알아차리기 전에 고쳐지고, 고칠 때마다 강해진다 ── Self-Healing과 재발 방지 메커니즘 (연재 Part 4)
요약
운영 중 발생하는 장애를 AI가 스스로 감지하고 수정 PR 생성부터 배포까지 완결하는 Self-Healing 메커니즘을 소개합니다. 단순 수복을 넘어 재발 방지를 위한 lint 및 타입 게이트를 자동으로 추가하여 시스템의 가드레일을 강화하는 전략을 다룹니다.
핵심 포인트
- AI가 알람 조사, 코드 수정, PR 기안, 배포를 자동 수행
- Self-Healing과 재발 방지(Lint/Type Gate)의 결합 강조
- 운영 이상을 사람이 인지하기 전 AI가 선제적 대응
- 반복되는 장애를 구조적으로 제거하는 Recurrence 루프 활용
여러분 안녕하세요! AirCloset에서 CTO를 맡고 있는 츠지입니다.
Part 3에서는 「AI가 작성한 코드는 AI가 본다」 ── 자동 리뷰 파이프라인으로 PR 시점의 품질을 지키는 이야기에 대해 썼습니다.
이번에는 운영 시점의 품질을 지키는 측면인 **Self-Healing (자기 수복)**입니다. 운영 알람(Alert)을 AI가 조사하여 수정 PR을 기안하고, 자동 리뷰에 태워 자동 머지(Merge), 자동 재배포(Redeploy)까지 완결시키는 메커니즘입니다. 그리고 그 수정 PR에는 재발 방지를 위한 lint/타입 게이트(Type Gate) 추가가 필수화되어 있어, 결과적으로 가드레일(Guardrail)이 매일 자동으로 늘어납니다.
「장애가 자동으로 고쳐진다」라고만 하면 화려하고 눈길을 끌겠지만, 아마 그것만으로는 중장기적으로 승리할 수 없습니다. 고치는 김에 동일한 함정의 재발을 구조적으로 없앤다 ── 「자기 수복」 + 「자기 강화」의 두 가지가 결합되어야 비로소 품질 게이트는 시간과 함께 성장해 나갑니다.
갑자기 한 달 치 수치부터
최근 30일 동안 머지된 Self-Healing PR: 115건.
거의 전부 사람의 개입 없이 merge + deploy 완료.
사람의 대응은 「AI가 손을 댈 수 없다고 판단한 케이스만」.
이것이 cortex의 「장애 대응」 현황입니다.
여기서 「115건 = 사용자에게 영향이 있는 장애」라고 읽지는 말아 주세요. 내역은 대략 다음과 같습니다:
약 절반(54건)이 Deploy Failed 계열 ── CI/Pulumi 배포 단계에서 실패를 감지하여, 운영 환경에 나가기 전에 AI가 처리한 것. 이 부분은 최근 [Recurrence] 루프(후술)로 대책이 쌓여오고 있어, 체감상 감소 추세입니다.
나머지 61건이 운영 런타임(Runtime) 계열 (Service Error Log Detected / Pipeline Failure / Generator Failure 등) ── 운영 환경에서 실행 중이지만, 에러 로그 임계치나 연속 실패 임계치를 넘은 단계에서 발화하는 유형의 알람. 사용자에게 영향이 미치기 전에 AI가 처리한 것.
즉 「장애 대응」이라기보다는 「모니터링으로 포착한 운영 이상을, 사람이 인지하기 전에 AI가 115번 고쳤다」가 정확합니다. 실제로 사람이 인지하는 인시던트(Incident)는 월 몇 건 수준으로 압축됩니다.
덧붙여, 동일한 서비스(예: gcs-transformer가 61건 중 25건)에서 반복적으로 발화하는 케이스가 눈에 띕니다 ── 이것이 바로 뒷부분에서 설명할 [Recurrence] 루프로 lint/타입 게이트화하여 구조적으로 없애 나갈 대상이 된다는 것이 본 기사의 후반부 이야기입니다.
또 하나 솔직한 이야기를 하자면, **최근 1개월의 수치는 다소 상향 편향(Upward spike)**되어 있습니다. 원래 코드베이스 내에 「에러를 catch로 뭉개고 아무것도 알리지 않는」 사이런트 캐치(Silent catch)가 많이 존재했는데, no-silent-catch lint 규칙을 추가하여 기존의 silent catch를 순차적으로 없앤 결과, 그때까지 숨어 있던 운영 장애가 알람으로서 표면 위로 드러나게 된 측면이 있습니다. 「모니터링이 가시화된」 만큼의 스파이크이므로, [Recurrence] 루프로 대응 및 lint화가 진행되면 수치는 수렴할 전망입니다. 「보이지 않던 것이 보이게 된 것」은 품질 측면에서 오히려 전진이며, 지금 일어나고 있는 것은 그 catch-up 페이스입니다.
한 단계 더 보충하자면, 이것을 인간이 수동으로 처리하는 것은 현실적으로 불가능합니다. 115회 분량의 「알람 확인 → 로그 조사 → 컨텍스트 스위칭(Context Switch) → 코드 파악 → 수정 → PR 기안 → 리뷰 → 배포」를 돌린다면 개발 팀의 가용 시간은 붕괴할 것입니다. 시스템이 태연하게 무인으로 처리하고, 심지어 수정과 동시에 lint/CI guard로 변환하고 있다 ── 이 점이 본 기사의 주제입니다.
알람이 발화한 순간 AI가 조사를 시작하여, Loki / Product Graph / git blame을 따라 근본 원인을 특정하고, 수정 PR을 기안하여 Part 3의 자동 리뷰에 태우고, APPROVE → 자동 머지 → 자동 재배포로 한 바퀴를 돕니다.
연재 목록
| # | 테마 | 키 씬(Key Scene) | 기사 |
|---|---|---|---|
| 1 | 총론: cortex의 하네스(Harness) | PR이 무인 머지됨 / 장애를 알아차리기 전에 고쳐짐 | ai-harness-intro |
| ... |
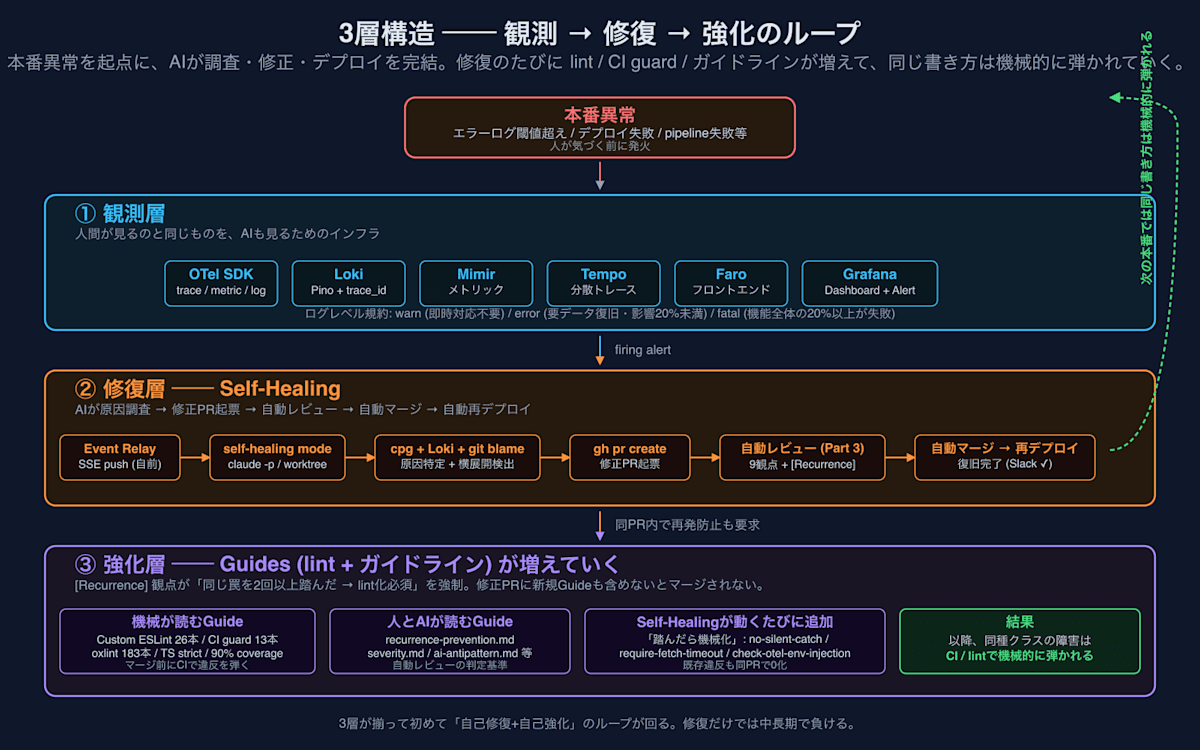
전체상 ── 「관측」 「수복」 「강화」의 3층 구조
Self-Healing을 작동시키기 위해서는 그 앞단에 제대로 된 **관측층 (Observation Layer)**이 필요하며, 그 뒷단에는 **강화층 (Reinforcement Layer, 재발 방지)**이 필요합니다. Self-Healing 자체는 중간의 **수복층 (Repair Layer)**에 위치하며, 이 3개 층이 갖춰져야 비로소 「자기 수복 + 자기 강화」의 루프가 돌아갑니다.
| 층 | 역할 | 주요 구성 요소 |
|---|---|---|
| 관측 | 운영 환경의 이상을 실시간으로 탐지 | OTel SDK / Loki / Mimir / Tempo / Faro / Pino logs with trace_id |
| 수복 | AI가 알람을 수신하여 원인 조사 → 수정 PR 생성 → 자동 리뷰 → 자동 머지 → 자동 재배포 | Event Relay → SSE → self-healing 모드 스크립트 → claude -p (worktree) → gh pr create |
| 강화 | 수정 PR에 신규 가이드(lint / CI guard / 가이드라인) 추가를 필수화하여, 동일한 종류의 알람이 다시는 발생하지 않도록 구조화 | @cortex/eslint-plugin-graph (26개), scripts/check-*.ts (13개), recurrence-prevention.md, 자동 리뷰의 [Recurrence] 관점 |
순서대로 분해해 보겠습니다.
관측층 ── 알람은 어디서 오는가
cortex의 운영 환경 observability(관측 가능성)는 Grafana Cloud + OpenTelemetry로 구성되어 있습니다.
- OTel SDK (
@cortex/otel공통 패키지) ── 각 서비스의 엔트리 포인트(Entry Point) 시작 부분에서initOtel({ serviceName })을 호출. trace / metric / log를 OTLP로 Grafana Cloud에 전송 - Loki (로그) ── Pino 구조화 로그에
trace_id를 자동 부여. trace ↔ log 상호 참조 가능 - Mimir (메트릭) ── Cloud Run / pipeline / Gemini API 토큰 사용량 등
- Tempo (트레이스) ── 분산 트레이싱 (Distributed Tracing)
- Faro (프론트엔드) ── 브라우저의 JS 에러 / 퍼포formance / 네트워크 실패를 포착
- Grafana ── 대시보드 + Alert Rules + Notification Policy
또한, Pino의 구조화 로그는 로그 레벨의 정의를 비즈니스 임팩트(Business Impact) 축으로 규약화하고 있습니다:
| 레벨 | 정의 | 예 |
|---|---|---|
warn | 업무상 예견될 수 있으나, 즉각적인 문제는 되지 않음 (재시도(Retry)를 통해 자연 회복될 것으로 예상) | 검색 쿼리 결과 0건, 임의 필드 미설정, Rate Limit으로 인한 단시간 retry |
error | 확실히 사후 데이터 복구/재실행이 필요함. 영향 범위는 20% 미만으로 예상 | 있어야 할 user 레코드를 찾을 수 없음, BigQuery insert 실패, 개별 레코드의 enrichment 실패 |
fatal | 해당 기능 전체가 20% 이상 실패하는 상태. 서비스 지속 불가능 / 치명적인 설정 결여 / 의존 대상의 전체 단절 | OTel 초기화 실패, 기동 시 필수 secret 결여, Pipeline의 입력 데이터 소스 전체 단절 |
핵심은, NotFoundError와 같은 타입명이나 예외 클래스명으로 기계적으로 레벨을 결정하지 않는 것입니다. 똑같은 '레코드 없음'이라도, '반드시 존재해야 하는 레코드가 존재하지 않는 것'이라면 error / fatal로, '사용자 검색 결과가 0건인 것'이라면 warn으로 분류합니다. 「데이터 보정이 필요한가」 「기능 전체가 멈추는가」라는 비즈니스 임팩트로 레벨을 결정하는 규약이며, 이것이 모호하면 '모니터링 피로(Monitoring Fatigue)'와 '중대 장애 간과'가 동시에 발생합니다. Self-Healing이 반응하는 것은 주로 error 임계치를 넘었을 때이며, fatal은 수동 에스컬레이션(Escalation) 대상입니다.
Alert Rules는 Pulumi로 선언적(Declarative)으로 관리하고 있으며, 서비스별로 BOT / Pipeline / Transformer / Generator / Gemini / CI / Deploy / Service Catch-All 등의 카테고리로 규칙을 묶어 두었습니다. 새로운 서비스를 추가할 때도 인프라 코드에 규칙을 한 줄 추가하기만 하면 대시보드와 알람이 자동으로 생성되는 구성입니다.
여기까지가 "인간이 보는 것과 동일한 것을 AI도 본다"를 위한 인프라입니다. Self-Healing은 여기서 발생한 알람(Alert)을 전달받아 동작합니다.
Observability로 포착할 수 없는 것은 Self-Healing도 무력하다
솔직하게 말씀드리겠습니다. Self-Healing은 어디까지나 관측층(Observability layer)이 이상으로 감지할 수 있는 것에만 반응할 수 있습니다. Observability가 생명이라는 말은 바로 이 지점과 직결됩니다.
현재 cortex의 관측 스택(Observability stack)에서 수집하고 있는 것은 대략 "로직 레벨의 에러 (Logic-level error)" ── 예외(Exception), 에러 로그, 배포 실패, 외부 API 호출 에러, 임계치 기반 메트릭 이상 ── 가 중심입니다.
반대로, 현재 구성에서는 포착하지 못하고 있는 영역이 있습니다:
UI 에러 ── 로직은 정상적으로 실행되어 에러 로그도 남지 않지만, 화면에 의도한 대로 표시되지 않거나 / 잘못된 값이 표시되는 클래스의 장애. Faro를 통해 클라이언트 측의 JS 예외나 네트워크 장애(Network failure)는 포착할 수 있지만, "로직은 통과했으나 결과가 의도와 다른 경우"는 알람이 되지 않습니다.
조용한 데이터 오염 (Silent data corruption) ── 집계값이 서서히 어긋나거나, 테이블에 부적절한 값이 들어가는 등의 현상. 임계치나 스키마(Schema) 위반으로 나타나지 않는 한 감지할 수 없습니다.
사용자 체감 품질 저하 ── 응답 속도가 느려지거나 UX가 이상해지는 등의 현상. SLO / 레이턴시(Latency) 임계치를 넘어서야 비로소 포착할 수 있습니다.
즉, Self-Healing은 "관측층이 포착할 수 있는 장애"를 AI로 대체하는 메커니즘이며, 관측층 자체의 포괄성(Comprehensiveness)이 전제 조건입니다. 관측의 빈틈은 자동 리뷰나 Self-Healing이 닿지 않는 사각지대로 그대로 남게 됩니다.
이는 Self-Healing의 한계라기보다 **"관측 스택을 키워나가는 것의 중요성"**이며, cortex에서도 지속적으로 투자하고 있는 영역입니다 (Part 1에서 기술한 "받쳐주는 기반층" 중 하나가 Observability입니다).
복구층 ── Self-Healing의 흐름
MODE=self-healing
으로 실행한 Part 3와 동일한 webhook-server 스크립트가, Grafana의 발화 중인 알람(Firing alert)을 받아 동작합니다.
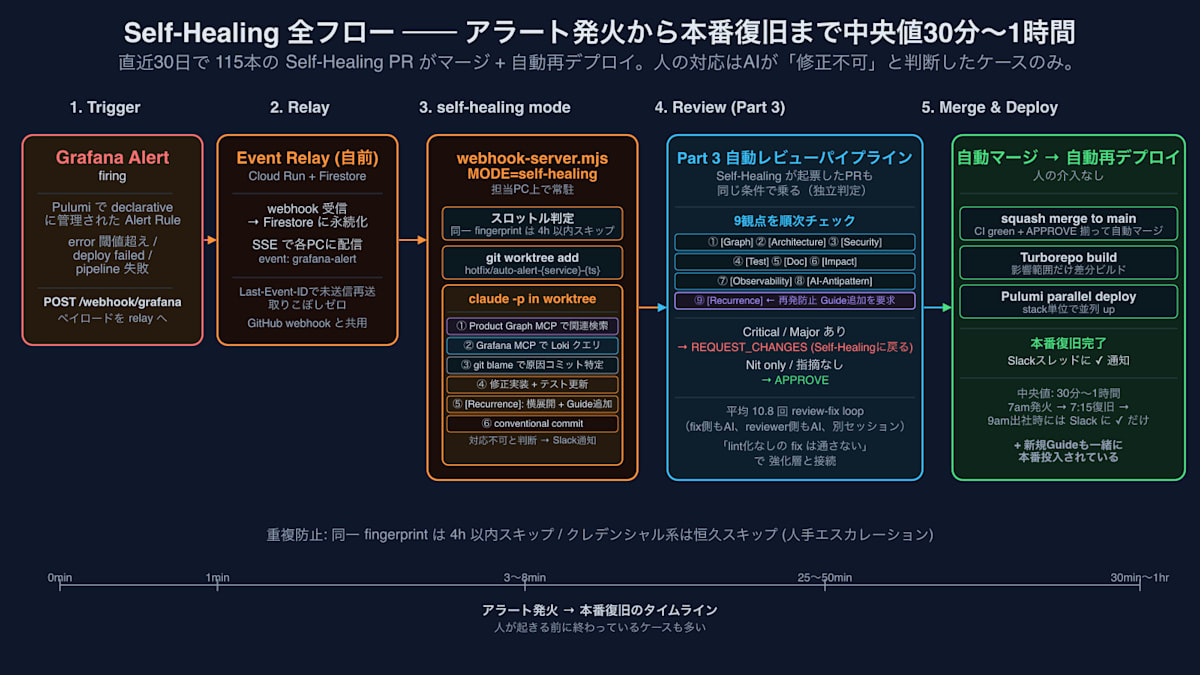
텍스트로 설명하면 다음과 같은 흐름입니다:
[Grafana Alert Rule firing]
↓ POST /webhook/grafana
[Event Relay (자체 제작)] ── Firestore에 영속화
...
AI가 "수정 불가"라고 판단하면 어떻게 되는가
모든 알람이 AI에 의해 수정 가능한 것은 아닙니다. 구현 단계에서는 "수정 불가능하다고 판단하면 아무것도 변경하지 않고 종료"라는 규칙을 적용했습니다. 이 경우 Slack 스레드에 "코드 수정으로는 대응할 수 없는 알람입니다. 조사 결과: ..."라는 형태로, AI가 무엇을 조사했는지에 대한 조사 결과와 함께 알림을 보냅니다.
참고로 서두에 언급한 "115건"은 PR(Pull Request)화 되어 merge 및 deploy 완료에 도달한 수이며, 이 "수정 불가능하여 종료"된 케이스는 별도의 집합으로서 월 몇 건 정도 발생하고 있습니다 (외부 서비스의 일시적 장애, 코드가 아닌 인프라 설정 문제, AI의 판단 부하가 너무 높은 케이스 등). "사람이 개입하여 대처하는 것"은 이 별도의 집합뿐이며, 115건 중 일부가 실패했다는 의미가 아니라는 점을 보충해 둡니다.
실제로 전달되는 Slack 메시지는 다음과 같은 수준입니다 (예시: styling-pattern-watch-transformer의 GitHub PAT 만료 케이스):
ℹ️ 코드 수정으로는 대응할 수 없는 알람입니다. 조사 결과:
조사 결과 요약: 최근 1시간 동안의 에러 로그를 Loki로 확인한 결과,
styling-pattern-watch-transformer의 현재 유일한 에러 요인은 GitHub PAT (Personal Access Token)의 만료 / 취소(Revoke)였습니다.
발견된 사실
- BQ snapshot pipeline은 정상 작동 중: 최근 7회 연속
[BQ] Snapshot rows inserted성공. 이전의 autodetect형 드리프트(Drift) 장애는 별도의 PR을 통해SAFE_CAST(... AS INT64)가 적용되어 해소됨. - 현재의 유일한 에러 (최근 1시간 이내, 다수 발생):
GithubUnauthorizedError: GitHub API /commits/master unauthorized (401): PAT가 만료/취소되었을 가능성이 높음
──/check-drift
핸들러가 Cloud Scheduler가 실행될 때마다 401 에러로 실패함
근본 원인은 해당 서비스의 Secret Manager에 저장된 GitHub Personal Access Token (PAT)이 만료(expired) 또는 취소(revoked)되었기 때문임. 코드 측에서는 401 에러를 전용 클래스인 GithubUnauthorizedError로 다시 던지며(re-throw), Slack에 "PAT 업데이트가 필요합니다"라는 알림도 이미 보낸 상태임. 코드 측의 탐지 및 알림 설계는 의도대로 동작함.
대응 방침: 변경 없이 종료. 이것은 외부 자격 증명(credential)의 운영 장애(PAT 만료)이며, 사람이 Secret Manager를 새로운 PAT로 업데이트해야 함. 코드 변경으로 해결할 수 있는 종류의 장애가 아니므로, 코드 변경, 커밋, PR(Pull Request) 생성은 수행하지 않고 종료함.
운영자(Operator)를 위한 액션:
- GCP Console / Secret Manager에서 대상 시크릿(secret)에 유효한 PAT(
repo권한, 대상 리포지토리에 대한 read 액세스)의 새 버전을 추가 - Cloud Run revision의 재배포는 불필요 (
secretKeyRef version:latest참조)
이 정도의 상세 수준으로 "무엇을 조사했는지, 왜 코드 변경으로 해결할 수 없는지, 사람은 무엇을 해야 하는지"가 모두 드러남. Slack 스레드가 열려 있으면 운영자는 즉시 대응에 들어갈 수 있으므로, 단순히 "알람만 전달되는 것"과는 생산성 면에서 차원이 다름.
중복 방지
동일한 fingerprint (Grafana 알람의 고유 식별자)에 대해서는 4시간 이내에는 재처리하지 않도록 스로틀(throttle)이 적용되어 있음. 이것이 없다면, 수정 PR이 머지(merge)되기 전에 동일한 알람이 재발화하여 → 별도의 worktree에서 별도의 수정 PR을 생성하는 → ... 식의 무한 루프에 빠지기 쉬움.
여기에 더해, alertname에 "クレデンシャル(credential)", "credential"을 포함하는 항목은 **영구 스킵(permanent skip)**함. 자격 증명 관련 사항은 AI가 다룰 경우 유출 리스크가 있으므로, 명시적으로 사람에게 에스컬레이션(escalate)하도록 설계됨.
Self-Healing과 Part 3 자동 리뷰의 관계 ── 「수정 AI」와 「심사 AI」의 독립
이 부분은 에이전트 설계로서 가장 효과적인 부분이기에 강조해 두겠음.
Self-Healing이 생성하는 PR은 특별한 PR이 아니라, 일반적인 fix PR임. Part 3의 자동 리뷰 파이프라인에 동일한 조건으로 올라감. 9가지 관점 (Graph / Architecture / Security / Test / Doc / Impact / Observability / AI-Antipattern / Recurrence)을 순차적으로 체크하며, Critical / Major 항목이 있으면 REQUEST_CHANGES, Nit only / 지적 사항 없음 및 CI green 상태라면 APPROVE 후 자동 머지됨.
여기서 중요한 점은, "AI가 AI를 고치는" 단일 구조의 루프가 아니라, "수정 측 AI"와 "심사 측 AI"가 완전히 독립되어 있다는 점임:
- 별도 프로세스 · 별도 세션: self-healing 모드의 AI와 reviewer 모드의 AI는 별도의
claude -p프로세스로 실행됨. 컨텍스트(context)는 공유되지 않음. - 다른 입력 소스: 수정 측은 Grafana 알람 + Loki + cpg로부터 문제를 구성함. 심사 측은 PR 차이(diff) + cpg + 가이드라인으로 판정함.
- 다른 평가 축: 수정 측은 "장애를 멈추는 것"이 목표이고, 심사 측은 "9가지 관점과 severity 규약을 위반하지 않았는가"가 목표임. 이해관계가 일치하지 않도록 설계됨.
결과적으로, Self-Healing이 대충 작성한 PR은 자동 리뷰에서 거절됨 (REQUEST_CHANGES → 수정 측으로 반환). AI가 자신의 출력을 스스로 승인하는 것이 아니기 때문에, 자기만족적인 "일단 돌아가기만 하는 fix"는 통과할 수 없는 구조임.
이는 LLM 에이전트 운용에서 종종 논점이 되는 **"심사의 독립성"**을, 여러 AI 에이전트의 분업을 통해 정석적으로 구현한 형태임.
구체적인 예시: meet subscription의 409 ALREADY_EXISTS
예시로, Meeting Intelligence에서 구현한 Google Meet 녹화 자동 취득 계통에서 발생한 알람을 살펴보겠음. 2026-05-21에 Self-Healing이 생성한 자동 수정 PR (fix(meet-subscription-renewal): auto-fix for Service Error Log Detected)
입니다.
Loki에서 수집한 에러 발생 원인:
Workspace Events API request failed: 409 Conflict
"Subscription associated with the resource already exists."
AI의 조사 흐름:
- Loki 쿼리로 에러 로그 특정 ── Grafana MCP를 통해
{service_name="meet-subscription-renewal"} | json | level=~"ERROR|error|Error"를 실행하여,Failed to renew Meet subscription의 스택 트레이스 (stack trace) 획득 - Product Graph로 호출 경로 추적 ──
renewSubscriptions→createMeetSubscription의 호출 경로 (call path) 특정 - 과거 PR과 대조 ── "역방향 불일치"("Firestore에는 이름이 있지만 Google 측에서는 사라짐" = 404)는 이미 별도의 PR을 통해
patchMeetSubscriptionTtl→ null fallback으로 자가 치유 (self-heal) 완료됨. 이번 방향("Google 측에는 남아 있지만 Firestore에는 없음" = 409)은 아직 대응되지 않았음을 발견 - 판정: "다른 패턴도 존재할 수 있는" 상황 →
[Recurrence]판정 매트릭스의 "수평 전개 필수" 케이스
임시방편의 수정이 아니라, 역방향으로 존재했던 fallback과 대칭이 되도록 동일한 방향의 자기 치유 (self-healing)를 구현했습니다:
createMeetSubscription을 멱등적 (idempotent)으로 변경- POST가 409를 반환하면, 응답에서 기존 Subscription 이름을 추출하여
patchMeetSubscriptionTtl을 호출 - 반환값을 호출 측에서 Firestore에 다시 기록하므로, 다음번 갱신 (renewal)부터는 일반적인 PATCH 경로로 수렴 (자기 치유)
- 기존 lint 규칙인
graph/no-silent-catch에 따라, JSON.parse 실패 시에도logger.warn+serializeError로 구조화된 로그 (structured log) 생성 - 테스트 3건 추가
이것이 "Self-Healing이 근본 원인 (root cause)까지 파고들어 수평 전개되는" 구체적인 패턴입니다. "증상을 없애는 것"이 아니라 "재발의 클래스를 닫는 것" (recurrence-prevention.md의 사상)을 AI가 자율적으로 실행하고 있는 예시입니다.
강화층 ── Guides (lint + 가이드라인)가 자동으로 늘어난다
이 부분이 Self-Healing을 단순한 "자동 복구"로 끝내지 않기 위한 핵심입니다.
Part 1에서 언급된 Martin Fowler의 Guides / Sensors 분류로 말하자면, 강화층은 Guides를 늘리는 곳 ── AI가 일탈을 일으키기 전의 사전 제어를 두텁게 만들어가는 측면에 해당합니다. cortex의 Guides는 2층 구조로 되어 있습니다:
- 기계가 읽는 Guide: lint / 타입 (type) / CI guard / 커버리지 임계값 (coverage threshold) / Prettier ── commit/CI에서 위반 사항을 물리적으로 제거
- 사람과 AI가 읽는 Guide:
recurrence-prevention.md,severity.md,ai-antipattern.md등의 가이드라인 ── 자동 리뷰가 판정 기준으로 사용
Part 3에서 작성한 9가지 관점이나 severity 규약, 강등 금지 규칙이 후자에 해당하고, Part 4에서 작성할 자동 lint 추가가 전자에 해당하며, 양자가 세트로 Guides를 구성합니다. lint는 "정형화된 가이드라인"이고, 가이드라인은 "아직 정형화되지 않은 lint"라고 말해도 좋습니다.
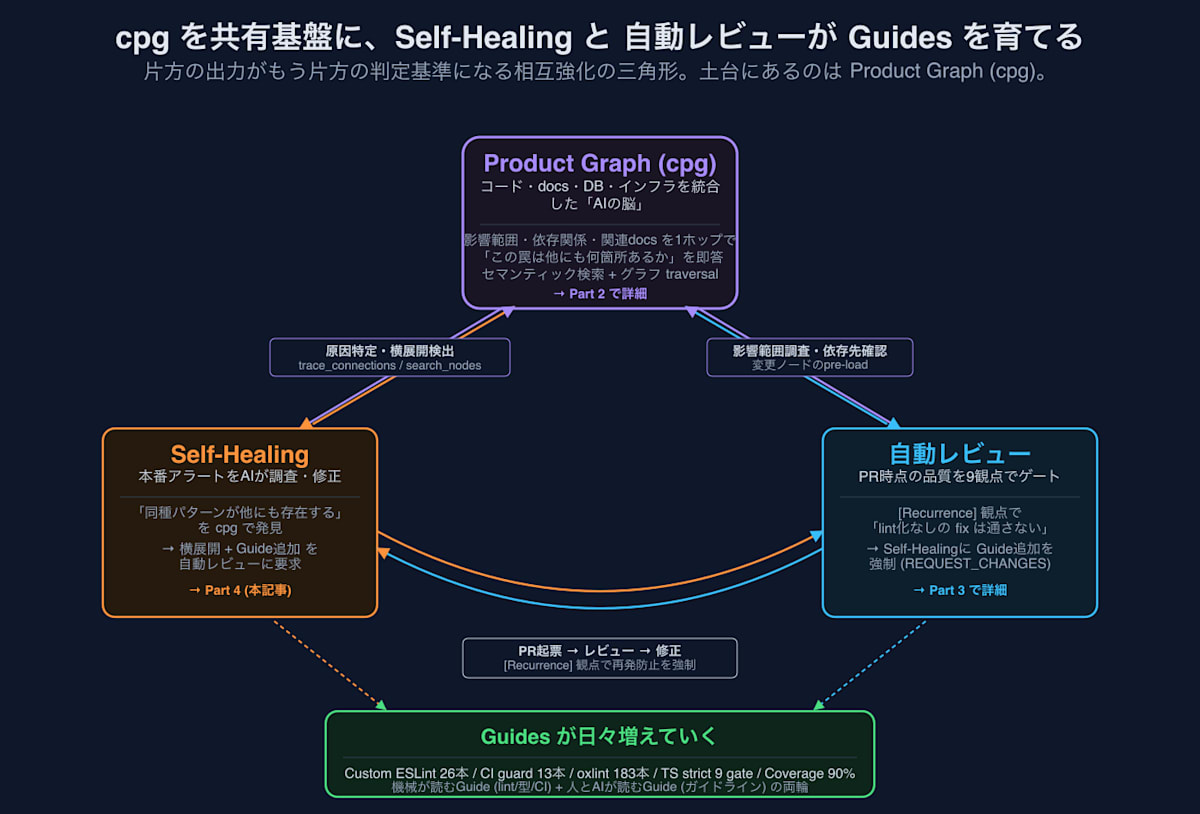
그리고 Sensors 측의 Self-Healing과 자동 리뷰가 작동할 때마다, 이 Guides를 서로를 위해 늘려가는 구조로 되어 있습니다:
- Self-Healing이 원인 조사 중 "동일한 패턴이 다른 곳에도 존재한다"고 발견 → 수평 전개 + lint화 (새로운 Guide 추가)를 요구
- 자동 리뷰가
[Recurrence]관점에서 "lint화 없는 fix는 통과시키지 않겠다"며 차단 - 두 가지 모두 cpg를 통해 영향 범위를 조망할 수 있기 때문에 가능한 일입니다.
cpg가 있기 때문에 AI는 "이 함정이 다른 곳에는 몇 군데나 더 있는가"를 살펴볼 수 있습니다. Self-Healing과 자동 리뷰 (Automated Review, = Sensors)는 cpg를 공유 기반으로 하여, 출력이 나올 때마다 Guides를 한 단계 더 두텁게 만드는 관계입니다.
Self-Healing이 작동할 때마다 일어나는 일 (재발 방지의 주역인 플로우)
Self-Healing이 생성하는 fix PR은 자동 리뷰를 통해 [Recurrence] 관점도 체크됩니다. 판정 매트릭스는 다음과 같습니다:
| 상황 | 필수 액션 | 형식 |
|---|---|---|
| 같은 함정을 2회 이상 밟았을 때 | lint화 필수 (custom ESLint 규칙 / 타입 제약 / CI guard) | 기계화 (Guide 추가) |
| 패턴이 다른 곳에도 존재할 가능성이 있을 때 | 수평 전개 필수 (cpg로 유사 노드 스캔, 이미 발견된 지점도 동일 PR에서 수정) | 조사 + 수정 |
| 기계적 검증은 불가능하지만 원칙적으로 가치가 있을 때 | 기존 가이드라인에 항목 추가 | 가이드라인 추가 |
| 단발적이며 원칙화할 가치가 없을 때 | 아무것도 하지 않음 (bug fix만 수행) | — |
"같은 함정을 2회 이상 밟은" 상황에서는, 수정 PR에 신규 lint를 포함하지 않으면 머지(Merge)되지 않습니다. 결과적으로 Self-Healing이 작동할 때마다 다음과 같은 일이 일어납니다:
- 동종 패턴을 cpg로 수평 전개 탐지 ── 수정 대상뿐만 아니라 유사 노드를 모두 열거
- 신규 Guide를 동일 PR에서 추가 ── ESLint custom rule / 타입 제약 / CI guard / 가이드라인 항목 중 하나
- 기존 위반 사항을 동일 PR 내에서 0으로 만듦 ──
warn으로 투입하여 미루는 것(deferral)을 금지하고,error로 투입 - 자동 리뷰 → 자동 머지 → 자동 재배포 ── Part 3의 통상적인 파이프라인
- 이후, 같은 방식으로 작성하려고 하면 CI / lint에서 기계적으로 차단 ── 동종 패턴의 재발을 구조적으로 봉쇄
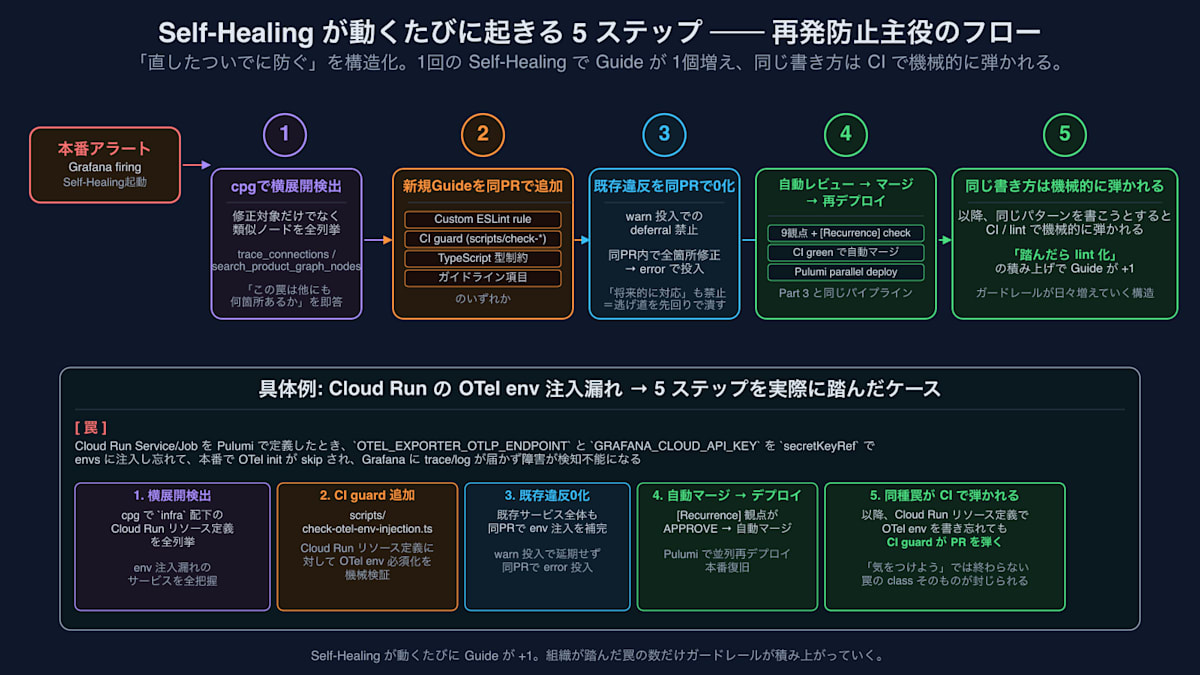
"고치는 김에 방지한다"가 Self-Healing을 기점으로 자동으로 계속 돌아가는 구조입니다.
"warn으로 도입"은 금지
"향후 대응", "가이드라인에 명문화되어 있는 중요한 규칙:"
- "향후 lint화를 검토", "다음 리팩토링 시 검토", "별도 PR에서 대응" ── 모두 금지. 대응 가능하다면 동일 PR에서 대응한다.
- "기존 위반이 남기 때문에
warn으로 도입하고, 나중에error로 격상" ── 채택하지 않는다. 이는 사실상의 deferral이며,warn을error로 격상해야 하는 책임이 공중에 떠서 노후화되기 때문이다. - lint 규칙을 추가한다면 동일 PR에서 기존 위반도 0으로 만들고
error로 투입한다.
이것 역시 결국 Part 3에서 기술한 "강등 금지 규칙"의 계보이며, 전형적인 회피 방법을 선제적으로 차단한다는 발상입니다.
"밟으면 Guide화"의 계보 (실례 모음)
cortex에 쌓여 있는 custom Guide의 실례:
graph/no-silent-catch(ESLint) ── 서두에 언급한 "상향 편향(upward bias)"의 원흉. catch 블록에서 예외를 무시하는 패턴을 금지- stacktrace 소실 방지 가이드라인 (
docs/guidelines/observability.md에서 Major 위반으로 규약화, 자동 리뷰가 포착) ──logger.error(err.message)와 같이 stacktrace를 버리고 message 문자열만 남기는 로그를 금지.err필드에serializeError(error)의 반환값을 넣어name/message/stack을 보존하도록 함.
AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기