
에이전트와 애플리케이션 사이의 누락된 연결 고리
요약
대부분의 에이전트 도구가 서버 측에 국한되어 발생하는 클라이언트 환경과의 격차를 분석합니다. LangChain의 헤드리스 도구를 활용해 브라우저 API와 로컬 상태를 에이전트 루프에 통합하는 방법을 제시합니다.
핵심 포인트
- 기존 에이전트는 서버 중심이라 브라우저/디바이스 API 접근에 한계가 있음
- 헤드리스 도구는 클라이언트 측 기능을 에이전트의 일급 도구로 변환함
- 클라이언트 실행을 통해 UX 향상 및 데이터 개인정보 보호 강화 가능
- 로컬 상태와 디바이스 기능을 활용해 에이전트의 실행 환경을 확장함
핵심 요약 (Key Takeaways)
대부분의 에이전트 도구는 백엔드(Backend)만 볼 수 있습니다. 브라우저, 앱, 디바이스에는 전통적인 서버 측 도구가 직접 접근할 수 없는 가치 있는 상태(State)와 기능(Capabilities)이 포함되어 있습니다.
헤드리스(Headless) 도구는 클라이언트 측 기능을 에이전트 루프(Agent loop)로 가져옵니다. 에이전트는 구조화된 입력과 출력을 유지하면서 브라우저 API, 로컬 메모리, 애플리케이션 특정 동작을 일급 도구(First-class tools)로서 호출할 수 있습니다.
실행을 클라이언트에서 유지하면 UX와 개인정보 보호가 모두 향상됩니다. 에이전트는 사용자의 환경과 직접 상호작용하여 왕복 시간(Round trips)을 줄이고, 민감한 데이터가 기본적으로 로컬에 머물 수 있도록 합니다.
요약(TL;DR): 대부분의 에이전트 도구는 서버에서 실행됩니다. 이는 에이전트가 API를 호출할 수는 있지만, 사용자가 실제로 작업하는 브라우저, 앱 상태 또는 디바이스 기능과는 상호작용할 수 없음을 의미합니다. LangChain의 헤드리스 도구를 통해 우리는 에이전트가 지리 위치(Geolocation), 클립보드 액세스, 로컬 메모리 및 앱 내 동작과 같은 클라이언트 측 기능을 일급 도구로 호출할 수 있게 함으로써 이 격차를 해소합니다. 이를 통해 에이전트는 더욱 유용해지고, 더 프라이빗해지며, 실제 애플리케이션 동작과 더 잘 정렬됩니다.
오늘날의 에이전트는 점점 더 유능해지고 있지만, 사용자가 중요하게 생각하는 많은 기능은 서버가 아닌 클라이언트 런타임(Client runtime)에 존재합니다. 브라우저와 애플리케이션은 로컬 상태(Local state), 사용자 선택 사항, 디바이스 API 및 백엔드 시스템을 통해서는 종종 사용할 수 없는 애플리케이션 특정 동작 등을 소유하고 있습니다. 그 결과, 에이전트는 다음에 무엇이 일어나야 하는지에 대해 추론할 수는 있지만, 사용자가 실제로 작업하고 있는 환경에서 행동하는 데에는 여전히 어려움을 겪습니다.
이러한 격차가 발생하는 한 가지 이유는 대부분의 에이전트 도구가 서버에서 실행되기 때문입니다. 모델이 도구를 사용하기로 결정하면, 에이전트는 이를 프로세스 내에서 실행하거나 MCP 서버와 같은 외부 서비스에 위임한 다음, 그 결과를 추론 루프(Reasoning loop)로 다시 전달합니다. 이는 API, 데이터베이스 및 백엔드 시스템에는 잘 작동하지만, 다음과 같은 명확한 한계가 있습니다:
- 브라우저 전용 또는 디바이스 전용 API에 직접 접근할 수 없습니다.
- 서버로 동기화되지 않은 프론트엔드 상태 (frontend state)에 작용할 수 없습니다.
- 개인정보에 민감한 데이터를 디바이스 외부로 유출하도록 강제하는 경우가 많습니다.
- 본질적으로 로컬에서 이루어져야 하는 동작에 대해 불필요한 왕복 (round trips)을 발생시킵니다.
브라우저는 많은 고가치 에이전트 동작이 실제로 일어나는 곳입니다. 즉, 로컬 애플리케이션 상태를 읽고, 현재 UI에 작용하며, 데이터를 백엔드로 먼저 전송하지 않고도 디바이스 기능을 사용하는 곳입니다. 데스크톱 앱 또한 로컬 파일, 네이티브 통합, 세션별 상태를 통해 동일한 패턴을 노출합니다. 만약 에이전트가 해당 런타임 (runtime)에 도달할 수 없다면, 백엔드 워크플로우에는 능숙할지 몰라도 사용자가 실제로 경험하는 상호작용에는 취약한 상태로 남게 됩니다.
Figma, Google Slides, 또는 리치 텍스트 에디터 (rich-text editor)를 위한 사이드카 에이전트 (sidecar agent)를 구축한다고 가정해 봅시다. 에이전트는 서버에서 사용자의 요청을 추론할 수 있지만, 문서 모델 (document model), 선택 상태 (selection state), 편집 명령은 모두 클라이언트 (client)에 존재합니다. 서버 측 도구는 커서 위치에 텍스트를 삽입하거나, 선택된 객체의 형식을 재설정하거나, 활성화된 슬라이드로 이동할 수 없습니다. 이러한 동작은 백엔드 API가 아닌 애플리케이션 런타임에 속하기 때문입니다. 오늘날 팀들은 보통 임시 UI 브릿지 (ad-hoc UI bridge)를 통해 이를 해결합니다. 즉, 일부 클라이언트 상태를 서버로 직렬화 (serialize)하고, 응답을 받은 다음, 클라이언트에 명령형으로 패치 (imperatively patch)하는 방식입니다. 작동은 하지만, 이는 취약하고, 조합하기 어려우며, 모델의 추론 루프 (reasoning loop)에는 보이지 않습니다.
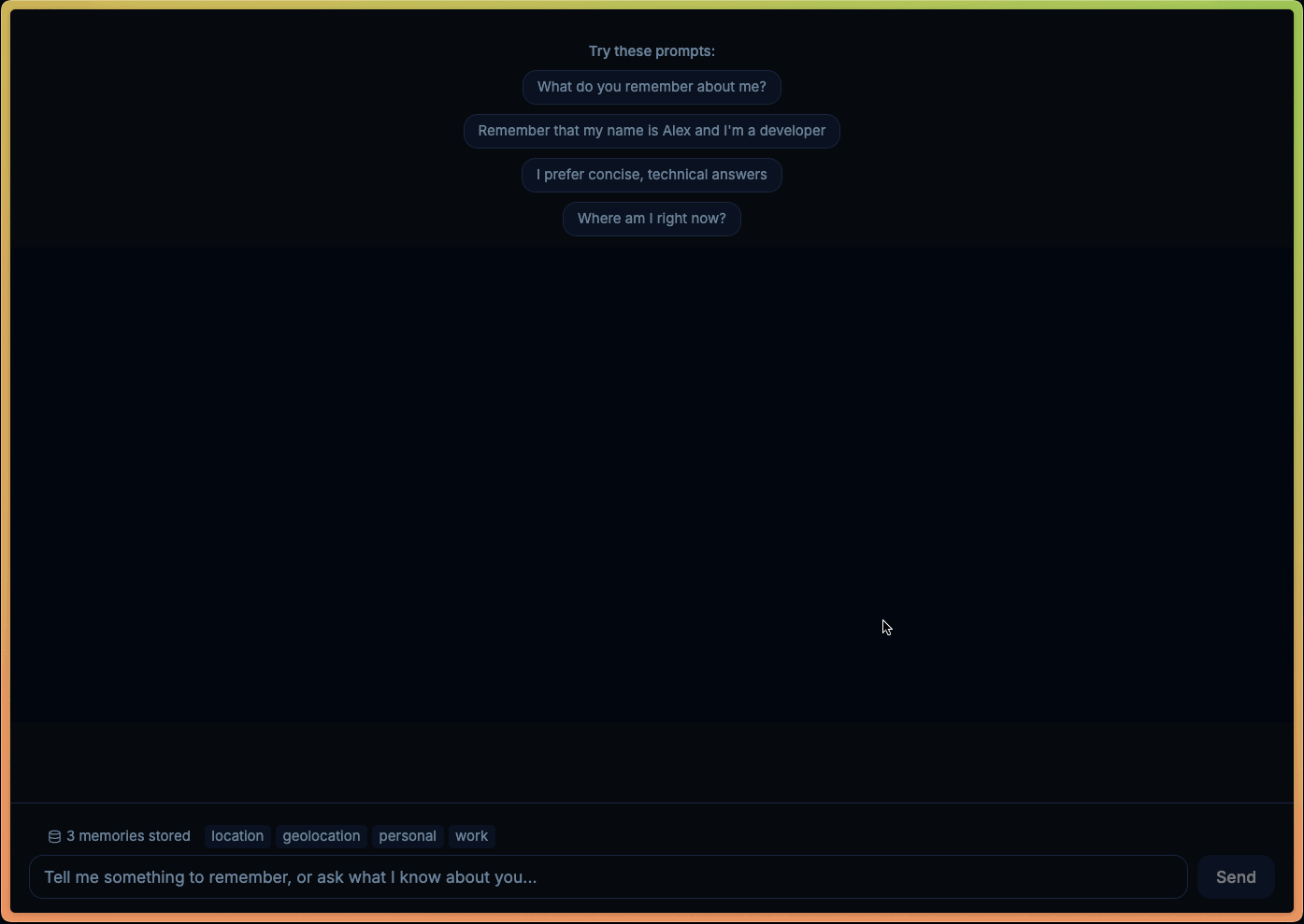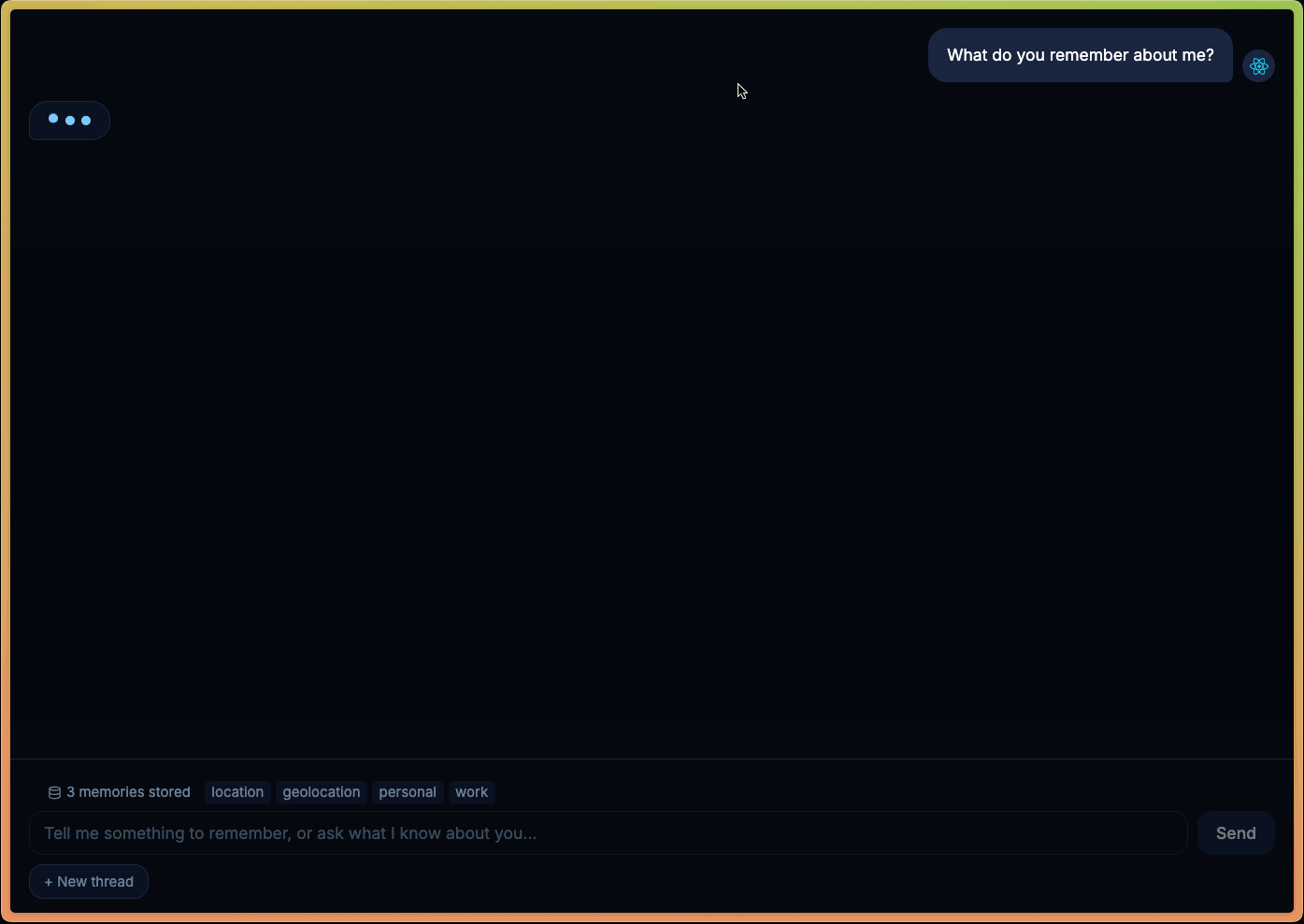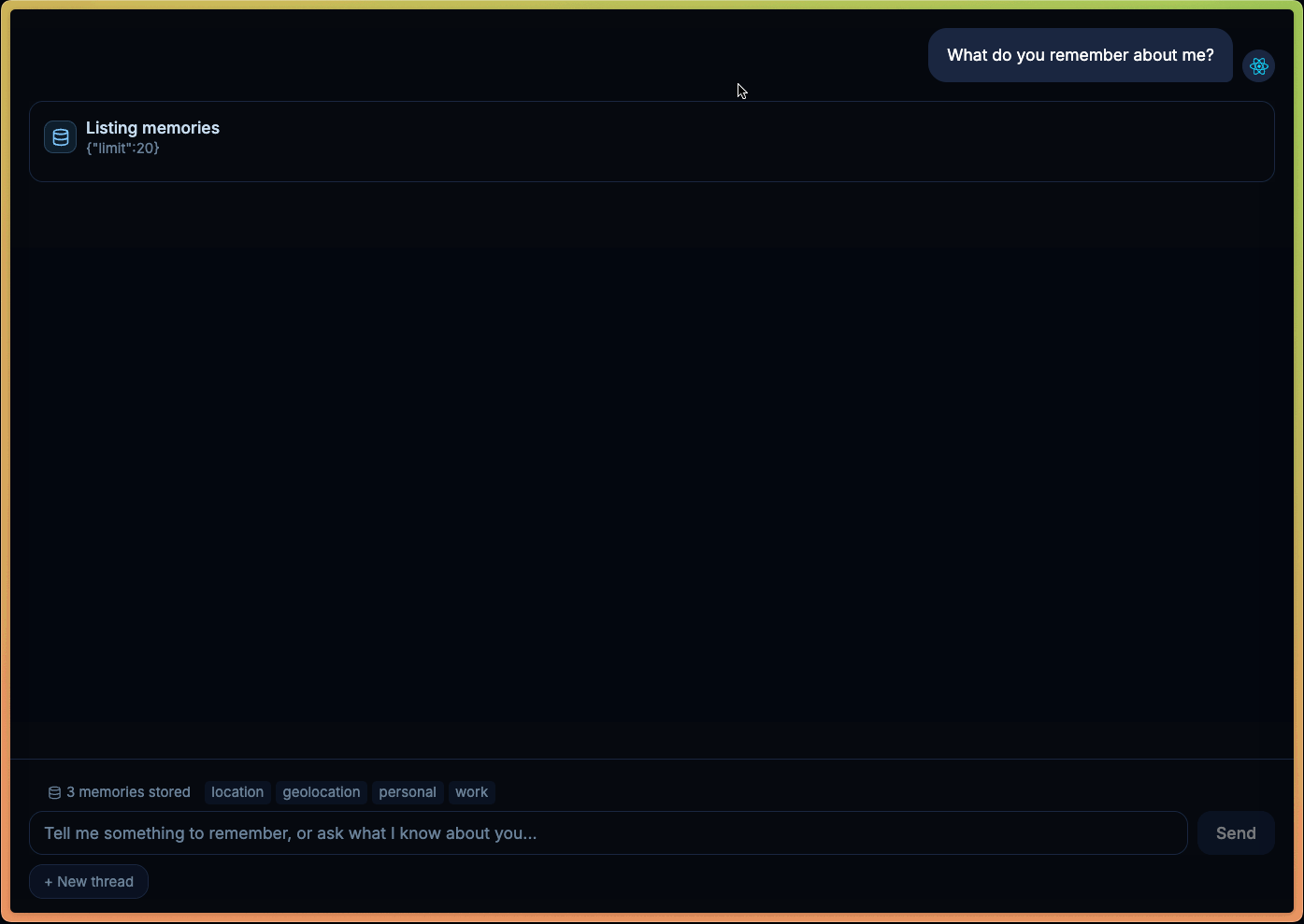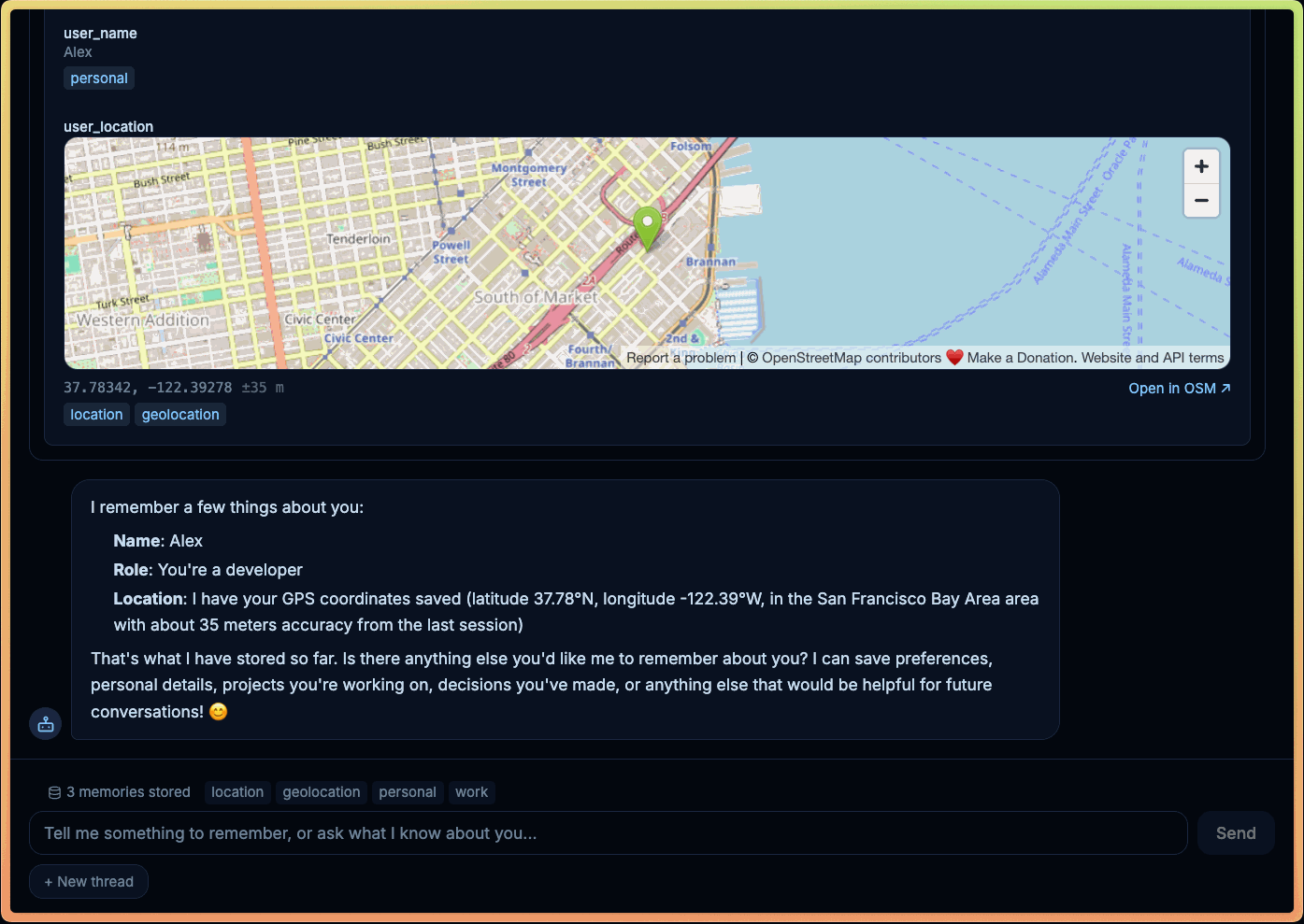
에이전트가 사용자의 브라우저에서 메모리나 지리 위치 API (geolocation API)에 직접 접근할 수 있도록 하세요.
이것이 바로 LangChain에서 헤드리스 도구 (headless tools)가 해결하는 문제입니다.
헤드리스 도구가 변화시키는 것
헤드리스 도구는 모델에게 다른 도구와 똑같이 보입니다. 이름, 설명, 그리고 예상되는 입력 세트를 가지고 있습니다. 모델은 다른 도구와 마찬가지로 언제 이 도구를 호출할지 결정합니다. 차이점은 그 다음에 어떤 일이 일어나는가에 있습니다.
서버가 도구를 직접 실행하는 대신, 도구 호출(tool call)을 클라이언트, 즉 사용자의 브라우저, 데스크톱 앱 또는 실제로 해당 기능을 수행할 수 있는 환경으로 전송합니다. 클라이언트는 도구를 로컬에서 실행하고 결과를 다시 전송하며, 에이전트는 중단되었던 지점부터 다시 작업을 이어갑니다.

처음에는 이것이 사소한 구현 세부 사항처럼 들릴 수 있지만, 실제로 이는 에이전트가 어떤 종류의 시스템을 안정적으로 제어할 수 있는지를 변화시킵니다.
모델은 도구가 어디에서 실행되는지 알 필요가 전혀 없습니다. 모델은 도구를 보고, 사용하기로 결정하며, 결과를 받습니다. 하지만 보이지 않는 곳에서는 서버와 클라이언트가 협력하고 있습니다. 서버는 에이전트가 *무엇(what)*을 하고 싶은지 알고, 클라이언트는 그것을 어떻게(how) 수행하는지 압니다. 이러한 분리가 핵심 아이디어입니다.
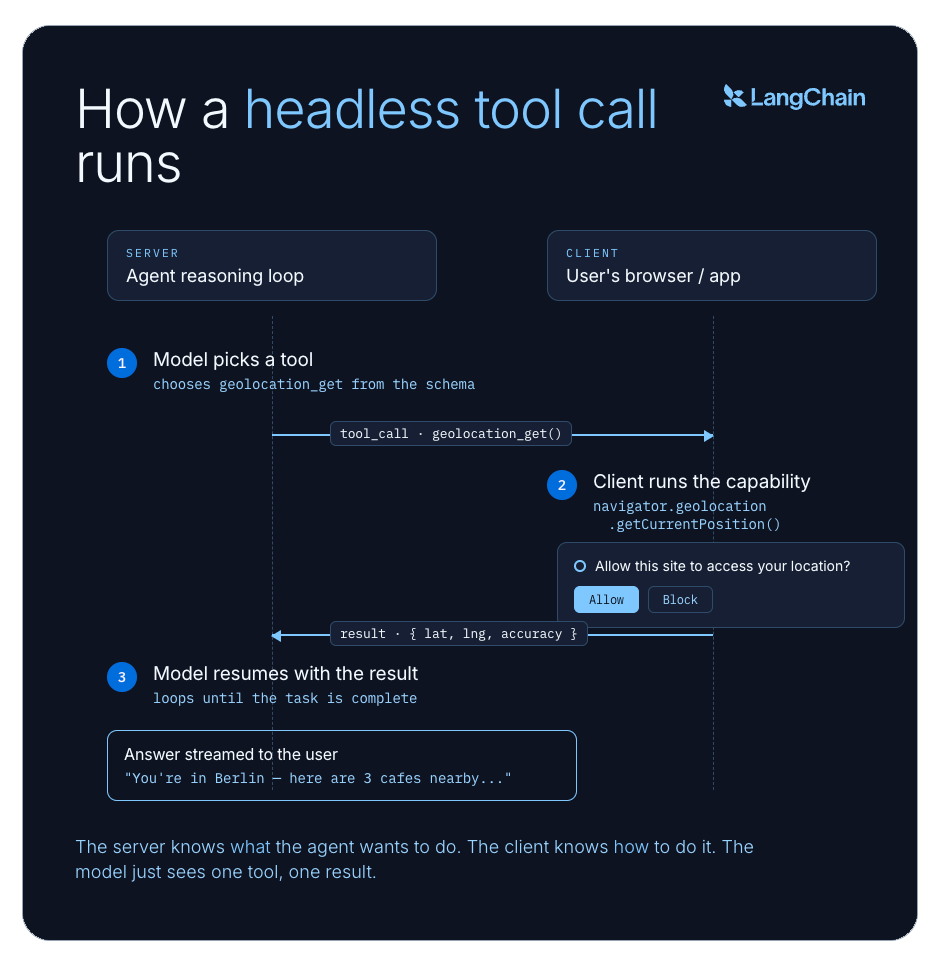
이 과정을 수동으로 연결할 수도 있습니다. 예를 들어 React 앱에서 navigator.geolocation.getCurrentPosition()을 호출하고 그 결과를 에이전트에 보내는 방식입니다. 하지만 이 경우 모델은 해당 기능을 언제 호출할지 스스로 발견하거나 결정할 방법이 없습니다. 이는 추론 루프(reasoning loop) 외부에서 임시적인 사이드 채널(side channel)로 존재하게 됩니다. 헤드리스 도구(Headless tools)는 클라이언트 측 동작을 에이전트의 옆에 두는 것이 아니라, 에이전트의 추론 루프 내부로 집어넣습니다.
이것이 중요한 이유
이점은 단순히 "브라우저 접근"에 그치지 않습니다. 에이전트가 슬라이드 덱 작업을 돕는 상황을 상상해 보세요. 에이전트는 전체 세션을 백엔드로 전송하지 않고도, 활성화된 슬라이드로 이동하고, 로컬 컨텍스트를 읽고, 프레젠테이션을 그 자리에서 업데이트할 수 있어야 합니다. 헤드리스 도구는 클라이언트 측 기능을 에이전트 루프 내부의 실제 도구로 노출함으로써 이러한 종류의 상호작용을 가능하게 합니다.
어떤 작업들은 백엔드에서 올바르게 에뮬레이션(emulate)하는 것이 불가능합니다. 지리적 위치(Geolocation)가 명백한 예입니다. 권한 프롬프트와 장치 신호는 브라우저가 제어합니다. 클립보드 접근, 캔버스 렌더링(canvas rendering), 파일 피커(file pickers), 그리고 실시간 UI 탐색 모두 활성화된 클라이언트 환경에 의존합니다. 표준 도구는 백엔드 서비스를 통해 이를 근사치로 구현할 수 있지만, 헤드리스 도구는 실제 기능을 직접 호출할 수 있습니다.

하지만 헤드리스 도구 (headless tools)는 단순히 브라우저 API만을 위한 것이 아닙니다. 이는 에이전트 (agents)에게 애플리케이션 네이티브 액션 (application-native actions)에 대한 안전한 접근 권한을 부여하기 위한 일반적인 메커니즘입니다. 예를 들어, 인기 있는 Slidev 프레젠테이션 프레임워크의 플러그인인 slidev-agent는 헤드리스 도구를 사용하여 사용자의 활성 프레젠테이션 내 특정 슬라이드로 이동합니다. 이는 데이터 검색 문제나 서버 자동화 문제가 아닙니다.
이 패턴은 프라이버시 트레이드오프 (privacy tradeoffs) 또한 변화시킵니다. 에이전트 메모리 (agent memory)가 항상 중앙 집중식 백엔드에 속해야 하는 것은 아닙니다. IndexedDB와 같은 브라우저 스토리지 (browser storage)를 기반으로 하는 헤드리스 도구를 사용하면, 회상 (recall)을 서버 측 데이터 관리 문제로 만들지 않고도 메모리를 기본적으로 로컬에 유지할 수 있습니다. 즉, 내구성이 있고 지연 시간이 낮으며, 자연스럽게 해당 사용자 및 브라우저로 범위가 제한됩니다.
코드에서의 작동 방식
TypeScript에서는 정의와 구현 사이의 분리가 특히 깔끔합니다. 도구를 한 번 정의하고, .implement(...)를 통해 구현을 부착한 다음, 프론트엔드 스트리밍 훅 (frontend streaming hook)에 구현을 전달합니다. 서버와 클라이언트는 동일한 스키마 (schema)를 공유하지만, 브라우저 특화 실행 로직은 클라이언트만 로드합니다.
// tools.ts
import { tool } from "langchain";
export const geolocationGet = tool({
...
// App.tsx
import { useStream } from '@langchain/react';
// shared tools definition
...
브라우저 로컬 메모리를 지리 위치 정보 (geolocation) 및 선택적 인간 승인 (human approval)과 결합한 라이브 데모를 LangChain 문서에서 확인해 보세요.
요약
표준 도구는 에이전트에게 백엔드 시스템에 대한 접근 권한을 부여했습니다. 헤드리스 도구는 에이전트에게 사용자가 실제로 작업하는 곳에 대한 접근 권한을 부여합니다.
사용자는 여러분의 백엔드에 살지 않습니다. 사용자는 브라우저, 앱, 그리고 가장 가치 있는 에이전트 상호작용이 발생하는 수많은 디바이스에 살고 있습니다. 헤드리스 도구는 타입이 지정된 스키마 (typed schemas), 명시적 기능 (explicit capabilities), 구조화된 출력 (structured outputs), 그리고 검토 가능성 (reviewability)을 보존하면서 이러한 상호작용을 가능하게 하여, 에이전트가 단순히 서버에 편리한 도구가 아닌 사용자에게 네이티브한 도구를 사용할 수 있도록 합니다.
LangChain Python 또는 LangChain JS에서 헤드리스 도구를 시작해 보세요.
사려 깊은 검토와 피드백을 주신 @huntlovell, @colifran_, @sydneyrunkle 님께 감사드립니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기