Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 447건필터 해제

Alibaba와 ZJU가 로봇 정책의 성공률을 높이는 경량 플러그인인 VLA-Corrector를 공개했습니다. 이 기술은 시각 역학을 모니터링하여 드리프트 발생 시 즉각적인 재계획을 수행합니다.

Alibaba가 훈련과 추론 사이의 불일치 문제를 해결하기 위한 새로운 강화학습 목적 함수인 MIPI를 소개했습니다. 2단계 MIPU 프레임워크를 통해 추론 정책을 직접 최적화함으로써 LLM 사후 학습의 효율성을 높입니다.

Alibaba Qwen 팀이 VLN, ObjectNav, 트래킹, 자율 주행을 통합 처리하는 2B-8B 규모의 Qwen-RobotNav 모델을 공개했습니다. 에이전트 기반 플래너를 통해 제로샷 방식으로 실제 사족 보행 로봇에 배포가 가능합니다.

PhotoQuilt는 추가 학습 없이 다양한 해상도에서 포토모자이크를 제작하는 기술입니다. 저해상도 레이아웃을 기반으로 FLUX 모델을 사용하여 타일을 업스케일 및 재노이즈하며, 14K 이상의 고해상도에서도 효율적인 확장이 가능합니다.
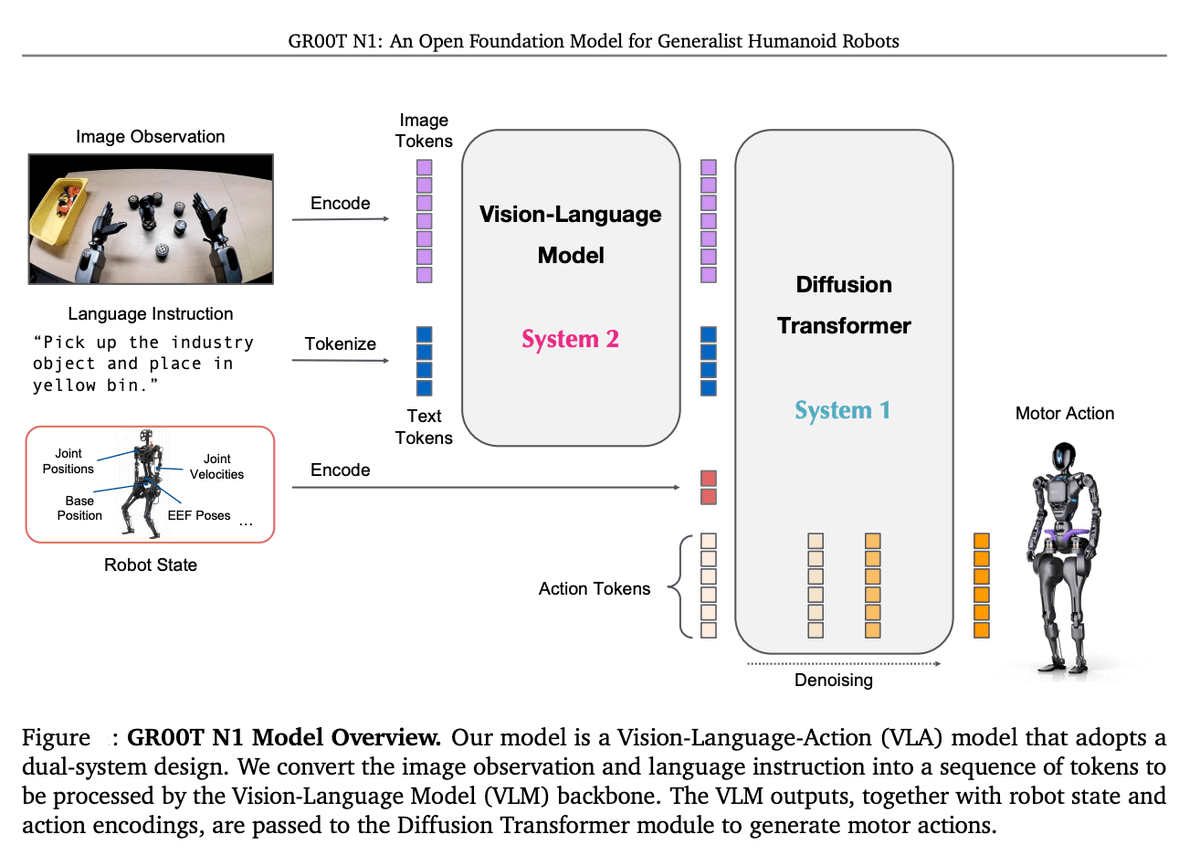
NVIDIA가 Hugging Face를 통해 미세 조정된 GR00T N1.7 로봇 정책을 출시했습니다. 이 모델은 Panda 팔 조작을 위한 LIBERO 벤치마크를 기반으로 학습되었으며, LeRobot을 통해 배포가 가능합니다.

비디오 MLLM의 시간적-논리적 추론 능력을 평가하기 위한 새로운 벤치마크인 Video-MME-Logical을 소개합니다. 테스트 결과 인간과 AI 모델 간의 극심한 성능 격차가 확인되었습니다.

Hugging Face의 이번 주 주요 논문들을 소개합니다. 월드 모델, 에이전트의 절제 능력, 컨테이너 없는 코드 검증 등 최신 AI 연구 트렌드를 다룹니다.

비디오 가이드를 따라 GUI를 조작하는 에이전트를 위한 새로운 벤치마크인 VG-GUI-Bench를 소개합니다. TASKER 기술을 통해 키프레임을 효율적으로 탐색하여 장기 작업 및 VideoQA 성능을 개선합니다.

MrFlow는 추가 학습 없이 확산 모델(diffusion model)의 샘플링 속도를 10배 가속화하는 기술입니다. 단계별 샘플링 대신 단 한 번의 고해상도 단계에서 세부 사항을 정교화하여 효율성을 높였습니다.
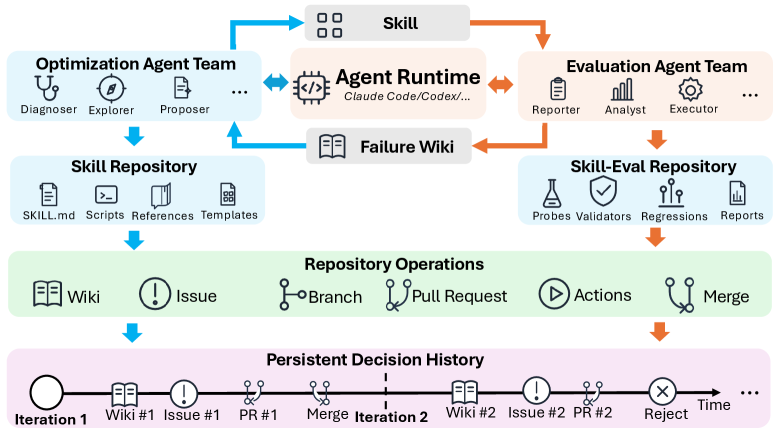
WeChat AI가 지속적인 의사결정 이력을 활용해 에이전트의 기술을 진화시키는 SkillHone 기술을 공개했습니다. 이 기술은 정적 프롬프트 대신 과거의 이력을 기억하여, GAIA 벤치마크에서 기존 상용 딥 리서치 에이전트보다 높은 성능을 기록했습니다.

Alibaba의 Qwen 팀이 로봇 조작의 규모 확장을 위한 VLA 파운데이션 모델인 Qwen-RobotManip를 공개했습니다. 이 모델은 표현, 동작, 행동의 정렬을 통해 약 38,100시간의 오픈 소스 데이터로 학습되었습니다.

AsyncOPD는 온폴리시 증류(on-policy distillation) 과정에서 발생하는 느린 생성 속도를 해결하기 위해 비동기 학습을 연구합니다. 순방향 KL은 오래된 정책 데이터를 처리할 수 있지만 역방향 KL은 실패한다는 점을 밝혀냈으며, 이를 통해 정확도 저하 없이 처리량을 최대 3.8배 향상시킵니다.

EFT(Evolution Fine-Tuning)는 156K의 궤적을 활용해 발견 에이전트의 성능을 진화시키는 학습 방법론입니다. 또한 Tencent Hunyuan은 VQ 토크나이저와 AR 생성기를 공동 학습시켜 이미지 생성 속도를 10배 높인 GEAR 기술을 공개했습니다.
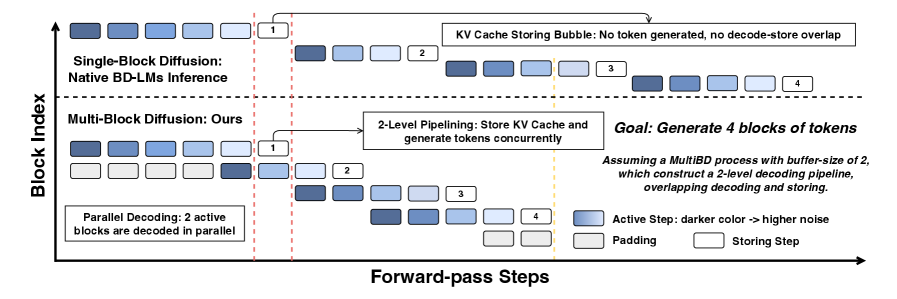
확산 언어 모델(Diffusion LMs)의 병렬 블록 디코딩을 가능하게 하는 사후 학습 레시피인 MBD-LMs를 소개합니다. 이를 통해 모델의 정확도를 높이는 동시에 디코딩 속도를 획기적으로 향상시켰습니다.
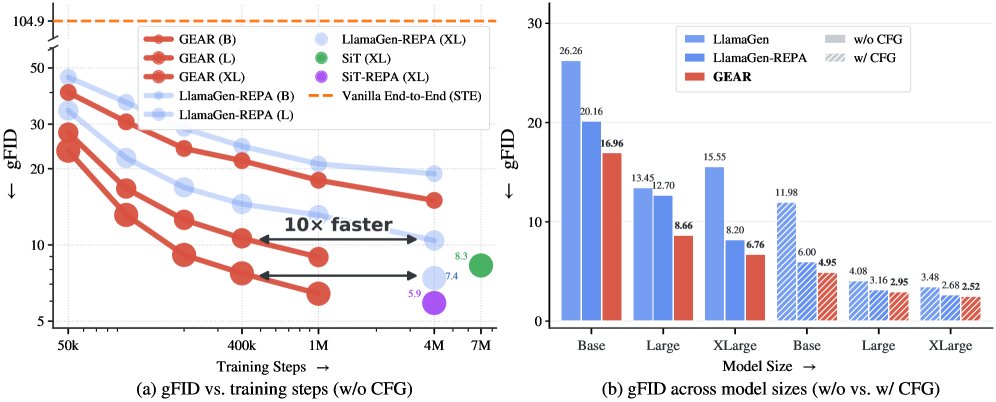
Tencent Hunyuan이 개발한 GEAR는 VQ 토크나이저와 AR 생성기를 엔드투엔드로 공동 학습시켜 기존 LlamaGen-REPA보다 10배 빠른 이미지 생성을 구현합니다. 또한 FlashMorph를 통해 트랜스포머를 하이브리드 어텐션 모델로 변환하여 연산 효율성을 높이는 방법론을 제시합니다.

시각적 월드 모델의 물리적 추론 능력을 평가하기 위한 새로운 벤치마크인 TAILOR을 소개합니다. 일반적인 상황뿐만 아니라 드문 물리적 시나리오와 불가능한 상황을 포함하여 모델의 한계를 테스트합니다.
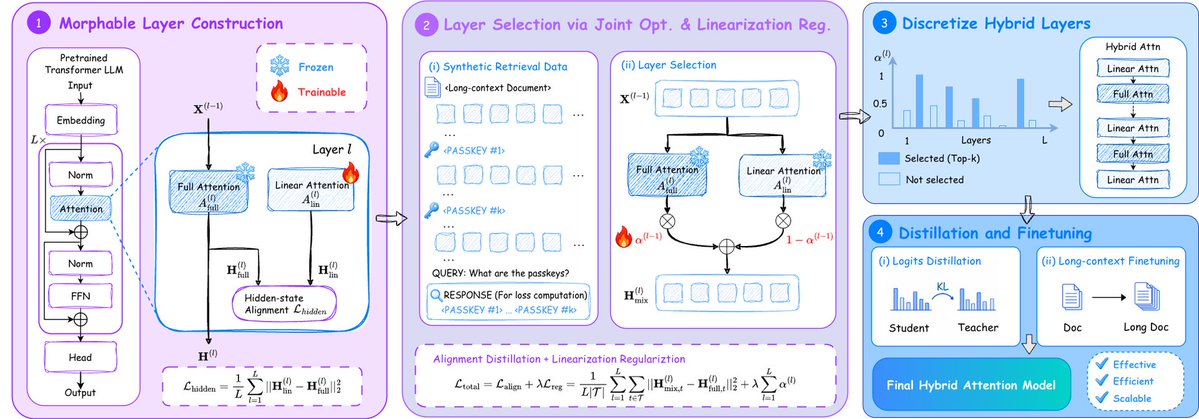
FlashMorph는 사전 학습된 Transformer를 하이브리드 어텐션 모델로 변환하는 기술입니다. 연산량을 줄이면서도 긴 문맥 회상 능력을 유지하기 위해 전체 어텐션과 선형 어텐션 레이어를 효율적으로 선택합니다.

AgenticDataBench는 15개 도메인과 344개의 현실적인 작업을 포함하는 새로운 벤치마크입니다. 97개의 데이터셋과 433개의 데이터 과학 기술을 활용하여 LLM 데이터 에이전트의 성능을 엄격하게 평가합니다.
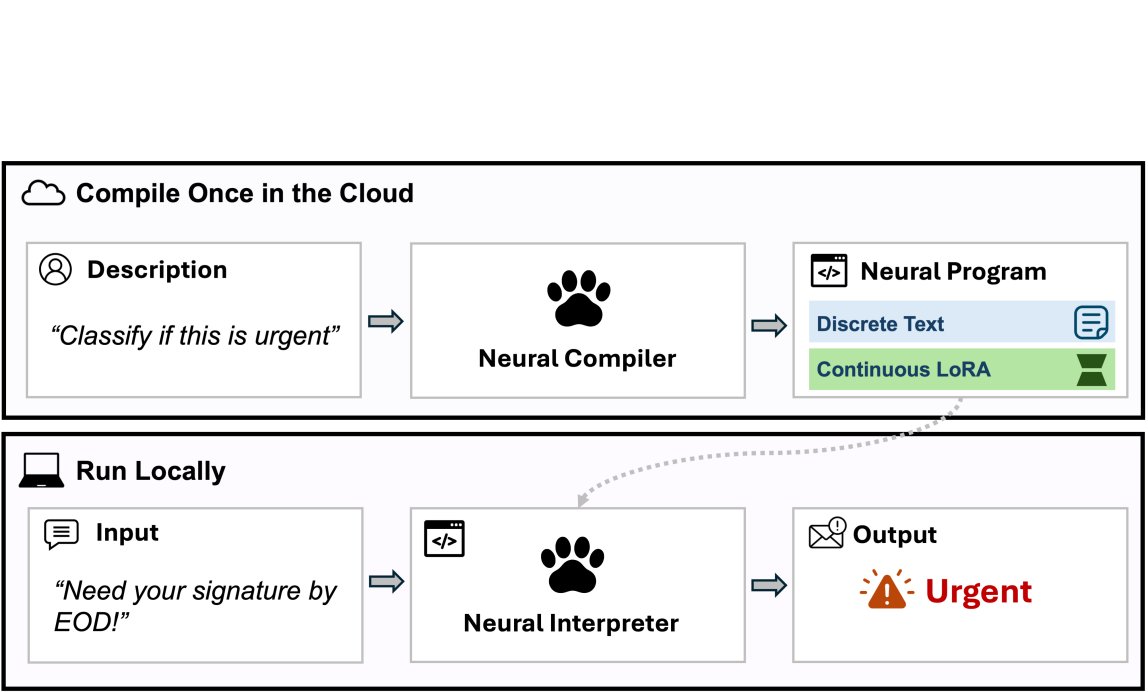
함수를 신경 프로그램(neural program)으로 컴파일하여 실행하는 'Program-as-Weights' 기술을 소개합니다. 0.6B 규모의 인터프리터를 통해 메모리 사용량을 1/50로 줄이면서도 Qwen3-32B와 대등한 성능을 구현했습니다.
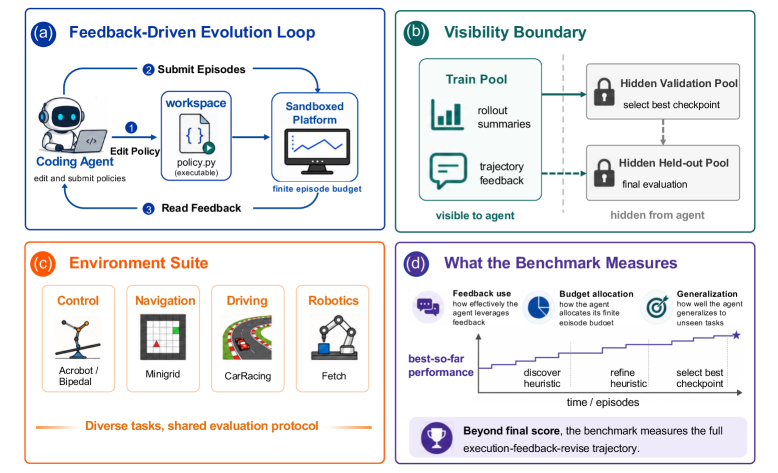
자율적 정책 진화를 평가하기 위한 새로운 벤치마크인 EvoPolicyGym을 소개합니다. 코딩 에이전트가 제한된 예산 내에서 강화학습 환경의 정책을 수정하고 개선하는 과정을 분석합니다.