Insights
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
© 2026 Molayo
AI가 자동으로 큐레이션·번역·정리하는 기술 동향 피드입니다.
본 페이지의 콘텐츠는 AI가 공개된 소스를 기반으로 자동 수집·요약·번역한 것입니다. 원 저작권은 각 원저작자에게 있으며, 각 게시물의 “원문 바로가기” 링크를 통해 원문을 확인할 수 있습니다. 저작권자의 삭제 요청이 있을 경우 신속히 조치합니다.
여러 개의 Claude Code 세션을 효율적으로 관리하기 위해 개발된 Windows용 창 타일링 도구 AgentGrid를 소개합니다. 기존의 통합형 앱 방식과 달리 실제 OS 창을 그리드 형태로 정렬하여 멀티 에이전트 작업 환경을 최적화합니다.
Home Assistant 사용자를 위해 실시간 3D 평면도를 렌더링하는 Sweet Home 3D 플러그인을 소개합니다. 조명 상태와 엔티티 아이콘을 시각화하며 다양한 렌더링 모드를 지원합니다.
Telnyx Call Control과 OpenAI Whisper를 결합하여 실시간 전화 통화 전사 및 AI 응답 파이프라인을 구축하는 방법을 소개합니다. Python 코드를 통해 웹훅 기반의 오디오 처리, 전사, GPT-4 응답 생성 및 TTS 재생 과정을 구현하는 튜토리얼입니다.
Dockerless는 코딩 에이전트가 생성한 코드 패치를 검증할 때 Docker 컨테이너를 통한 테스트 실행 없이 추론만으로 정답 여부를 판단하는 새로운 연구 방법론입니다. 기존의 실행 기반 검증 방식이 가진 높은 비용과 느린 속도 문제를 해결하여 SFT 및 RL 학습에 효율적인 신호를 제공합니다.
macOS 앱 Reel에서 구현된 온디바이스 비디오 노트 구축 과정을 설명합니다. libmpv를 활용한 오디오 추출부터 SpeechAnalyzer를 이용한 전사 및 요약까지, 실제 프로덕션 환경에서의 구현 방법과 주의사항을 다룹니다.
RTX 3090 환경에서 Local LLM인 qwen3-coder:30b와 Claude를 실제 에이전트 작업 성능 및 비용 측면에서 비교 벤치마킹했습니다. 결과적으로 Claude가 품질 면에서 압도적이었으나, qwen은 비용 면에서 약 5,150배 저렴한 경제성을 보였습니다.
Morgan Stanley가 스트레스 테스트 통과 후 배당금 15% 인상과 200억 달러 규모의 자사주 매입 계획을 발표했습니다. 자산 관리 부문의 안정적인 수익 구조를 바탕으로 장기적인 투자 가치를 분석합니다.
Microsoft와 Lightstorm을 포함한 컨소시엄이 인도와 동남아시아를 연결하는 3,600km 규모의 I-2SEA 해저 케이블 구축을 발표했습니다. 이번 프로젝트는 인도의 급성장하는 AI 및 클라우드 인프라 수요를 지원하기 위한 목적으로 추진됩니다.
Guggenheim은 AI가 소프트웨어 산업을 붕괴시킬 것이라는 'SaaS 종말론'에 대해 비관론은 환각에 불과하다고 분석했습니다. 현재 소프트웨어 기업들의 밸류에이션이 과도하게 낮아져 있어, 인내심 있는 투자자들에게는 오히려 매력적인 매수 기회가 될 수 있다고 전망합니다.

Claude Code를 활용하여 학술 논문을 전문적으로 심사할 수 있는 AI-research-feedback 스킬을 소개합니다. 6개의 에이전트가 문법, 논리, 수식 등을 다각도로 점검하며 저널별 맞춤형 시뮬레이션이 가능합니다.
NVIDIA의 Vera Rubin NVL72 랙 스케일 슈퍼컴퓨터를 위한 VR-NVL BMC 디바이스 트리가 Linux 커널에 업스트림되었습니다. 이번 패치는 OpenBMC 지원을 목적으로 하며, ASpeed AST2600 기반 컨트롤러를 사용합니다.

video-spec-builder는 사용자의 모호한 영상 아이디어를 정밀한 스토리보드와 제작 사양서로 구체화하는 스킬입니다. Claude Code나 Codex 환경에서 작동하며, 질문을 통해 아이디어를 구현 가능한 수준까지 정교하게 다듬어줍니다.
이번 주 AI 및 기술 분야의 주요 소식을 요약합니다. Claude의 접근성 확대, NotebookLM의 비디오 요약 기능 추가, OpenAI의 비용 절감 및 GPT-5.6의 생물학 테스트 성공 등 다양한 기술적 진보가 발표되었습니다.

Microsoft가 개발 중인 차세대 운영체제 'Copilot OS(코드명: Aion)'의 유출 정보가 공개되었습니다. 이 OS는 기존 Windows의 인터페이스를 Copilot이 완전히 대체하여, 대화형 인터페이스를 통해 모든 작업을 수행하는 AI-first 환경을 지향합니다.
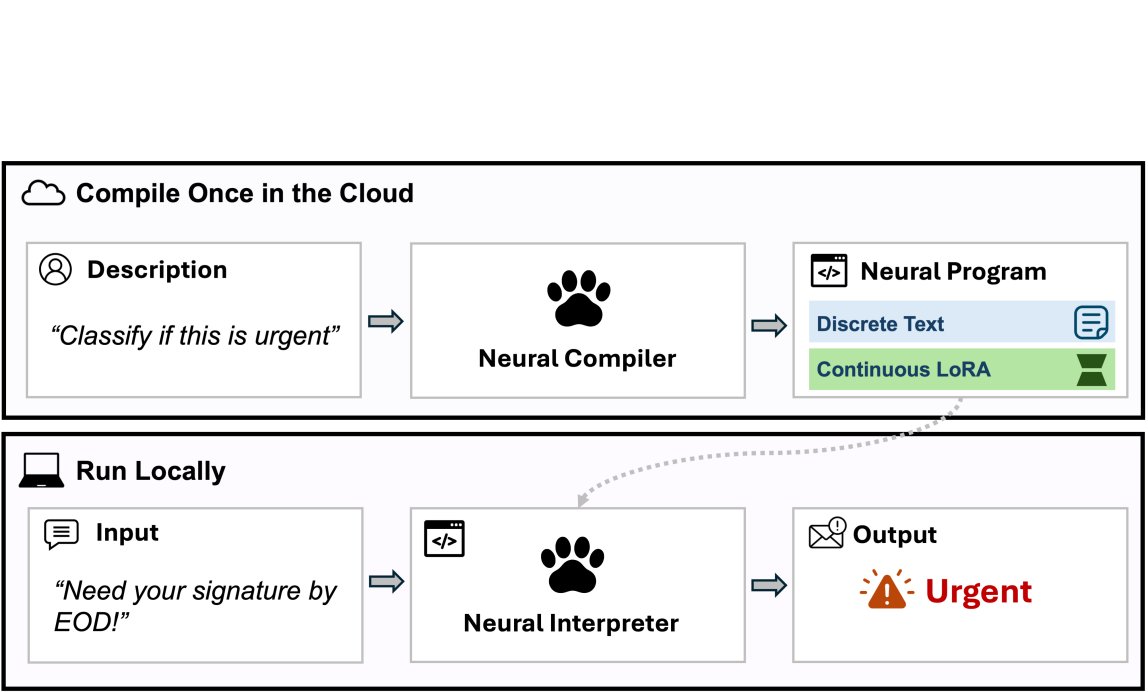
함수를 신경 프로그램(neural program)으로 컴파일하여 실행하는 'Program-as-Weights' 기술을 소개합니다. 0.6B 규모의 인터프리터를 통해 메모리 사용량을 1/50로 줄이면서도 Qwen3-32B와 대등한 성능을 구현했습니다.
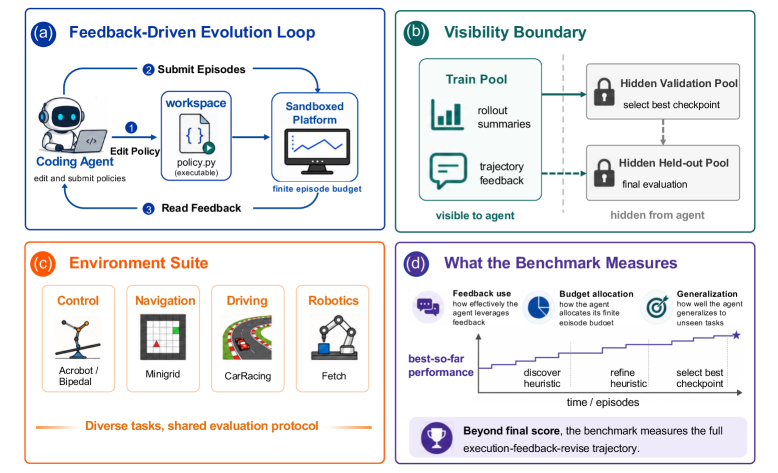
자율적 정책 진화를 평가하기 위한 새로운 벤치마크인 EvoPolicyGym을 소개합니다. 코딩 에이전트가 제한된 예산 내에서 강화학습 환경의 정책을 수정하고 개선하는 과정을 분석합니다.
Anthropic이 Fable 5를 위한 공식 프롬프팅 가이드를 발표했습니다. 핵심은 단순한 프롬프트 작성이 아닌, 루프(loop)를 통한 다단계 자율 작업 수행에 있습니다.

연구진이 가상 회사를 구축하여 AI 에이전트의 업무 수행 능력을 테스트했습니다. 에이전트들은 웹 서핑, 코딩, 협업 등을 수행하며 업무의 30%를 스스로 완료하는 성과를 보였습니다.
B2B 마케팅을 단순한 추측이 아닌 데이터 기반의 엔지니어링 프로세스로 전환하는 방법을 다룹니다. LLM을 활용한 개인화된 콘텐츠 생성과 머신러닝 기반의 예측 리드 스코어링을 결합한 현대적 마케팅 스택 구축 전략을 제시합니다.

소셜 플랫폼 구축 과정에서 발견한 '가짜 인터넷' 생태계의 조직적인 사기 및 봇 유형을 분류한 가이드입니다. 투자 사기, 로맨스 스캠, 딥페이크, 쇼핑 사기 및 각종 봇의 특징과 식별 방법을 정리했습니다.