여러분, MiniMax M3가 곧 출시됩니다~~~
요약
MiniMax가 차세대 모델 M3의 출시를 예고하며 GQA 기반의 동적 블록 희소 어텐션 아키텍처를 공개했습니다. 이 기술을 통해 100만 토큰 컨텍스트 환경에서 프리필 속도는 9.7배, 디코딩 속도는 15.6배 향상되었습니다.
핵심 포인트
- GQA 기반 동적 블록 희소 어텐션 아키텍처 도입
- 1M 토큰 컨텍스트에서 압도적인 속도 향상 달성
- 긴 컨텍스트를 활용한 에이전트 작업의 효율성 극대화
- 비용 효율적인 롱 컨텍스트 처리 기술 확보
여러분, MiniMax M3가 곧 출시됩니다~~~
MiniMax AI 엔지니어링 리드(engineering lead) Skyler Miao는 오늘 단 한 문장만을 게시했습니다: "Something BIG is coming."
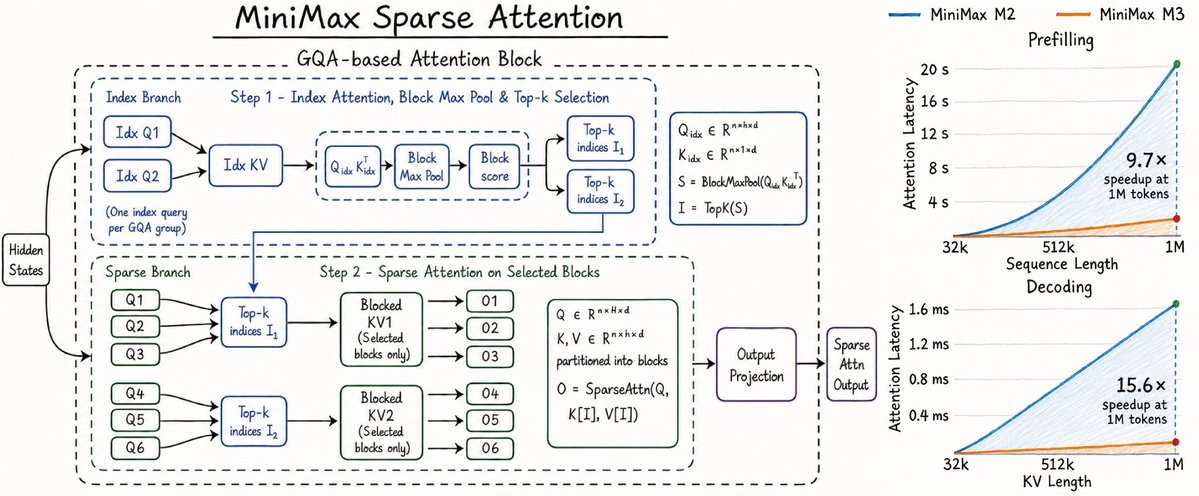
함께 게시된 이미지에는 M3 모델의 핵심 아키텍처(architecture)가 숨겨져 있습니다: GQA(Grouped Query Attention) 기반의 동적 블록 희소 어텐션(dynamic block sparse attention)입니다.
이 모델은 먼저 경량 인덱싱 브랜치(indexing branch)를 사용하여 전체 컨텍스트(context)를 빠르게 스캔하고, 가장 관련성이 높은 토큰 블록을 선택한 다음, 해당 블록에 대해서만 진정한 희소 어텐션(Sparse Attention)을 수행합니다.
그 결과, 1M(100만) 토큰 컨텍스트에서 프리필(Prefill) 속도는 M2보다 9.7배 빠르며, 디코딩(decoding) 속도는 15.6배 더 빠릅니다.
과거에는 모두가 긴 컨텍스트(long contexts)를 위해 경쟁하며 천문학적인 수치의 컴퓨팅 비용을 지불해야 했습니다. 이제 MiniMax는 이 한계에 직접 구멍을 뚫어, 백만 토큰 수준의 에이전트(Agent) 작업을 진정으로 실행 가능하게 만들었습니다.
긴 컨텍스트(Long contexts)는 이제 단순히 "실행될 만큼 길다"는 수준을 넘어, 빠르고 비용 효율적이기까지 해지기 시작했습니다.
MiniMax M3가 출시되면, DeepSeek V4 외에도 1M 컨텍스트를 진정으로 마스터할 수 있는 또 다른 플레이어가 등장하게 됩니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 X @berryxia (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기