Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 447건필터 해제

NVIDIA가 Hugging Face를 통해 베트남어 AI 안전 평가 데이터셋인 VISafe를 출시했습니다. 이 데이터셋은 베트남어 문맥에서의 탈옥, 독성, 오정보 및 프롬프트 주입을 탐지하기 위한 3,212개의 탐침을 포함합니다.
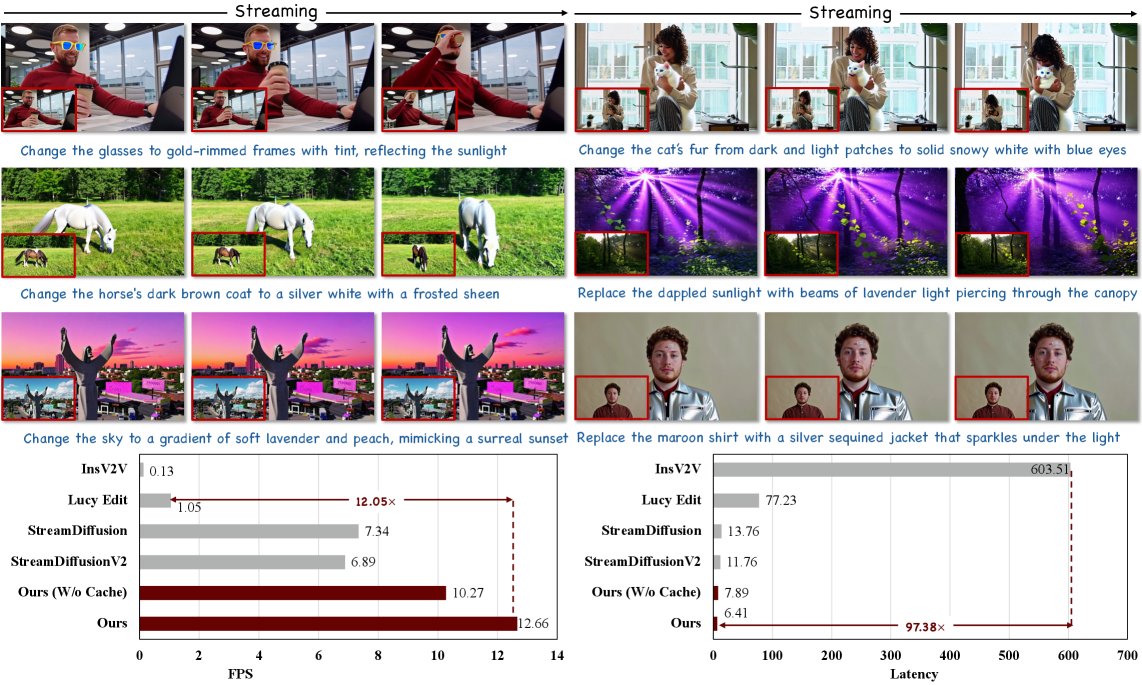
ECCV 2026에 채택된 LiveEdit는 12.66 FPS의 속도를 구현한 실시간 확산 모델 기반 스트리밍 비디오 편집 기술입니다. 3단계 증류 파이프라인을 통해 배경을 강력하게 보존하면서도 낮은 지연 시간으로 프레임 단위 편집을 지원합니다.

Qwen이 52개 언어와 방언을 지원하는 오픈 소스 음성 인식 모델 Qwen3-ASR을 Hugging Face에 출시했습니다. 1.7B 파라미터 규모임에도 폐쇄형 API와 경쟁하는 SOTA 성능을 보여주며, Transformers 환경에서 네이티브로 실행됩니다.
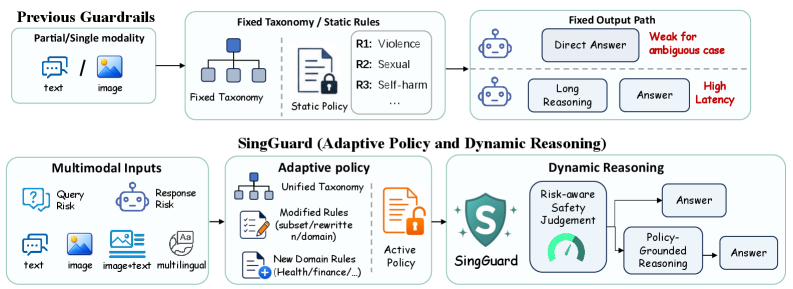
SingGuard는 멀티모달 AI의 안전성을 위해 런타임 정책 기반의 가드레일을 제안하는 연구입니다. 텍스트와 이미지를 포함한 교차 모달 콘텐츠를 빠른/느린 추론 방식으로 판별하며, 다양한 데이터셋에서 SOTA 성능을 달성했습니다.

LLM의 잠재적 사고 표현(latent thought representations)을 분석한 새로운 연구를 소개합니다. 인과성, 최소성, 분리성, 안정성이라는 네 가지 공리를 통해 오픈 웨이트 모델들의 사고 과정을 검증했습니다.

MultiHashFormer는 토큰 해싱 기술을 인과적 언어 모델(causal LMs)에 도입하여 임베딩 메모리를 획기적으로 절감하는 연구입니다. 멀티 ID 시그니처를 활용한 해시 기반 자기회귀 방식을 통해 기존 트랜스포머 모델보다 효율적이고 뛰어난 성능을 입증했습니다.

ByteDance가 Hugging Face에 계층적 AI 안전 벤치마크인 SafePyramid를 출시했습니다. 이 벤치마크는 인컨텍스트 정책 가드레일링 성능을 측정하며, 최신 모델들의 정책 준수율이 급격히 하락함을 보여줍니다.

ByteDance Seed 팀이 저렴한 인간 영상을 로봇 동작으로 변환하는 새로운 기술을 발표했습니다. 노이즈가 많은 6DoF 손 포즈 대신 상대적 손목 이동을 사용하여 인간과 양팔 로봇 간의 공유된 액션 공간을 구축했습니다.

Peking University와 NVIDIA가 개발한 PhysisForcing은 로봇 비디오 생성을 물리적으로 타당하게 만드는 플러그 앤 플레이 학습 프레임워크입니다. 추가적인 추론 비용 없이도 주요 벤치마크에서 성능 향상을 입증했습니다.

Kuaishou의 Kling 팀이 개발한 UnityShots는 일관된 멀티샷 오디오-비디오 생성을 위한 메모리 구동 시스템입니다. LTX-2.3을 기반으로 하며, 메모리 슬롯을 통해 샷 간의 정체성과 세계관을 유지합니다.

Alibaba Qwen 팀이 훈련 없이 추론 성능을 높이는 'Confident Decoding' 기술을 발표했습니다. 최종 레이어의 정렬 세금을 우회하여 가장 확신 있는 표현을 선택함으로써, 낮은 지연 시간 오버헤드로 큰 추론 이득을 얻을 수 있습니다.

BioMatrix는 서열, 구조, 언어를 통합적으로 처리하는 최초의 생물학적 파운데이션 모델입니다. 단일 디코더 아키텍처를 통해 분자와 단백질을 공유 토큰 공간으로 매핑하며, 80개 태스크 중 77개에서 SOTA를 달성했습니다.

GUI 에이전트와 CLI 에이전트의 성능을 440개의 데스크톱 작업을 통해 비교 분석한 연구입니다. GUI 에이전트는 초기 성능은 높으나 장기 상호작용에 취약하며, CLI 에이전트는 기술 증강을 통해 더 높은 성능을 달성할 수 있음을 보여줍니다.

정답 레이블 없이 시각적 추론을 수행하는 V-Zero 모델을 소개합니다. 대조적 증거 게이팅과 온-정책 증류 기술을 결합하여 기존 SFT나 RL 방식보다 훨씬 빠른 학습 속도를 구현했습니다.

JetSpec은 인과적 병렬 트리 초안 작성(Causal Parallel Tree Drafting)을 통해 추측적 디코딩의 한계를 극복한 새로운 방법론입니다. 단 한 번의 순방향 패스로 토큰 트리를 생성하여 수학 분야에서 최대 9.64배의 속도 향상을 달성했습니다.

EvoEmbedding은 잠재 메모리 큐를 활용하여 긴 문맥 검색을 위한 동적 표현을 생성하는 진화 가능한 임베딩 모델입니다. 자신보다 3배 큰 정적 전문 모델보다 뛰어난 성능을 입증했습니다.

단 한 번의 순전파로 수십 페이지를 전사할 수 있는 새로운 OCR 작동 방식을 소개합니다. 참조 슬라이딩 윈도우 어텐션을 활용하여 효율적인 메모리 관리를 구현했습니다.
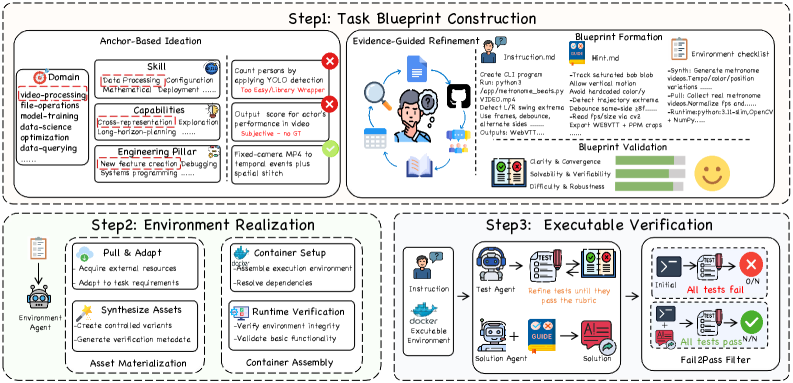
CLI-Universe는 실제 세계의 데이터를 기반으로 검증 가능한 터미널 에이전트 태스크를 생성하는 엔진입니다. 이를 통해 미세 조정된 Qwen3-32B 모델은 적은 데이터로도 대규모 모델을 능가하는 성능을 보여주었습니다.

ICWM은 로봇이 새로운 카메라 환경이나 형태에 즉각 적응할 수 있도록 돕는 인컨텍스트 월드 모델링 기술입니다. 별도의 파인튜닝 없이 단 몇 초간의 상호작용만으로 월드 다이내믹스를 학습하여 제로샷 일반화를 구현합니다.

월드 모델, 비디오 생성, 시각-언어-행동 정책(VLA)을 하나의 체계로 통합하여 분석한 서베이 논문입니다. 예측된 미래를 실제 행동으로 연결하는 100개 이상의 방법론을 구조화된 분류 체계로 제시합니다.