Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 449건필터 해제

ICWM은 로봇이 새로운 카메라 환경이나 형태에 즉각 적응할 수 있도록 돕는 인컨텍스트 월드 모델링 기술입니다. 별도의 파인튜닝 없이 단 몇 초간의 상호작용만으로 월드 다이내믹스를 학습하여 제로샷 일반화를 구현합니다.

월드 모델, 비디오 생성, 시각-언어-행동 정책(VLA)을 하나의 체계로 통합하여 분석한 서베이 논문입니다. 예측된 미래를 실제 행동으로 연결하는 100개 이상의 방법론을 구조화된 분류 체계로 제시합니다.

OPID는 에이전트가 자신의 사후 과잉 확신(hindsight)을 통해 학습하는 새로운 방법을 제안합니다. 계층적 기술을 완료된 궤적으로부터 직접 증류하여 추론 시 외부 메모리 없이도 높은 효율을 보여줍니다.

Qwen이 11개 언어의 음성에 대해 정밀한 단어 수준 타임스탬프를 예측하는 Qwen3 Forced Aligner를 Hugging Face에 출시했습니다. 이 모델은 LLM 기반의 비자기회적(non-autoregressive) 방식을 사용하여 기존 엔드투엔드 정렬기보다 높은 정확도를 제공합니다.

NVIDIA가 Hugging Face를 통해 실시간 제로샷 스테레오 매칭 모델인 Fast FoundationStereo를 출시했습니다. 이 모델은 기존 파운데이션 모델 대비 정확도를 유지하면서도 속도를 10배 향상시킨 것이 특징입니다.

ByteDance Seed가 T2I, 로컬 및 글로벌 편집을 통합한 단일 플로우 모델인 DanceOPD를 출시했습니다. 이 모델은 기존 증류 방식보다 10배 높은 효율성을 자랑하며, 높은 벤치마크 성능을 유지합니다. 또한 NVIDIA는 Blackwell GPU에 최적화된 753B 파라미터 규모의 GLM-5.2 모델을 출시했습니다.

ViQ는 이산적 시각적 토크나이저와 연속적 인코더 사이의 간극을 메우는 새로운 기술입니다. 모든 해상도에서 이미지를 이산 코드로 처리하여 멀티모달 학습 시간을 20~70%까지 단축할 수 있습니다.

NVIDIA가 Hugging Face에 최적화된 GLM-5.2 모델을 출시했습니다. 이 모델은 753B 파라미터의 MoE 구조를 가지며 1M 컨텍스트를 지원합니다.

Sony AI와 KAIST가 새로운 시점 비디오 생성을 위한 MVTrack4Gen 프레임워크를 발표했습니다. 다중 시점 포인트 트래킹을 활용해 3D 재구성 없이도 높은 기하학적 일관성을 달성했습니다. 또한 NVIDIA가 1M 컨텍스트를 지원하는 753B 파라미터 규모의 GLM-5.2 모델을 출시했습니다.

시각적 정보와 코드를 연결하는 멀티모달 코드 지능(Multimodal Code Intelligence)에 관한 조사 연구입니다. 단순 모방을 넘어 GUI, 플롯, 그래픽을 이해하고 실행 가능한 코드를 생성하는 검증 중심의 네 가지 방향성을 제안합니다.

Alibaba가 발표한 Wan-Streamer v0.1은 네이티브 스트리밍 방식의 엔드 투 엔드 대화형 파운데이션 모델입니다. 하나의 트랜스포머가 시각, 청각, 사고 과정을 통합하여 200ms 미만의 초저지연 오디오 및 비디오 응답을 제공합니다.

NVIDIA가 Hugging Face를 통해 로보틱스 학습을 위한 DROID 데이터셋을 공개했습니다. 이 데이터셋은 564개의 장면과 76,000개의 실제 세계 궤적을 포함하며, LeRobot v3.0 형식으로 제공되어 상업적 이용이 가능합니다.

DomainShuttle은 텍스트-비디오 생성 시 피사체를 다양한 도메인으로 이동시킬 수 있는 모델입니다. 참조 기능과 비디오 특징을 분리하여 도메인 내 충실도와 도메인 간 편집 가능성을 동시에 확보했습니다.

OpenThoughts-Agent는 에이전트 모델을 위한 개방형 데이터 큐레이션 파이프라인을 제안합니다. Qwen3-32B를 활용해 벤치마크 성능을 대폭 향상시켰으며, MobileForge를 통해 라벨 없이도 모바일 GUI 에이전트를 학습시키는 기술을 공개했습니다.
NVIDIA가 Hugging Face를 통해 NVFP4 양자화 기술이 적용된 MiniMax-M3 모델을 출시했습니다. 이 모델은 428B 파라미터의 멀티모달 MoE 구조로, Blackwell GPU에서 메모리 효율을 극대화하며 NatureBench를 통해 성능을 검증합니다.

Kuaishou가 개발한 MemGUI-Agent는 자체 메모리 관리 기능을 갖춘 롱-호라이즌 모바일 GUI 에이전트입니다. ConAct 기술을 통해 UI 상태를 구조화된 액션으로 압축하여 프롬프트 폭발 문제를 해결했습니다.

AOHP는 AOSP를 기반으로 에이전트를 OS의 핵심 요소로 격상시킨 새로운 운영체제 환경을 제안합니다. 자연어를 통해 개인화된 앱을 생성하며, 작업 완료율 향상과 토큰 비용 절감, 강력한 보안을 제공합니다.

Kuaishou가 어노테이션 없이 모바일 GUI 에이전트를 학습시키는 MobileForge를 오픈 소스로 공개했습니다. 또한 Qwen은 7개 도메인을 시뮬레이션할 수 있는 언어 세계 모델인 AgentWorld를 출시했습니다.

Qwen이 7개 도메인에서 에이전트를 시뮬레이션하는 최초의 언어 세계 모델인 AgentWorld를 Hugging Face에 출시했습니다. 이 모델은 환경 상태 변화를 예측하는 능력을 테스트하며, 35B 파라미터 규모와 256K 컨텍스트 윈도우를 지원합니다.
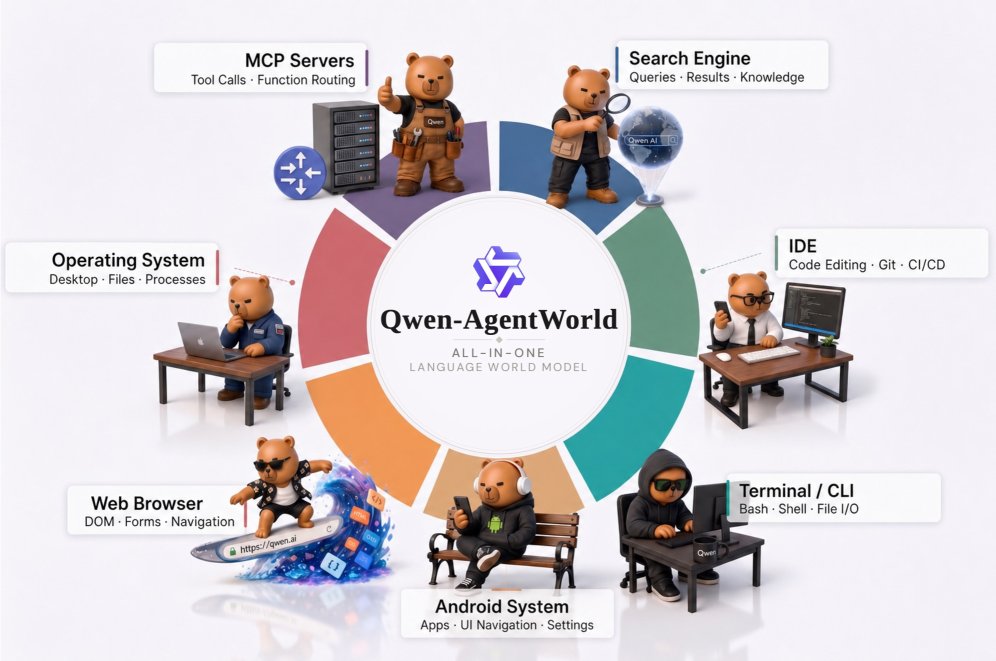
Alibaba Qwen 팀이 긴 사고 사슬(CoT) 추론을 통해 7가지 에이전트 도메인을 시뮬레이션하는 네이티브 언어 세계 모델인 Qwen-AgentWorld를 출시했습니다. 이 모델은 1,000만 개 이상의 궤적 데이터로 학습되어 확장 가능한 시뮬레이터 및 에이전트 파운데이션 모델 역할을 수행합니다.