컨텍스트 엔지니어링 (Context Engineering)을 위한 에이전틱 검색 (Agentic Search)
요약
에이전트의 성능을 결정짓는 핵심 요소인 컨텍스트 엔지니어링의 개념을 정의하고, 기존 RAG의 한계를 극복하기 위한 에이전틱 검색(Agentic Search)의 필요성을 설명합니다.
핵심 포인트
- 컨텍스트 엔지니어링은 LLM의 컨텍스트 윈도우에 들어갈 정보를 결정하는 큐레이션 과정임
- 컨텍스트 엔지니어링의 약 80%는 에이전틱 검색 기술로 구성됨
- 기존 RAG는 단일 검색 방식의 한계로 인해 멀티홉 검색이나 쿼리 수정이 어려움
- 에이전틱 RAG는 검색 도구를 활용해 동적으로 컨텍스트를 확보함
이 포스트는 2026년 4월 8일 런던에서 열린 AI Engineer Europe 2026에서 제가 진행한 “Agentic Search for Context Engineering”이라는 제목의 워크숍을 편집한 긴 버전의 글입니다. 슬라이드, 코드, 다이어그램은 워크숍 저장소(repository)에서 확인할 수 있습니다. 영상이 편하시다면, 전체 녹화본을 YouTube에서 보실 수 있습니다:
이전에 에이전트(agent)를 구축해 본 적이 있다면, 컨텍스트 엔지니어링 (context engineering)이 에이전트가 의미 있는 응답을 반환하도록 만드는 데 매우 중요한 부분이라는 것을 알고 계실 것입니다.
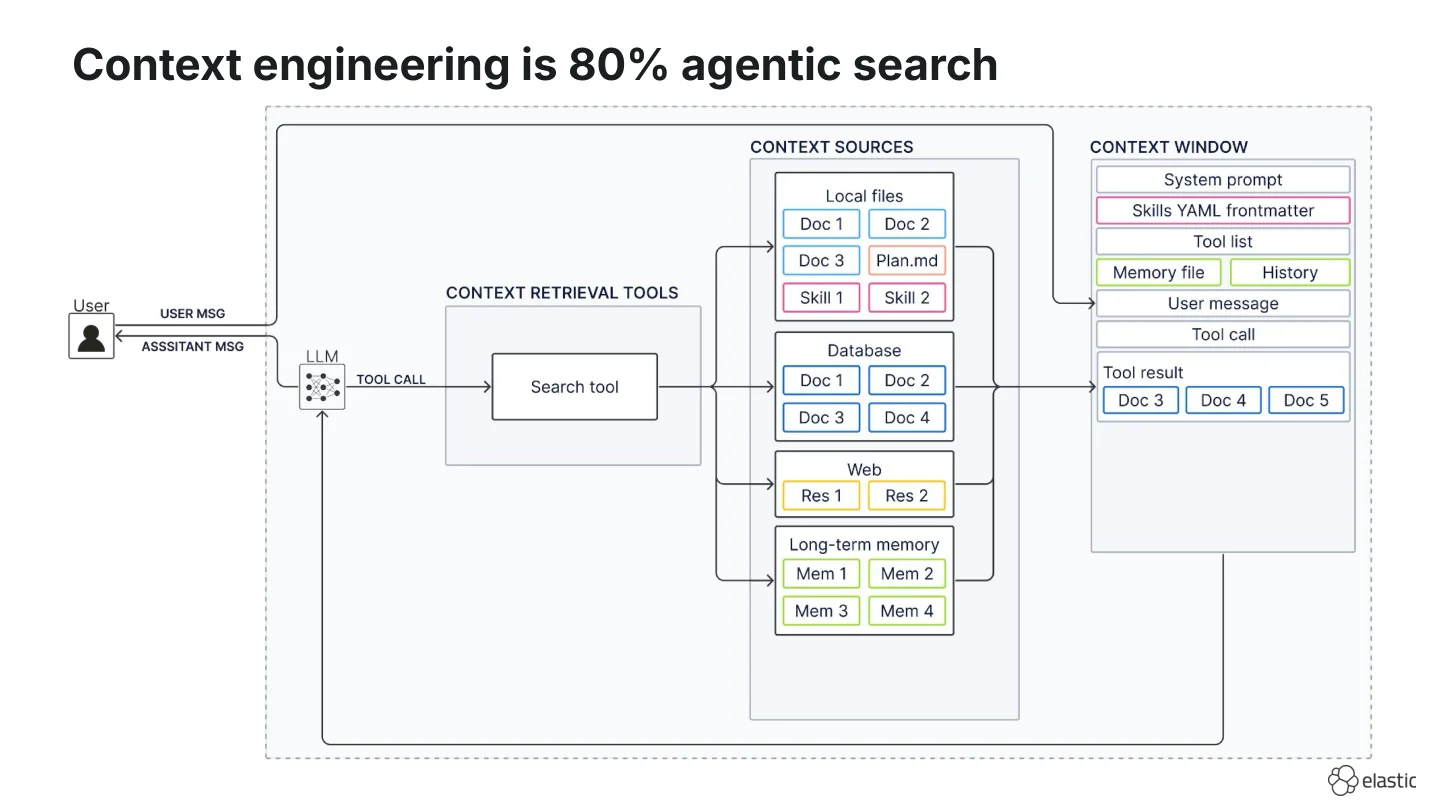
**컨텍스트 엔지니어링 (Context engineering)**은 LLM이 최선의 응답을 생성할 수 있도록 가능한 모든 컨텍스트 소스 중 무엇을 에이전트의 컨텍스트 윈도우 (context window)에 실제로 넣을지 결정하는 과정입니다. 이는 또한 “컨텍스트 큐레이션 (context curation)” 과정이라고도 불리며, 아래 다이어그램에서 가능한 컨텍스트 소스에서 컨텍스트 윈도우로 향하는 화살표로 묘사되어 있습니다.

저는 이 컨텍스트 큐레이션 화살표가 거의 모든 힘든 일을 수행함에도 불구하고 충분한 평가를 받지 못하고 있다고 생각합니다. 그 이면에는 에이전트가 사용하기로 결정할 수 있는 일련의 검색 도구 (search tools)들이 숨겨져 있습니다. 그래서 저의 개인적인 견해는 다음과 같습니다:
컨텍스트 엔지니어링은 약 80%가 에이전틱 검색 (agentic search)입니다.
역사
잠시 뒤로 물러나서, 지난 3년 동안 AI 스택에서의 검색이 검색 증강 생성 (RAG, Retrieval-Augmented Generation)에서 에이전틱 검색/에이전틱 RAG (agentic search/agentic RAG)로, 그리고 이제는 컨텍스트 엔지니어링 (context engineering)으로 어떻게 진화해 왔는지 살펴보겠습니다. (관심이 있으시다면 RAG에서 에이전트 메모리 (agent memory)로의 진화에 대해서도 작성한 글이 있습니다.)
검색 증강 생성 (Retrieval-Augmented Generation)
우리가 2024년에 LLM을 사용하여 구축을 시작했을 때, 우리는 고정된 검색 파이프라인 (retrieval pipelines)을 가진 RAG 시스템을 구현하기 시작했습니다:
- 사용자 메시지가 검색 쿼리 (search query)로서 — 거의 그대로 — 사용됩니다 (종종 벡터 검색 (vector search) 방식).
- 데이터베이스에서 청크 (chunks)를 한 번 가져옵니다.
- 검색된 청크들은 프롬프트 (prompt) 내에서 사용자 메시지와 결합되어 LLM에 전달됩니다.

이 설계는 직관적이며 여전히 좁은 범위의 Q&A에는 작동합니다. 하지만 검색을 정확히 한 번만 수행하기 때문에 예측 가능한 방식으로 한계가 발생합니다:
- 모델이 외부 컨텍스트 (external context)가 필요하지 않은 경우에도 한 번 검색을 수행하며, 관련 없는 청크 (chunks)들이 모델을 혼란스럽게 할 수 있습니다.
- 단 한 번만 검색을 수행하므로 쿼리 (query)를 수정할 선택권이 없습니다. 만약 반환된 결과에 관련 정보가 포함되어 있지 않아 두 번째 검색을 실행해야 한다면 어떻게 될까요?
- 질문이 멀티홉 검색 (multi-hop retrieval)을 필요로 하는 경우에도 단 한 번만 검색합니다. 예를 들어, 첫 번째 청크 묶음은 다음에 무엇을 검색해야 할지만 알려줄 수 있지만, 파이프라인 (pipeline)은 두 번째 패스 (pass)를 절대 실행하지 않습니다.
에이전틱 RAG (Agentic RAG)
이러한 한계점을 극복하기 위해, 우리는 고정된 파이프라인을 검색 도구 (search tool)로 교체하였으며, 이를 “에이전틱 RAG (agentic RAG)”, “에이전틱 검색 (agentic retrieval)”, 또는 “에이전틱 검색 (agentic search)”이라고 불렀습니다. 이 시나리오에서 에이전트 (agent)는 검색 도구를 호출할지 여부, 결과가 관련이 있는지 여부, 더 많은 정보를 검색할지 여부, 그리고 검색 쿼리를 다시 작성할지 여부를 스스로 결정합니다.

많은 설정에서 이는 간단한 작업입니다. 왜냐하면 대개 하나의, 혹은 최소한 제한된 양의 컨텍스트 소스 (context sources)와 하나의 검색 도구만을 가지고 있기 때문입니다.
컨텍스트 엔지니어링 (Context engineering)
컨텍스트 엔지니어링 (context engineering) 단계에서는 이제 다음과 같이 매우 다양한 컨텍스트 소스를 갖게 됩니다:
- 디스크에 있는 로컬 파일 (예: 사용자의 리포지토리 (repo),
plan.md또는todo.md파일이 포함된 스크래치 패드 (scratch pads), 또는 에이전트 스킬 (Agent Skills)) - 데이터베이스 (예: 대규모 엔터프라이즈 데이터 저장)
- 웹 (Web)
- 장기 메모리 (Long-term memory) (메모리가 파일에 저장되는지 데이터베이스에 저장되는지는 여전히 논쟁 중이므로 의도적으로 모호하게 남겨두었습니다)

그리고 컨텍스트 소스에 따라, 우리는 종종 다음과 같은 네이티브 검색 도구 (native search tool)를 가집니다:
- 로컬 파일을 위한 파일 검색 (file search)
- 에이전트 스킬 (Agent Skills)을 위한 스킬 로딩 (skill loading)
- 데이터베이스를 위한 전용 데이터베이스 도구 (시맨틱 검색 (semantic search) 또는 쿼리 실행 (query execution))
- 웹을 위한 웹 검색 (web search)
- 장기 메모리를 위한 메모리 도구 (memory tools)

이것만으로도 충분히 압도적이지 않다면, 이제 우리는 에이전트가 터미널 명령어를 실행할 수 있게 해주는 도구도 갖게 되었습니다. 이 도구는 다양한 이름을 가지고 있습니다: LangChain은 이를 “shell tool”이라 부르고, Anthropic은 “bash tool”, OpenClaw는 “exec tool”이라고 부릅니다. 다음부터는 이를 **“shell tool”**이라고 부르겠습니다.
shell tool은 대부분의 컨텍스트 소스(context sources)와 상호작용할 수 있기 때문에 매우 다재다능한 도구입니다. 로컬 파일(ls, grep), 데이터베이스(CLI, 스크립트, HTTPS API를 위한 curl), 그리고 웹(curl)을 대상으로 실행할 수 있습니다.

이것이 바로 현재 shell tool이 에이전트에게 필요한 전부인지에 대해 많은 논의가 이루어지고 있는 이유입니다. 이 논의에 대해 더 깊이 파고들고 싶다면, 제가 작성한 “The shell tool is not a silver bullet for context engineering”이라는 제목의 블로그 글을 참고하시기 바랍니다. 해당 블로그의 요약(TLDR)이자 이 워크숍의 핵심 주제는, 실질적인 질문은 'shell tool 대 다른 모든 것'이 아니라 **'어떤 검색 도구들이 당신의 스택(stack)에 포함되어야 하는가'**라는 점입니다.
이 워크숍에서 단 한 가지만 얻어가신다면, 바로 이것이었으면 합니다:
훌륭한 검색을 수행하는 것은 어렵습니다. 그렇기 때문에 수많은 다양한 검색 기술이 존재하며, 여러분이 지연 시간(latency)과 품질 요구 사항에 맞춰 스택을 큐레이션(curate)하는 것입니다.
이 워크숍에서는 검색 도구들의 장단점에 대한 직관을 제공하기 위해 소수의 검색 도구들을 살펴보겠습니다.
검색 도구 구축의 기본 원리
구체적인 검색 도구들을 살펴보기 전에, 효과적인 검색 도구를 구축하기 위한 몇 가지 기본 원리를 검토해 보겠습니다.
에이전틱 검색 (Agentic Search)의 과제
이론적으로 에이전틱 검색은 간단해 보입니다:
- 사용자가 요청을 보냅니다.
- 에이전트가 적절한 매개변수(parameters)와 함께 올바른 도구를 호출합니다.
- 도구가 검색 결과(search results)를 반환합니다.
- 에이전트가 정확한 답변으로 응답합니다.
하지만 현실에서는 다양한 방식으로 문제가 발생할 수 있습니다. Elastic에서는 팀들이 Elasticsearch 데이터를 기반으로 에이전트를 구축하도록 돕고 있으며, 저희가 관찰한 가장 흔한 세 가지 실패 모드(failure modes)는 다음과 같습니다:
- 에이전트가 도구를 전혀 호출하지 않고 파라메트릭 지식(parametric knowledge)으로 답변합니다.
- 에이전트가 잘못된 도구를 호출합니다 (예: 회사 인덱스 대신 웹 검색 호출).
- 에이전트가 잘못된 매개변수로 올바른 도구를 호출합니다.

이러한 문제들을 극복하기 위한 몇 가지 일반적인 모범 사례(Best Practices)를 논의해 보겠습니다. 이를 통해 다음 섹션에서 제가 직접 시연할 때 무엇을 해야 할지에 대한 직관을 얻으실 수 있을 것입니다. 더 많은 모범 사례에 관심이 있으시다면, Elastic에서 효과적인 데이터베이스 검색 도구(Database Retrieval Tools)를 구축하며 배운 내용에 대해 작성한 가이드도 참고해 보시기 바랍니다.
도구 설명 (Tool descriptions)
저는 이 슬라이드를 좋아하지 않는데, 그 이유는 도구 설명(Tool description)이 모든 도구에서 가장 중요한 부분이라는 점을 누구나 이미 알고 있다고 느끼기 때문입니다. 하지만 도구 설명을 볼 때마다 노력이 거의 들어가지 않은 한 줄짜리 설명뿐인 경우를 자주 보게 되고, 왜 에이전트가 이를 사용하는 데 실패하는지 의아해하는 상황을 목격하기 때문에 빠르게 복습해 드리고자 합니다.

인정하건대, 이 템플릿은 상당히 깁니다. 제가 항상 이 템플릿을 따라야 한다고 말하는 것은 아닙니다. 대신, 명확한 핵심 목적(Core purpose)과 트리거 조건(Trigger conditions)부터 시작하세요. 그러다 에이전트가 도구를 사용하는 데 어려움을 겪는 것이 관찰되면, 동작(Actions), 관계(Relationships), 제한 사항(Limitations), 예시(Examples)와 같은 템플릿의 구성 요소들을 추가하기 시작하십시오.
만약 그래도 충분하지 않다면, 시스템 프롬프트(System prompt)에 동일한 규칙을 반복하십시오.
매개변수 복잡성 (Parameter complexity)
주의해야 할 또 다른 측면은 매개변수 복잡성입니다. 일단 올바른 도구가 선택되고 나면, 에이전트는 여전히 인자(Arguments)를 채워 넣어야 하는데, 어떤 인자들은 다른 것들보다 정확하게 입력하기가 더 쉽기 때문입니다.
예를 들어, get_customer_by_id 도구의 매개변수는
ID가 메시지에 포함되어 있을 때는 쉽습니다. 또는 검색 쿼리로 어떤 문자열이든 받는 시맨틱 검색(Semantic search) 도구는 대개 문제가 없습니다. 하지만 필터(Filters)나 top_k와 같은 매개변수를 추가하기 시작하면, LLM이 유효한 매개변수를 생성하는 것이 더 어려워질 수 있습니다. 그런데 만약 에이전트가 매개변수로 완전한 SQL 또는 ES|QL 쿼리를 처음부터 작성할 수 있게 하는 범용 검색 도구를 가지고 있다면 어떨까요? 대부분의 모델은 유효한 SQL 쿼리를 생성하는 데 어느 정도 능숙하지만, 이는 실패의 위험을 높입니다.

코드 워크스루 (Code walkthrough)
실제 검색 도구 구현 사례를 몇 가지 살펴보겠습니다. (모두 보여드리고 싶지만, 아쉽게도 시간이 제한되어 있습니다.) 전체 코드는 워크숍 리포지토리(repository)에서 확인하실 수 있습니다.
이 코드 워크스루(Code walkthrough)에서는 LangChain을 오케스트레이션(orchestration) 도구로 사용합니다. LangChain은 많은 복잡성을 추상화하여 우리가 상위 수준의 개념에 집중할 수 있게 해주며, 쉘 도구(shell tool) 및 기타 유용한 기능들을 기본적으로 제공하기 때문입니다.
데모를 위해, 우리는 AI Engineer Europe 2026 일정 데이터셋을 검색 대상으로 사용합니다.
처음 두 데모는 로컬 Elasticsearch 클러스터를 사용하며, 이는 start-local 스크립트를 사용하여 실행할 수 있습니다. 세 번째 데모는 디스크에서 동일한 데이터를 읽어옵니다. 검색 도구의 핵심 메커니즘에 집중하기 위해, 정확한 데이터 준비 및 인제스션(ingestion) 단계는 건너뛰겠습니다. 해당 단계는 00_prepare_data.ipynb 노트북에서 확인 가능합니다.
바닐라 에이전틱 검색 (Vanilla agentic search)
먼저 첫 번째 노트북인 01_vanilla_agentic_search.ipynb에 구현된 최소한의 바닐라 에이전틱 검색(vanilla agentic search) 설정을 다시 복습해 보겠습니다. 이는 세션당 하나의 문서를 포함하는 conference_schedule 인덱스에 대한 하나의 시맨틱 검색(semantic search) 도구로 구성됩니다.

먼저, 모든 에이전트의 핵심인 LLM을 설정합니다. 여기서는 LiteLLM을 통해 gpt-5.4-nano를 사용합니다:
from langchain_openai import ChatOpenAI
= ChatOpenAI(
llm =LITELLM_API_BASE,
...
그 다음, 에이전트에게 자신이 검색 에이전트라는 점, 언제 정보를 검색해야 하는지, 그리고 인덱스가 어떤 구조로 되어 있는지를 알려주는 최소한의 시스템 프롬프트(system prompt)를 정의합니다:
You are a search agent tasked with answering questions about the AI Engineer Europe 2026 Conference.
You have access to different context retrieval tools to help you answer user queries.
Before answering a question decide whether or not you need to retrieve additional context to answer the question correctly.
...
다음으로, Elasticsearch 클라이언트를 준비합니다. 이를 위해 검색 시점에 쿼리를 임베딩(embedding)할 jina-embeddings-v5-text-small을 임베딩 모델(embedding model)로 준비하고, 우리의 ElasticsearchStore에 연결합니다.
from langchain_community.embeddings import JinaEmbeddings
from langchain_elasticsearch import ElasticsearchStore
= JinaEmbeddings(
...
이제 흥미로운 부분이 나옵니다. 검색 쿼리(search query)를 입력받아 시맨틱 검색 (semantic search)을 수행하고 상위 3개의 결과를 반환하는 검색 도구(search tool)를 정의해 보겠습니다.
LangChain의 @tool 데코레이터 (decorator)를 사용하면 어떤 Python 함수든 에이전트 도구 (agent tool)로 변환할 수 있으며, 기본적으로 함수의 이름을 도구 이름으로, 독스트링 (docstring)을 설명으로 사용합니다.
아래에서 볼 수 있듯이, 저는 여기서 짧은 독스트링만 사용하고 있기 때문에 위에서 언급했던 도구 설명에 대한 제 권장 사항을 이미 어겼습니다. 하지만 이 경우에는 도구가 하나뿐이고 일반적인 데모 사용 사례이므로 이것으로 충분합니다.
from langchain.tools import tool
@tool()
def semantic_search_conference_sessions(query: str) -> str:
...
이제 AI 에이전트 (AI agent)를 구성하는 모든 구성 요소가 준비되었습니다 (보통 "메모리 (memory)"도 포함되지만, 여기서는 검색 도구에 집중하기 위해 의도적으로 생략했습니다). 우리가 해야 할 일은 이들을 서로 연결하는 것뿐입니다.
from langchain.agents import create_agent
= create_agent(
agent =llm,
...
시맨틱 검색 쿼리의 예로 *“Which sessions discuss regulatory constraints in AI systems?” (어떤 세션이 AI 시스템의 규제 제약 사항을 논의하나요?)*를 입력하면, 에이전트는 이제 도구를 호출하여 주권 제약 조건 하에서의 AI 엔지니어링에 관한 Bilge Yücel의 강연을 정확하게 찾아냅니다.
================================ Human Message =================================
Which sessions discuss regulatory constraints in AI systems?
================================== Ai Message ==================================
...
이 지점이 대부분의 에이전틱 검색 (agentic search) 데모가 멈추는 곳입니다.
그리고 바로 이 지점부터 흥미로워지기 시작합니다.
시맨틱 검색 (semantic search) 도구를 기반으로 구축된 이 데모를 깨뜨리기 위해 당신이 해야 할 일은, 시맨틱 검색보다 키워드 기반 검색 (keyword-based search)이 더 적합한 질문을 던지는 것뿐입니다. 예를 들어, 제가 *“GEPA에 대해 더 자세히 배우려면 어떤 세션에 참석해야 하나요?”*라고 묻는다면, 시맨틱 검색은 관련 없는 세션들을 반환하며, Samuel Colvin이 진행하는 올바른 세션을 찾아내지 못합니다.
================================ Human Message =================================
Which sessions should I visit to learn more about GEPA?
================================== Ai Message ==================================
...
범용 데이터베이스 검색 도구를 활용한 에이전틱 검색 (Agentic search)
AI 자동 생성 콘텐츠
본 콘텐츠는 Lobste.rs AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기