
로그 연산을 활용한 Tensordyne의 Napier AI 프로세서 발표
요약
Tensordyne가 로그 수학을 활용해 곱셈 연산을 덧셈으로 전환하는 3nm AI 프로세서 'Napier'를 발표했습니다. 이 방식은 실리콘 면적을 효율적으로 사용하여 SRAM을 늘리고 랙 단위 추론의 경제성을 높이는 것을 목표로 합니다.
핵심 포인트
- 로그 수학 기반 설계로 곱셈기 면적을 줄이고 SRAM 확보
- 전력 소모를 낮추고 랙당 토큰 처리량 극대화 지향
- 2027년 시스템 로드맵을 가진 테이프아웃 단계의 칩
- 기존 NVIDIA/Groq 대비 높은 전력 및 공간 효율성 주장
Tensordyne는 독자적인 로그 수학 (logarithmic mathematics)을 기반으로 구축된 3nm AI 프로세서 및 랙 스케일 추론 (rack-scale inference) 플랫폼인 Napier를 발표했습니다. 흥미로운 점은 단순히 혼잡한 시장에 또 다른 AI 칩 스타트업이 진입했다는 사실이 아니라, 가속기 내의 수학적 방식을 변경함으로써 곱셈기 (multiplier) 면적을 줄이고, 온칩 SRAM (on-chip SRAM)을 늘리며, 랙 레벨 추론 (rack-level inference)의 경제성을 개선할 수 있다는 회사의 주장입니다. 현재 Napier는 테이프아웃 (taped-out)된 칩 단계이며 2027년 시스템 로드맵을 가지고 있으므로, 성능과 소프트웨어에 대한 주장이 실제 배포 환경에서도 유효할지가 관건입니다.
Tensordyne Napier AI 프로세서 발표
Tensordyne는 AI 추론 (inference)의 속도와 비용 문제를 동시에 해결하기 위한 방법으로 Napier를 포지셔닝하고 있습니다. 회사는 단순히 더 전통적인 행렬 곱셈 (matrix-multiply) 자원을 중심으로 구축하는 대신, 로그 수학 (logarithmic math) 접근 방식을 통해 곱셈 연산을 덧셈으로 전환한다고 밝혔습니다. 가산기 (Adder)는 곱셈기 (multiplier)보다 크기가 작고 일반적으로 전력 소모가 적기 때문에, 이를 통해 메모리를 위한 더 유용한 실리콘 면적을 확보하고 더 나은 시스템 균형을 맞출 수 있다는 약속을 하고 있습니다.
이를 위해, 단순히 칩 하나를 만드는 것이 아니라 클러스터 아키텍처 (cluster architecture)를 포함하는 생태계를 발표하고 있습니다.
이것이 중요한 이유는 오늘날 많은 AI 인프라 논의가 더 이상 가속기의 피크 TOPS나 FLOPS에만 국한되지 않기 때문입니다. 긴 문맥 추론 (Long-context inference), 에이전틱 워크플로 (agentic workflows), 그리고 전문가 혼합 (mixture-of-experts) 모델은 메모리, 상호 연결 (interconnect), 디코딩 처리량 (decode throughput), 랙 전력 및 냉각에 의해 제약을 받을 수 있습니다. Tensordyne의 주장은 더 균형 잡힌 칩 및 랙 설계가 현재의 하이엔드 대안들보다 랙당 더 많은 토큰과 메가와트당 더 많은 토큰을 제공할 수 있다는 것입니다.

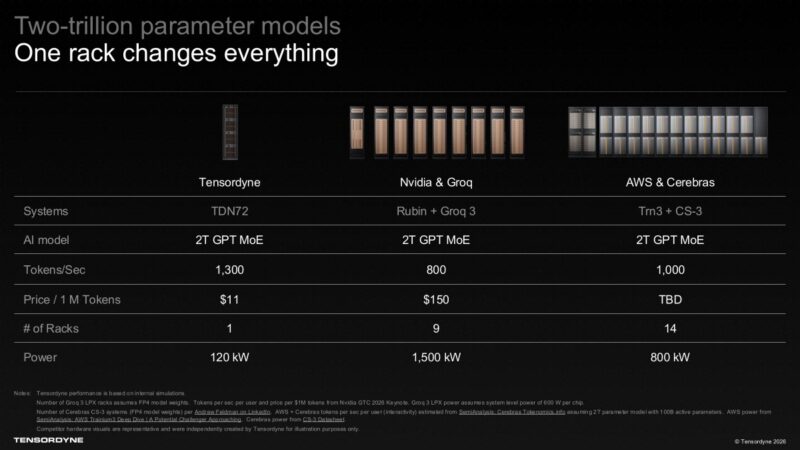
Tensordyne는 2조 개의 파라미터를 가진 GPT MoE 모델을 대상으로 자사의 TDN72 랙을 더 큰 멀티 랙(multi-rack) 구성과 비교합니다. 이 비교에서 회사는 120kW 규모의 TDN72 랙 하나가 사용자당 초당 1,300개의 토큰에 도달할 수 있는 반면, NVIDIA와 Groq는 9개의 랙과 1.5MW가 필요하며, AWS와 Cerebras는 14개의 랙과 800kW가 필요하다고 밝히고 있습니다. 이러한 비교 수치들은 눈길을 끌지만, Napier는 현재 제품을 발표하는 단계에 있습니다.

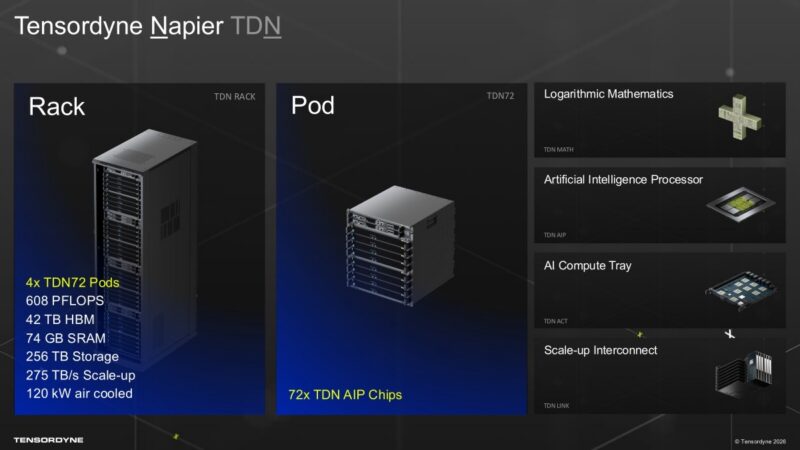
전체 TDN72 시스템은 72개의 노드, 총 68 페타플롭스(petaflops)의 연산 능력, 그리고 42TB의 HBM을 중심으로 설계되었습니다. Tensordyne는 자사의 용량이 최대 10조에서 20조 개의 파라미터를 가진 모델을 목표로 하고 있다고 말하며, 이러한 모델에서는 메모리 점유율(memory footprint)과 전문가 라우팅(expert routing)이 주요한 시스템 수준의 과제가 됩니다. 또한, 인터커넥트(interconnect), 메모리, 전력 또는 냉각 인프라가 제한 요소가 될 경우 단순히 가속기를 추가하는 것만으로는 도움이 되지 않기 때문에, 바로 이 지점에서 랙 규모(rack-scale) 설계가 중요해집니다.
Napier 자체는 1,380억 개의 트랜지스터를 가진 TSMC 3nm 칩입니다. Tensordyne는 다이(die)당 2.1 페타플롭스의 연산 능력, 1.33GHz 가속기 코어, 1.5GHz CPU, 256MB의 SRAM, 그리고 144GB의 HBM3E를 명시하고 있습니다. 더 중요한 주장 중 하나는 Napier가 NVIDIA Blackwell보다 5배 많은 SRAM을 보유하고 있다는 점입니다. 만약 이것이 유용한 워크로드(workload)에서 입증된다면, 추가된 SRAM은 더 많은 데이터를 연산 패브릭(compute fabric) 가까이에 유지하고 시스템 전체에서 데이터를 이동할 때 발생하는 페널티를 줄이는 데 도움이 될 수 있습니다.
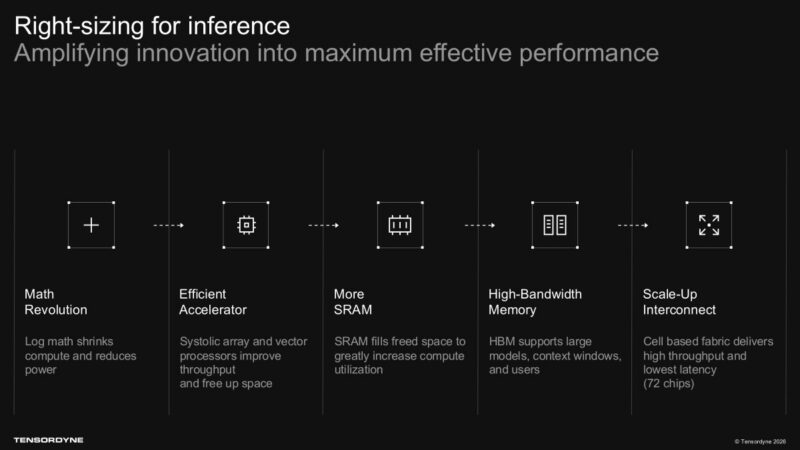
로그 수학(logarithmic math) 개념이 아키텍처의 핵심 요소입니다. Tensordyne는 승수(multiplier)의 점유 면적을 줄이면 SRAM을 위한 공간을 더 많이 확보할 수 있는 반면, 시스톨릭 어레이(systolic array)와 벡터 프로세서(vector processor)가 처리량(throughput)을 담당한다고 설명합니다. 이는 단순히 더 밀집된 행렬 연산 유닛(matrix math units)의 개수를 세는 것과는 다른 방식으로 AI 가속기 문제를 정의하는 방식입니다. 동시에, 수치적 접근 방식(numerical approaches)을 변경하는 것은 정확도, 소프트웨어 및 모델 포팅(model-porting)에 영향을 미칠 수 있으므로, 이 부분이야말로 제3자의 워크로드 테스트가 가장 필요한 대목이기도 합니다.

트레이(Tray) 레벨에서 Tensordyne는 1.3TB의 HBM3E, 8TB의 스토리지, Intel Xeon 호스트 CPU, 그리고 듀얼 200GbE를 갖춘 1RU AI 컴퓨팅 트레이(AI Compute Tray)에 9개의 Napier 칩을 패키징합니다. 4개의 트레이가 하나의 TDN72 포드(pod)를 구성하며, 4개의 포드가 표준 52RU 랙에 들어갑니다. 중요한 실무적 포인트는 Tensordyne가 공랭식(air-cooled) 시스템을 목표로 하고 있다는 점입니다. 대규모 AI에는 액체 냉각(Liquid cooling)이 사용되지만, Tensordyne는 공랭식 시스템을 지향합니다. 또한 프런트엔드(front-end)가 2x 200GbE라는 점도 흥미로운데, 이는 Intel Xeon 호스트 CPU가 x16 링크당 800Gbps를 구동할 수 있는 PCIe Gen6를 지원하지 않을 것임을 시사하는 것으로 보입니다.

스케일업(Scale-up) 연결성 또한 설계의 주요 부분입니다. Tensordyne는 자사의 인터커넥트(interconnect)를 TDN Link라고 부르며, 72개 칩 시스템 전체에 걸쳐 1TB/s의 대역폭(bandwidth)과 1마이크로초 미만(sub-microsecond)의 칩 간 지연 시간(chip-to-chip latency)을 제공할 수 있다고 밝힙니다. 전문가 혼합(Mixture-of-Experts, MoE) 및 에이전틱 AI(agentic AI) 워크로드의 경우, 전문가 라우팅(routing experts), 활성화 값 이동(moving activations), 그리고 많은 사용자를 지속적으로 지원하는 과정에서 지연 시간과 대역폭의 한계가 드러날 수 있기 때문에 인터커넥트가 가속기만큼이나 중요할 수 있습니다. NVL72 스파인(spine) 대신, 이는 전통적인 섀시 스위치(chassis switch) 네트워킹 솔루션에 더 가까워 보입니다.

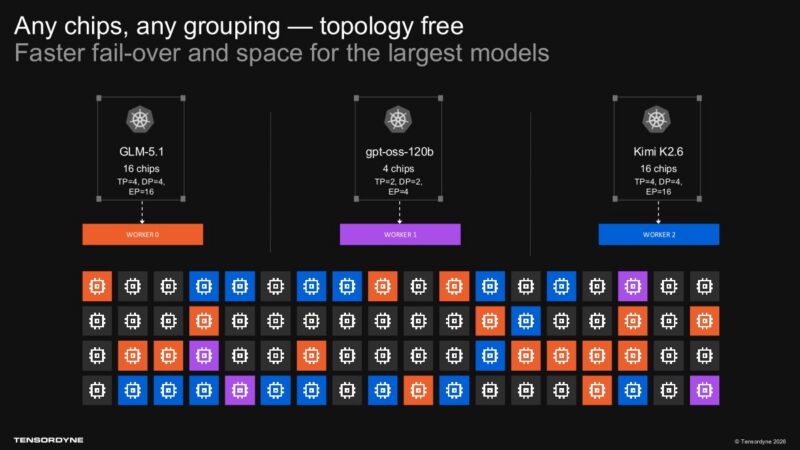
토폴로지(Topology) 유연성 또한 동일한 인터커넥트 이야기의 일부입니다. Tensordyne는 워크로드를 위해 어떤 칩이든 그룹화할 수 있다고 말하며, 이는 소프트웨어 스택이 이를 투명하게 처리할 수 있다면 장애 조치(failover) 및 모델 배치(model placement)에 도움이 될 것입니다. 이는 대규모 배포에 있어 유용한 주장이나, 운영 세부 사항이 매우 중요한 영역이기도 합니다. 고객이 그 이점을 느끼기 전까지 클러스터 스케줄러(Cluster schedulers), 모델 서빙 레이어(model serving layers), 장애 처리(failure handling), 그리고 관측성(observability)이 원활하게 작동해야 합니다.
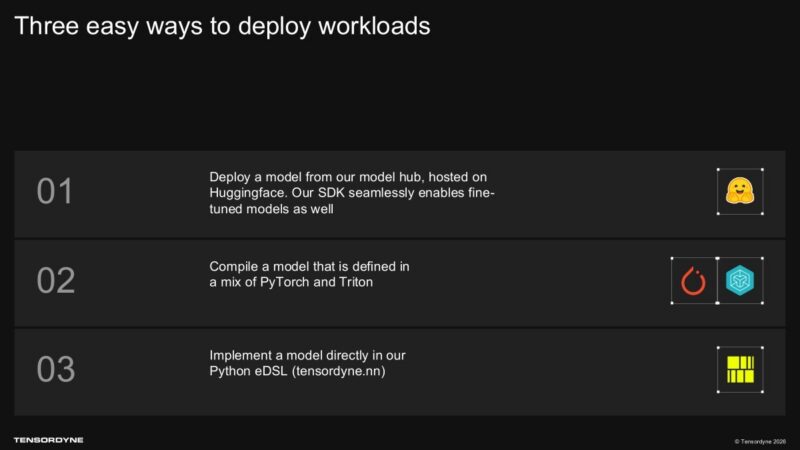
소프트웨어가 출시 과정에서 더 어려운 부분이 될 수도 있습니다. Tensordyne는 자사의 SDK와 함께 Hugging Face에 호스팅되는 모델 허브, PyTorch 및 Triton 정의 모델을 위한 직접 컴파일(direct compilation), 그리고 tensordyne.nn이라 불리는 커스텀 Python eDSL(embedded Domain Specific Language)에 대해 논의하고 있습니다. NVIDIA의 CUDA 생태계는 프레임워크, 커널(kernels), 프로파일링 도구(profiling tools), 배포 패턴(deployment patterns), 그리고 개발자 습관이 결합된 거대한 기반입니다. 어떤 새로운 AI 가속기(accelerator)라도 고객이 시도해 볼 수 있을 만큼 소프트웨어 경로가 충분히 쉽다고 느껴지게 만들어야 합니다.
파트너십 또한 여기서 중요합니다. Tensordyne는 섀시(chassis) 및 인프라 구성 요소를 위해 HPE 및 Juniper와 협력하고 있다고 밝혔으며, 이는 회사가 단순한 칩 개발자를 넘어 시스템 벤더로서 더 높은 신뢰성을 확보하는 데 도움이 될 것입니다. Broadcom을 통한 TSMC의 3nm 테이프아웃(tape-out)은 의미 있는 이정표이지만, 랙 스케일(rack-scale) AI 시스템에는 공급망, 플랫폼 검증, 현장 지원, 그리고 새로운 아키텍처에 워크로드(workloads)를 맡길 의사가 있는 고객이 필요합니다.

타이밍은 또 다른 도전 과제입니다. Tensordyne는 2027년 1분기에 베타 프로그램이 계획되어 있으며, 2027년 2분기 말까지 시스템 출하가 예상된다고 밝혔습니다. 그때쯤이면 NVIDIA, AMD, 하이퍼스케일(hyperscale) 기업들의 자체 실리콘(internal silicon) 노력, Cerebras, Groq 및 기타 AI 인프라 옵션들은 또 한 번 진화해 있을 것입니다. Napier는 주장된 효율성이 실제 모델 서빙(model serving), 실제 소프트웨어 스택(software stacks), 그리고 실제 고객 운영 환경에서도 유지됨을 증명해야 합니다.
마치며
Tensordyne Napier는 단순히 NVIDIA와 다르게 규모를 확장하려는 것이 아니라, 연산 방식(the math) 자체를 바꾸려 한다는 점에서 가장 흥미로운 AI 가속기 발표 중 하나입니다. NVIDIA와 유사한 폼 팩터(form factor)를 가진 가속기를 만들면서 단순히 더 저렴하다고 말하는 방식은 다른 이들이 성공을 거둔 방식이 아니기에, 이러한 연산 방식의 변화는 흥미롭습니다. 3nm 테이프아웃, 1,380억 개의 트랜지스터 수치, 대용량 SRAM 주장, 42TB HBM 랙 구성, 그리고 공랭식(air-cooled) TDN72 시스템 모두 이 제품을 주목할 가치가 있게 만듭니다.
하지만 매력적인 출시와 성공적인 AI 플랫폼 사이의 간극은 매우 큽니다. 랙당 성능(performance per rack)과 메가와트당 성능(performance per megawatt)은 정확히 목표로 삼아야 할 지표입니다. 만약 Tensordyne의 기술이 제대로 작동하고 2027년에 실현될 수 있다면, Napier는 추론 인프라(inference infrastructure)를 위한 주목할 만한 대안이 될 수 있습니다. 어쩌면 우리는 수십억 달러 규모의 계약을 보기 시작할지도 모릅니다. 그때까지 이것은 여전히 증명해야 할 것이 많은 야심 찬 아키텍처(architecture)이므로, 지켜보는 것은 흥미로운 일이 될 것입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 ServeTheHome의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기