Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
X @huggingpapers (검증됨) 447건필터 해제

LongE2V는 희소한 이벤트 스트림으로부터 고품질 비디오를 재구성, 예측 및 보간하는 통합 비디오 확산 프레임워크입니다. 이 기술은 긴 시퀀스 처리에 초점을 맞추었으며, Tencent가 출시한 HiLS-Attention 모델은 초장기 컨텍스트 학습을 위한 7B 희소 어텐션 모델입니다.
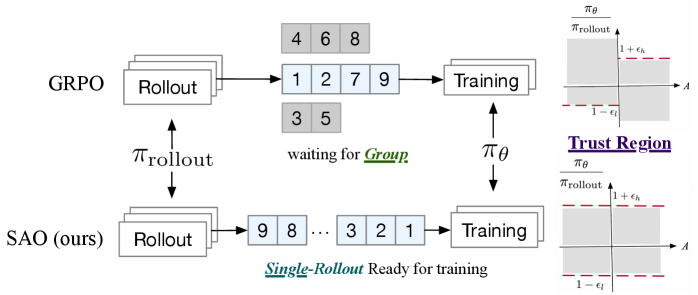
본 기사는 에이전트 학습의 최적화 방안을 제시하며, 그룹별 GRPO를 단일 롤아웃 비동기 업데이트로 대체하는 방법을 설명합니다. 이 방법은 엄격한 더블-사이드 토큰 레벨 클리핑을 통해 1,000 스텝 동안 안정적인 학습이 가능함을 보여줍니다.

LaMem은 로봇 조작을 위해 설계된 잠재 메모리 네이티브 프레임워크입니다. 이 시스템은 과거 경험을 단기 및 장기 메모리에 정리하고, 이를 압축한 잠재 토큰 형태로 VLA(Vision-Language-Action) 추론에 직접 통합합니다.

Ant Group의 Robbyant가 무한 상호작용과 실시간 720p@60fps 생성이 가능한 14B 월드 모델인 LingBot-World 2.0을 출시했습니다. 이 모델은 에이전트 하네스를 갖추어 무한 시뮬레이션 환경을 제공하며, 복잡하고 다재다능한 상호작용 지평을 탐색할 수 있게 합니다.

Google이 다양한 규모(2.3B~31B)의 Open-weight 네이티브 멀티모달 언어 모델인 Gemma 4를 출시했습니다. 이 모델은 Dense 및 MoE 아키텍처, 인코더가 없는 12B 변형, 그리고 추론을 위한 사고 모드 등 여러 특징을 갖추고 있습니다.
LingBot-Video는 Robbyant / Ant Group에서 개발한 오픈 소스 MoE 비디오 모델입니다. 7만 시간 이상의 로봇 데이터와 웹 비디오를 결합하여 학습되었으며, 희소 MoE DiT 구조를 통해 물리적 추론 작업에서 높은 성능을 보였습니다.
Apple이 기계 번역 모델의 환각 발생 시점을 감지할 수 있도록 대규모 데이터셋인 HAT을 공개했습니다. 이 데이터셋은 38개 언어 쌍에 걸쳐 총 35만 개의 스팬 레벨 주석을 포함하고 있습니다.
NVIDIA가 Hugging Face에 nvDock이라는 확산 모델을 출시했습니다. 이 모델은 모든 원자 분자 포켓 도킹 분야에서 새로운 최고 성능(SOTA) 결과를 달성하며, Top-1 정확도 81.85%를 기록했습니다. 또한 SenseNova-Vision 모델은 컴퓨터 비전과 멀티모달 생성을 통합하여 다양한 시각 작업을 단일 모델로 처리할 수 있게 했습니다.
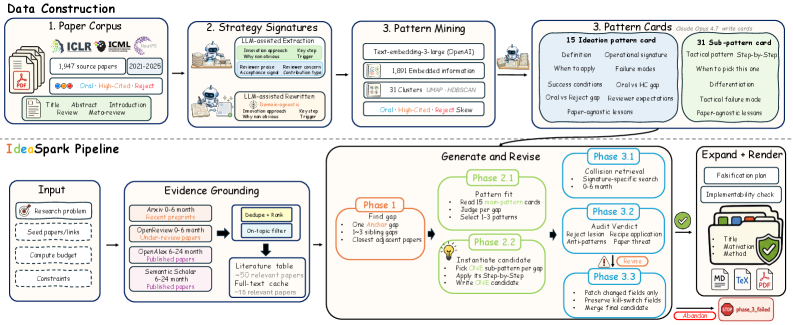
Microsoft가 연구 방향 검토자(reviewer)를 위한 AI 공동 저자인 ResearchStudio-Idea를 출시했습니다. 이 도구는 1,947편의 주요 학회 논문을 기반으로 하며, 문헌 검색, 내용 확인, 위험 감사 기능을 제공합니다. 이를 통해 사용자는 다양한 아이디어 패턴을 추출하여 연구에 활용할 수 있습니다.
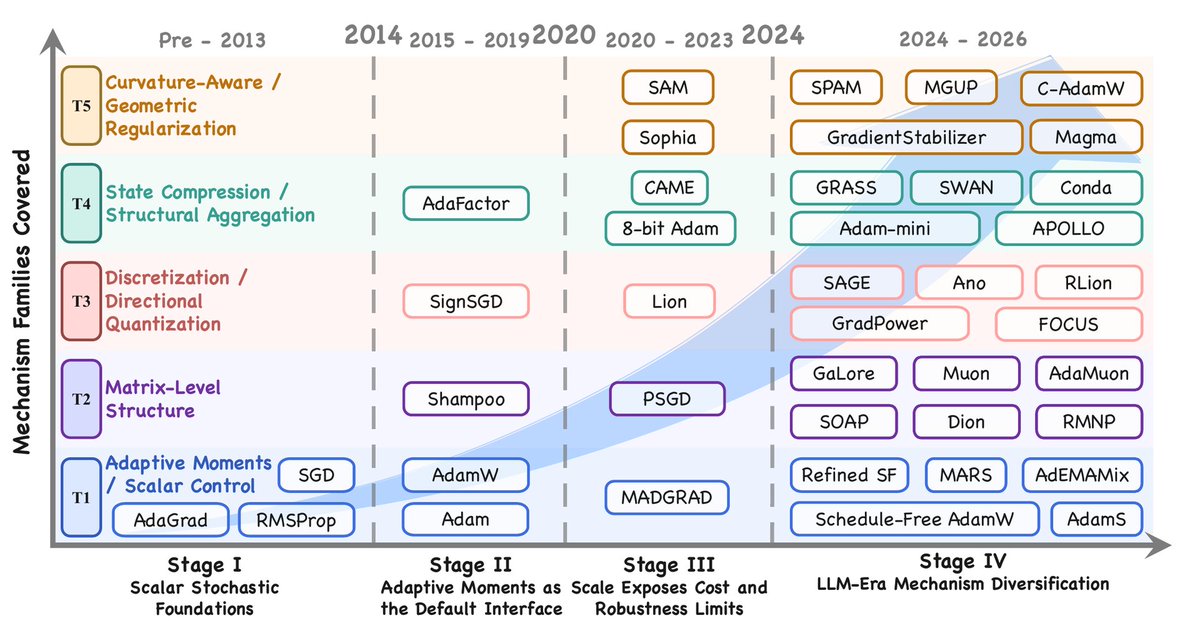
OmniOpt는 현대적 옵티마이저를 위한 통합 분류 체계와 대규모 벤치마크를 제안합니다. 100개 이상의 방법론을 다루며, 60M에서 1B 파라미터 규모의 LLM 사전 학습 과정에서 24개 이상의 옵티마이저를 엄격하게 평가합니다.

NVIDIA가 Hugging Face를 통해 새로운 모델 가중치인 CWIP-1.0을 출시했습니다. PixWorld 기술을 활용하여 픽셀 공간에서 3D 생성과 재구성을 통합하며, 기존 모델보다 최대 1000배 빠른 생성 속도를 자랑합니다.

NVIDIA가 음성, 소리, 추론을 통합 처리하는 30B MoE 모델인 Audex를 Hugging Face에 출시했습니다. 또한 Microsoft는 PDF를 기반으로 비디오와 블로그 등 다양한 콘텐츠를 생성하는 ResearchStudio-Reel을 공개했습니다.
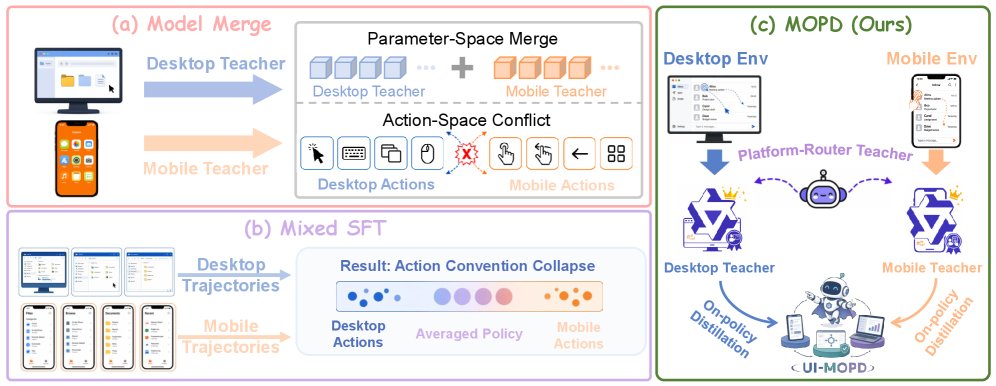
Xiaomi와 Tsinghua 연구진이 멀티 티처 온-폴리시 증류 기술을 적용한 8B GUI 에이전트인 UI-MOPD를 오픈 소스로 공개했습니다. 이 모델은 데스크톱과 모바일 환경 모두에서 뛰어난 성능을 보여줍니다.

Microsoft가 PDF 파일을 기반으로 포스터, 비디오, 블로그, 인터랙티브 릴을 자동 생성하는 ResearchStudio-Reel을 출시했습니다. Claude Code와 Codex 기술을 활용하여 편집 가능한 형태의 결과물을 생성합니다.
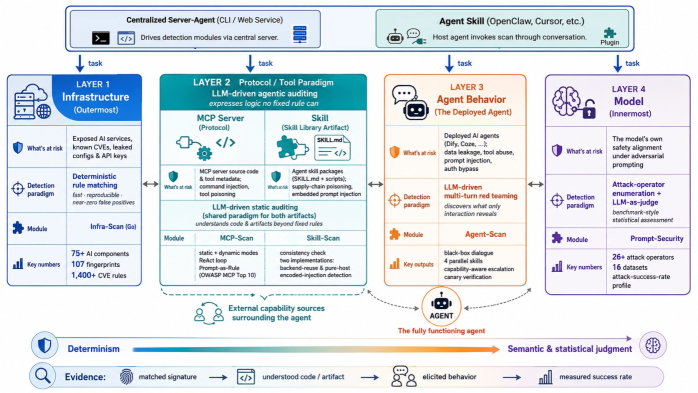
AI-Infra-Guard는 에이전트 스택의 각 레이어에 탐지 패러다임을 매핑하는 오픈 소스 레드 티밍 프레임워크입니다. 인프라, 프로토콜, 행동, 모델을 아우르는 포괄적인 보안 검증을 지원합니다.
NVIDIA가 Hugging Face를 통해 고해상도 기후 시뮬레이션 데이터셋을 공개했습니다. SCREAM 모델 기반의 이 데이터셋은 차세대 기상 에뮬레이터 학습을 목적으로 설계되었습니다.

데이터 중심(data-centric) VLM 학습을 위한 대규모 벤치마크인 DataComp-VLM을 소개합니다. 160개의 데이터셋과 6T 토큰을 활용하여 적절한 데이터 혼합이 필터링보다 성능 향상에 더 효과적임을 입증했습니다.

OrbitQuant는 이미지 및 비디오 확산 트랜스포머(Diffusion Transformers)를 위한 캘리브레이션 프리 PTQ 기술입니다. W4A4 환경에서 SOTA를 달성했으며, 기존 방식이 실패하는 W2A4 환경에서도 이미지 생성이 가능합니다.
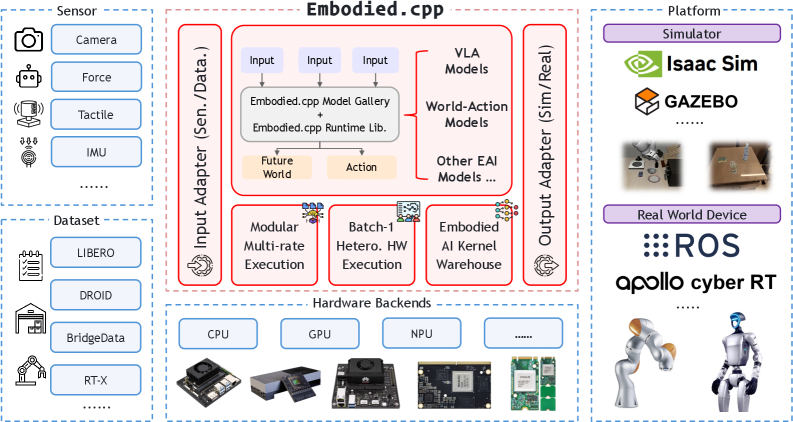
이질적인 로봇 환경에서 동작하는 Embodied AI 전용 C++ 추론 런타임인 Embodied.cpp를 소개합니다. GGUF 가중치를 활용해 엣지 로봇의 CPU, GPU, NPU에서 VLA 및 world-action 모델을 실행할 수 있습니다. 또한 Tencent의 새로운 대규모 MoE 모델인 Hy3의 출시 소식도 포함되어 있습니다.

Tencent이 Hugging Face에 295B MoE 구조의 Hy3 모델을 출시했습니다. 이 모델은 추론, 코딩, 에이전트 분야에서 강력한 성능을 발휘하며 256K의 긴 컨텍스트를 지원합니다.