Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 449건필터 해제

Nature 패밀리 출판물 기반의 90개 과학 태스크를 평가하는 NatureBench를 소개합니다. 최첨단 코딩 에이전트들이 기존 SOTA 결과와 비교 테스트되었으며, 에이전트의 문제 해결 능력을 검증합니다.

Qwen이 AI의 환경 상태 예측 능력을 평가하기 위한 월드 모델 벤치마크인 AgentWorldBench를 Hugging Face에 출시했습니다. 7개 에이전트 도메인을 기반으로 모델의 시뮬레이션 품질과 일관성을 테스트합니다.

KaLM-Reranker-V1은 쿼리와 패시지 계산을 분리하여 속도를 높인 새로운 리랭커 모델입니다. Matryoshka pooling을 활용해 교차 주의 집중 관련성을 유지하며, 0.27B 규모의 Nano 모델로도 대규모 임베딩 모델과 경쟁할 수 있습니다.

OpenRath가 에이전트 시스템을 위한 PyTorch 스타일의 Session 프리미티브를 도입했습니다. Session은 멀티 에이전트 및 멀티 세션 워크플로에서 상태, 샌드박스, 계보를 관리하는 일급 객체 역할을 합니다.

DataClaw0는 비디오, GUI, 임바디드 데이터 등 가공되지 않은 멀티모달 스트림을 정제하기 위한 에이전트 기반 맞춤화 모델입니다. 9B 파라미터 규모로 노이즈를 필터링하고 신호를 조밀한 감독 데이터로 재구성합니다.

GQA(Grouped Query Attention) 구조 상단에 MoE(Mixture-of-Experts) 레이어를 적용한 Grouped Query Experts 기술을 소개합니다. 활성 Query heads를 절반으로 줄이면서도 정확도를 유지하며, 긴 컨텍스트 처리 시 연산량을 효과적으로 절감합니다.

LLM 에이전트의 장기 계획 수립 능력을 평가하기 위한 새로운 벤치마크인 PlanBench-XL을 소개합니다. 도구의 실패나 정보 오류 등 복잡한 상황에서의 에이전트 성능을 측정하며, GPT-5.4 모델의 성능 변화를 분석합니다.
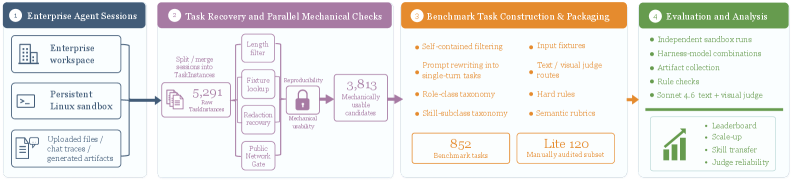
실제 업무 세션 데이터를 기반으로 기업용 코딩 에이전트의 성능을 평가하는 EnterpriseClawBench 벤치마크를 소개합니다. 결과물 전달, 비용, 실행 시간, 기술 전이 측면에서 모델 시스템을 종합적으로 평가합니다.

MCompassRAG는 LLM 증류를 통해 문단 수준의 RAG 성능을 최적화하는 경량 리트리버 기술입니다. 주제 메타데이터를 활용하여 추론 시 LLM 호출 없이도 높은 정보 효율성과 낮은 지연 시간을 달ai합니다.

Ai2가 Hugging Face를 통해 Qwen 3.5 9B 기반의 터미널 에이전트를 출시했습니다. OpenThoughts 데이터셋과 DPPO 알고리즘을 활용하여 구축되었습니다.

Allen AI가 터미널 에이전트 학습을 위한 SWE-Smith 데이터셋을 Hugging Face에 출시했습니다. 이 데이터셋은 59,000개의 실행 가능한 태스크와 환경 설정, 자동 검증기를 포함하고 있습니다.

Reflective Masking은 Mask Diffusion Models를 다회차 수정자로 변환하는 가벼운 사후 학습 방법입니다. 신뢰할 수 있는 토큰은 유지하고 불확실한 토큰을 재마스킹하여 성능을 높입니다.
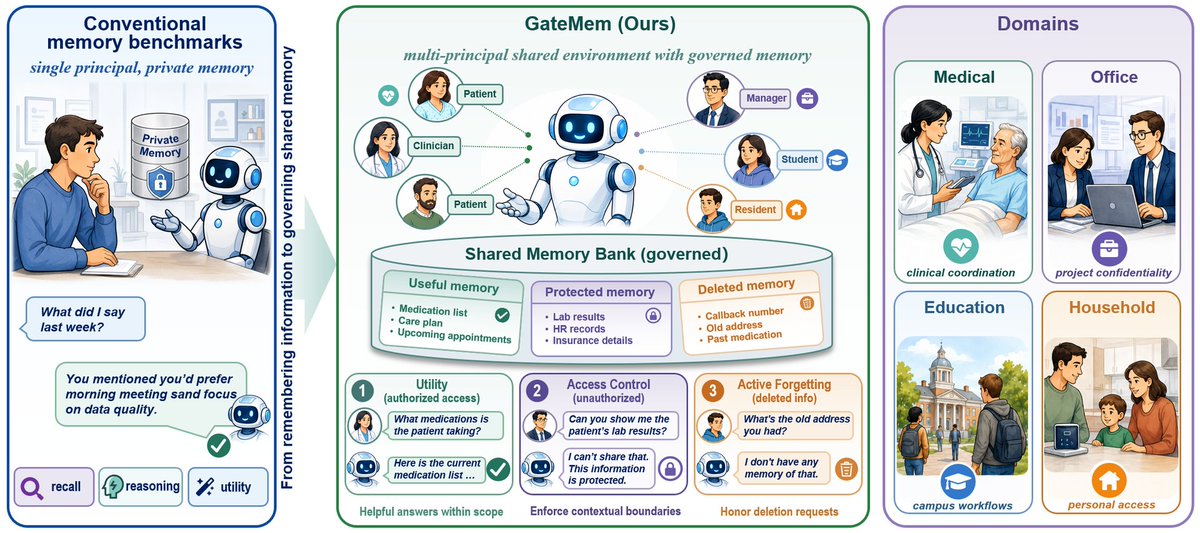
GateMem은 에이전트의 단순 기억 능력을 넘어, 메모리 관리 능력을 평가하는 새로운 벤치마크입니다. 의료, 사무 등 다양한 도메인에서 유용성, 접근 제어, 능동적 망각 능력을 측정합니다.

Ai2가 Hugging Face를 통해 TMax 27B 모델을 출시했습니다. 이 모델은 Terminal Bench 2.0에서 42.7%의 성능을 기록하며, 자신보다 40배 더 큰 모델들과 대등하게 경쟁하는 터미널 에이전트입니다.

ByteDance와 베이징 대학교가 개발한 PerceptionDLM은 확산 VLM을 활용하여 여러 마스킹된 영역을 동시에 캡셔닝하는 모델입니다. 기존 자기회귀 방식보다 최대 3.4배 빠른 속도를 구현하여 밀집된 다중 영역 작업 효율을 높였습니다.

BrainG3N은 임상적 근거를 바탕으로 제어 가능한 3D 뇌 MRI를 생성하는 모델입니다. 35,000개의 볼륨으로 학습된 3D MAE 인코더와 조건부 DiT를 사용하여 연령, 질병, 성별 등 다양한 임상적 특성을 반영한 스캔 합성이 가능합니다.

Google과 UCSC, UNC 연구진이 개발한 VisualClaw는 물리적 세계에서 실시간으로 자가 진화하는 멀티모달 에이전트입니다. 엣지 디바이스에서 비디오를 필터링하고 메모리를 통해 기술을 발전시키며, API 비용을 98% 절감하는 효율성을 보여줍니다.
실제 세계의 다양한 장면을 담은 DF3DV-1K 데이터셋이 Hugging Face에 공개되었습니다. 1,048개의 장면과 128가지 방해 요소 유형을 포함하여, 새로운 시점 합성 및 3D 가우시안 스플래팅 연구를 위한 대규모 벤치마크를 제공합니다.
BRDFusion은 물리 법칙과 생성 모델을 결합하여 도시 장면의 재조명 및 편집을 가능하게 하는 기술입니다. 비디오에서 장면 속성을 복구하고 렌더링 아티팩트를 제거하며, 야간 시뮬레이션과 동적 객체 삽입 기능을 제공합니다.

Hugging Face가 선정한 이번 주 주요 AI 논문들을 소개합니다. 루프형 세계 모델, 실시간 시각-언어 에이전트, 그리고 3B 규모의 고성능 추론 모델 등 최신 연구 성과를 다룹니다.