드 서버 2개를 포함하며, FP64 정밀도에서 30.87 페타플롭스 (petaflops)의 성능을 낼 수 있도록 설계되었습니다.
더 확장하기 위해, 프레임들은 독자적인 인터커넥트 (interconnect)를 사용하는데, 이는 이더넷 (Ethernet)의 변형이거나 InfiniBand의 파생형인 LingQi라고 상당히 확신합니다. 이 인터커넥트는 듀얼 플레인 (dual-plane), 멀티 레일 (multi-rail), 패트리 (fat-tree) 토폴로지로 구현되어 노드당 1.6 Tb/sec의 대역폭 (bandwidth)을 제공합니다. (이는 LX2 컴퓨팅 엔진 패키지 내부에 구현된 네트워크 인터페이스 카드 (network interface card)에서 각각 400 Gb/sec로 작동하는 두 개의 포트를 의미합니다.)
AI 자동 생성 콘텐츠
본 콘텐츠는 The Next Platform의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기